

"Автоматизированная обработка текстов на ЕЯ" 1. Знаковые системы: определение, формализованное описание знаковой системы, типология знаковых систем. 2. Устройство ЕЯ как знаковой системы. 3. Значение когнитивной психологии и структурной лингвистики для автоматизированной обработки текстов на ЕЯ. 4. Лингвистическая парадигма Н. Хомского и основные положения теории Н. Хомского. 5. Модель понимания текстов Кинча. 6. Принципы структуризации текстов на основе трансформационной грамматики. 7. Принципы морфологического, синтаксического и семантического анализа в модели «Смысл-текст». 8. Требования к моделям представления знаний в ЭВМ. 9. Обобщенная характеристика модели представления знаний в ЭВМ. 10. Принципы построения систем машинного перевода на примере известной Вам системы.
Обработка текстов на естественном языке
Задачи обработки текстов возникли практически сразу вслед за появлением вычислительной техники. Но несмотря на полувековую историю исследований в области искусственного интеллекта, огромный скачок в развитии ИТ и смежных дисциплин, удовлетворительного решения большинства практических задач обработки текста пока нет.
Компьютерная лингвистика — раздел науки, изучающий применение математических моделей для описания лингвистических закономерностей. Ее можно разделить на две большие части. Одна из них изучает способы применения вычислительной техники в лингвистических исследованиях — применение известных математических методов (например, статистическая обработка) для выявления закономерностей. Обнаруженные закономерности используются другой частью, изучающей вопросы осмысления текстов, написанных на естественном языке, — создание математических моделей для решения лингвистических задач и разработка программ, функционирующих на основе этих моделей. Эта часть компьютерной лингвистики тесно соприкасается с разделом искусственного интеллекта, занимающегося разработкой систем обработки текстов на естественном языке.
Общая схема обработки текстов (рис. 1) инвариантна по отношению к выбору естественного языка. Независимо от того, на каком языке написан исходный текст, его анализ проходит одни и те же стадии. Первые две стадии (разбиение текста на отдельные предложения и на слова) практически одинаковы для большинства естественных языков. Единственное, где могут проявиться специфичные для выбранного языка черты, - это обработка сокращений слов и обработка знаков препинания (точнее, определение того, какие из знаков препинания являются концом предложения, а какие нет).
|
|
|
Рис. 1. Общая схема обработки текста |
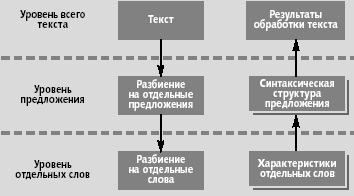
Последующие две стадии (определение характеристик отдельных слов и синтаксический анализ), напротив, сильно зависят от выбранного естественного языка. Последняя стадия (семантический анализ) также мало зависит от выбранного языка, но это проявляется только в общих подходах к проведению анализа.
Семантический анализ основывается на результатах работы предыдущих фаз обработки текста, которые всегда специфичны для конкретного языка. Следовательно, способы представления их результатов тоже могут сильно варьироваться, оказывая большое влияние на реализацию методов семантического анализа. Результаты анализа, произведенного на ранних стадиях, могут быть многозначны: для выходных параметров указывается не одно, а сразу несколько возможных значений (скажем, может существовать несколько способов трактовки одного и того же слова). В таких случаях последующие стадии должны выбирать наиболее вероятные значения результатов ранних стадий анализа и уже на их основе проводить дальнейший анализ текста.
Рассмотрим детальнее каждую из стадий анализа текста после разделения текста на отдельные слова и предложения. К первой стадии (анализ отдельных слов) относится морфологический анализ (определение морфологических характеристик каждого слова — часть речи, падеж, склонение, спряжение и т.д.) и морфемный анализ (приставка, корень, суффикс и окончание); ко второй стадии — синтаксический анализ; к третьей — различные задачи семантического анализа (поиск фрагментов, формализация, реферирование и т.д.).
Анализ отдельных слов
В эту стадию обработки входят морфологический и морфемный анализы слов. Входным параметром является текстовое представление исходного слова. Целью и результатом морфологического анализа является определение морфологических характеристик слова и его основная словоформа. Перечень всех морфологических характеристик слов и допустимых значений каждой из них зависят от естественного языка. Тем не менее, ряд характеристик (например, название части речи) присутствуют во многих языках. Результаты морфологического анализа слова неоднозначны, что можно проследить на множестве примеров.
Существует три основных подхода к проведению морфологического анализа. Первый подход часто называют «четкой» морфологией; для русского языка он основан на словаре Зализняка [1]. Второй подход основывается на некоторой системе правил, по заданному слову определяющих его морфологические характеристики; в противоположность первому подходу его называют «нечеткой» морфологией [2]. Третий, вероятностный подход, основан на сочетаемости слов с конкретными морфологическими характеристиками [3]; он широко применяется при обработке языков со строго фиксированным порядком слов в предложении и практически неприменим при обработке текстов на русском языке. Рассмотрим все три способа морфологического анализа подробнее.
Словарь Зализняка содержит основные словоформы слов русского языка, для каждой из которых указан определенный код. Известна система правил, с помощью которой можно построить все формы данного слова, отталкиваясь от начальной словоформы и соответствующего ей кода. Помимо построения каждой словоформы, система правил автоматически ставит в соответствие ей морфологические характеристики. При проведении четкого морфологического анализа необходимо иметь словарь всех слов и всех словоформ языка. Этот словарь на входе принимает форму слова, а на выходе выдает его морфологические характеристики. Данный словарь можно построить на основе словаря Зализняка по очевидному алгоритму: перебрать все слова из словаря, для каждого из них определить все возможные их словоформы и занести их в формирующийся словарь.
|
|
|
Рис. 2. Морфологический анализ на основе словаря Зализняка |
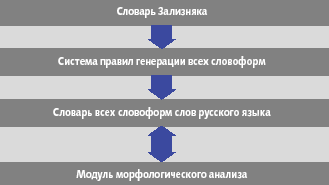
При таком подходе для проведения морфологического анализа заданного слова (рис. 2) необходимо просто найти его в словаре, где уже хранятся точные, «окончательно известные» значения всех его морфологических характеристик. Для одного и того же входного слова могут встретиться сразу несколько вариантов значений его морфологических характеристик.
К сожалению, этот способ применим не всегда: слова, поступающие на вход, могут не входить в словарь всех словоформ. Такая ситуация может возникнуть из-за ошибок ввода исходного текста, из-за наличия в тексте имен собственных и т.д. В случае, когда метод не дает нужного результата, применяется нечеткая морфология.
|
|
|
Рис. 3. Морфемный анализ |

