

Подходы к автоматизации индексирования.
В основе одних технологий лежат статистические методы, в основе других – различные машинные словари. Наиболее весомые слова по значимости встречаются чаще. На этой гипотезе строится класс систем автоматического индексирования. Алгоритм высчитывает весовые характеристики для каждого термина, ориентируясь на частоту встречаемости. В зависимости от значимости термина происходит включение или невключение его в ПОД.
Второй подход базируется на заранее составленных машинных словарях (фильтрах). Фильтры бывают положительные (для реализации требуется тезаурус, в ПОД включаются только те термины, которые совпадают с терминами тезауруса) и отрицательные (основаны на предварительной разработке словаря запрещённых терминов).
Методика индексирования зависит от того, на каком языке осуществляется индексирование.
Системы кодирования.
Тесно связаны с языковыми средствами и с системой индексирования. В процессе кодирования объектам по определённым правилам присваивают кодовые обозначения. Они определяются алфавитом кода, а структура кода определяется основанием кода и его длиной.
Существует 2 различных подхода к формированию основания кода.
1. Регистрационный – полностью идентифицирует объект, но не содержит никакой информации об объекте в коде.
2. Классификационная система кодирования – обладает ограниченными возможностями идентификации, но содержит информацию об объекте в коде.
Регистрационная система бывает порядковая (базируется на последовательной, порядковой регистрации объектов) и серийно-порядковая (выделяется диапазон серий порядковых номеров для групп сходных объектов). Классификационная система несёт максимум информации об объекте. Она может быть последовательной (значение показателя зависит от значений показателей предыдущих разрядов кодового обозначения, код любой нижестоящей группировки образуется путём добавления существующих разрядов кода вышестоящей группировки) и параллельные (применяется в фасетных языках). Суть параллельных систем – они характеризуются независимым кодированием отдельных признаков, значение показателя каждой части кодового обозначения не зависит друг от друга.
Любая система кодировки должна иметь способы защиты.
Оценка эффективности поиска.
Для того, чтобы оценить эффективность АИС существует ряд категорий показателей.
-
стоимостной показатель
-
с
 емантические
показатели (позволяют оценить систему
как систему для обработки информации.
емантические
показатели (позволяют оценить систему
как систему для обработки информации.
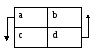
a – релевантно выданные документы
b – нерелевантно выданные
c – релевантные невыданные
d – невыданные нерелевантные
Таблицы сопряжённости поиска:
Полнота поиска = a/a+c
Точность поиска = a/a+b
Коэффициент корелляции поиска = ad – bc / √ (a+c)(b+d)(d+c)(a+b).
Энтропийный показатель основывается на том, что измеряется допоисковая энтропия и послепоисковая, и её изменение позволяет судить о том, насколько эффективно сумела произвести поиск система.
Организация информационных массивов.
-
пассивный (массив третьего контура) – хранятся оригиналы документов
-
слабоактивный – в упорядоченном виде содержатся краткие содержания документов
-
активный (первый контур) – содержатся поисковые образы документов. Это есть непосредственно БД. Информационный поиск проводится в этой массивов.
-
Запись информации по полям (наименование единицы данных – поле)
-
Запись – поименованная совокупность полей.
-
Файл – поименованная совокупность экземпляров записей одного типа
-
Набор файлов
Схема записи – совокупность имени записи и имён, составляющих её поля.
В основе различных схем БД лежат различные (конкретные) схемы файлов, записей, связей между ними.
Прямая запись (записи в массиве упорядочены по какому-либо идентификатору – по вертикали, по горизонтали – дескрипторы, участвующие в ПОДах) и инверсная (в качестве исходной записи выступают дескрипторы, в клетках – номера документов, в которые входит этот дескриптор).
В чистом виде ни прямая, ни инверсная схемы не используются, чаще используют комбинированную схему, где один файл построен по прямой, а другой – по инверсной схеме.