Целью морфемного анализа слова является разделение слова на приставки, корни, суффиксы и окончания (рис. 3). В словаре морфем русского языка [4, 5] указано разделение каждого слова на отдельные части, но не указаны типы каждой из них — какая из них является приставкой, какая корнем и т.д. Множество всех корней слов русского языка открыто, но множество всех возможных приставок, суффиксов и окончаний ограничено; кроме того, известно, что в любом слове сначала идут приставки, затем корни, далее суффиксы и окончания. Поэтому на основе словаря морфем русского языка можно построить другой словарь, который будет содержать не только разбиение каждого слова на части, но и тип каждой из них. В таком случае, для проведения морфемного анализа слова необходимо обратиться к этому словарю.
Морфемный анализ не ограничивается обращениями к словарю. В ситуации, когда слово отсутствует в словаре, возможно непосредственное проведение анализа на основе стандартного строения слов русского языка (приставка — корень — суффикс — окончание) и множества всех приставок, суффиксов и окончаний.
Вернемся к морфологическому анализу слова в той ситуации, когда не удалось определить характеристики слова с помощью методов четкой морфологии, но удалось расчленить его на части. Наличие тех или иных лексем может определять морфологические характеристики слова: можно построить систему правил, которая будет опираться на наличие или отсутствие каких-либо частей и выдавать одно или несколько предположений о морфологических параметрах. Такой набор правил можно построить двумя способами. Первый основан на морфемном анализе слов, содержащихся в словаре всех словоформ, и их морфологических характеристик. Рассмотрим эту задачу формальнее: известны пары значений, состоящие из морфемного строения слова и его морфологических характеристик. Это есть не что иное, как «вход» и «выход» системы правил, которая по морфемному строению слова будет определять его морфологические характеристики. Задачу построения такой системы правил можно решить с помощью самообучающейся системы (рис. 4). Для ее реализации могут быть использованы деревья решений, программирование на основе индуктивной логики (ILP, Inductive Logic Programming) или другие алгоритмы.
|
|
|
Рис. 4. Нечеткий морфологический анализ |

Второй подход состоит в формировании набора правил вручную. По большому счету, его реализация — ничто иное, как написание экспертной системы диагностирующего типа.
Вероятностный способ [6] проведения морфологического анализа слов состоит в следующем. Одна и та же словоформа может принадлежать сразу к нескольким грамматическим классам. Для каждой словоформы определяются все ее грамматические классы, а также вероятность ее отношения к каждому из этих классов. Это выполняется на основе некоторого набора документов, где каждому слову предварительно поставлен в соответствие грамматический класс. После этого вычисляются вероятности сочетаний определенных грамматических классов для слов, стоящих рядом — для двоек, троек, четверок и т.д. На основе этих чисел может проводиться анализ слов, но для него необходимо уже не только само слово, но и стоящие рядом с ним слова.
Необходимо сделать два важных замечания. Во-первых, вероятностный метод применим только для тех языков, у которых четко фиксирован порядок слов в предложении. Если же порядок слов можно изменять, то все возможные сочетания грамматических классов будут практически равновероятны. Во-вторых, если первые два способа анализа (четкая и нечеткая морфология) на входе принимают отдельные слова, то вероятностный способ, напротив, на входе принимает либо все предложение, либо, по крайней мере, несколько стоящих рядом слов.