

big_doc_LKG
.pdf вибрати змінні для побудови регресії. Максимальна кількість змінних для розрахунку не повинна перевищувати
вибрати змінні для побудови регресії. Максимальна кількість змінних для розрахунку не повинна перевищувати  вибрати залежну та незалежні змінні. Система STATISTICA після перетворення компонентів нелінійної регресії у відповідності з вказаною функцією натурального логарифму додає до списку змінних їх перетворення. Для нашого прикладу вікно вибору залежної та незалежних змінних має наступний вигляд
вибрати залежну та незалежні змінні. Система STATISTICA після перетворення компонентів нелінійної регресії у відповідності з вказаною функцією натурального логарифму додає до списку змінних їх перетворення. Для нашого прикладу вікно вибору залежної та незалежних змінних має наступний вигляд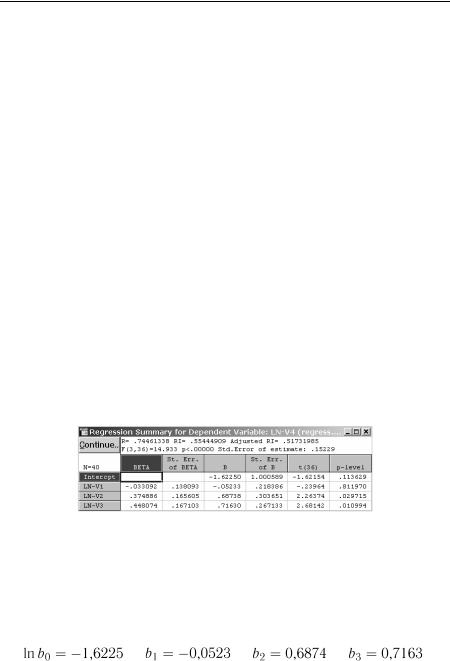
Апроксимація зв’язків багатофакторними регресійними моделями 349
До початкового списку з чотирьох змінних система додала чотири їх перетворення. Тобто, наприклад, значення змінної LN–V1 є значеннями логарифмів змінної Х1. Зауважимо, що у лівому списку залежних змінних можна вибирати декілька змінних. При побудові степеневої та показникової моделей необхідно вибирати замість залежної змінної Y її логарифмічне перетворення (у нашому випадку LN–V4).
Устепеневій залежності замість незалежних змінних Х1, Х2,…, Хn слід вказати їх логарифмічні перетворення (у нашому випадку відпові-
дно LN–V1, LN–V2, LN–V3).
Упоказниковій залежності незалежні змінні у відповідності до рівняння (7.43) використовуються без перетворення, тобто у правому списку незалежних змінних слід вибрати їх дійсні значення (у нашому прикладі Х1, Х2 та Х3);
5) після вибору залежної та незалежних змінних у діалоговому вікні MODEL DEFINITION – ВИЗНАЧЕННЯ МОДЕЛІ (рис. 7.7) слід вказати, чи необхідно включити до моделі вільний член у списку натиснути кнопку INTERCEPT – ВІЛЬНИЙ ЧЛЕН (рис. 7.8) та натиснути кнопку ОК;
6) викликавши вікно з електронною таблицею результатів розрахунку коефіцієнтів регресії аналогічно вищеописаному для лінійної моделі перейти від перетворених коефіцієнтів регресії до дійсних. Розглянемо порядок визначення дійсних коефіцієнтів регресії за степеневою та показниковою моделями для нашого прикладу.
Вікно результатів розрахунку коефіцієнтів регресії для степеневої моделі показане на рис. 7.13.
Рис. 7.13. Результати розрахунків коефіцієнтів регресії за степеневою моделлю
Таким чином, коефіцієнти при перетворених змінних у лінійованому рівнянні степеневої регресії (7.28) мають наступні значення (стовпчик В таблиці результатів на рис. 7.13):
; |
; |
; |
. |

 ;
;  ;
;  ;
;  .
. .
. ;
;  ;
;  ;
;  .
. ;
;  ;
; ;
;  .
. .
.
Апроксимація зв’язків багатофакторними регресійними моделями 351
7.4.3. Оцінка якості регресійних залежностей. Якість побудова-
них рівнянь регресії можна оцінити за допомогою розрахункових показників, до яких відносяться:
–коефіцієнт множинної кореляції (позначається як MULTIPLE R чи просто R);
–коефіцієнт множинної детермінації (позначається як R2 чи RI);
–стандартна помилка оцінювання регресії (позначається як STAN-
DARD ERROR OF ESTIMATE чи STD. ERROR OF ESTIMATE).
Результати розрахунку цих показників виводяться в процесі побудови регресійної моделі у верхній частині діалогового вікна MULTIPLE
REGRESSION RESULTS – РЕЗУЛЬТАТИ МНОЖИННОЇ РЕГРЕСІЇ (рис. 7.5)
та дублюються у верхній частині вікна результатів розрахунків коефіцієнтів регресії (рис. 7.6).
Регресійна модель буде кращою серед декількох розглянутих, якщо їй відповідають більші значення коефіцієнтів множинної кореляції та множинної детермінації та менші значення стандартної помилки оцінювання регресії.
7.4.3.1. Оцінка значимості рівняння та факторів регресії. Для перевірки значимості рівняння регресії та адекватності рівняння регресії вихідним даним використовується  -критерій Фішера (F). Розрахунковий критерій Фішера виводиться у правому стовпчику верхньої частині діалогового вікна MULTIPLE REGRESSION RESULTS – РЕ-
-критерій Фішера (F). Розрахунковий критерій Фішера виводиться у правому стовпчику верхньої частині діалогового вікна MULTIPLE REGRESSION RESULTS – РЕ-
ЗУЛЬТАТИ МНОЖИННОЇ РЕГРЕСІЇ (рис. 7.5) та для нашого прикладу дорівнює  .
.
Нижче значення F виводиться кількість ступенів вільності меншої дисперсії та кількість ступенів волі більшої дисперсії (рядок DF). У нашому прикладі відповідно 3 та 36.
Ще нижче виводиться гранична імовірність прийняття гіпотези про адекватність регресійної моделі вихідним даним (у нашому прикладі p=0,000004).
У випадку, коли розрахункове значення граничної імовірності прийняття гіпотези про адекватність регресійної моделі вихідним даним не перевищує вибраний рівень значимості регресійна модель вважається значимою та адекватною вихідним експериментальним (статистичним) даним.
Для розглянутого прикладу при рівні значимості 0,05 лінійну множинну регресійну модель можна вважати значимою та адекватною ви-
хідним даним, так як p=0,000004 < 0,05.

 обновити підсвічення значимих факторів для щойно встановленого рівня значимості.
обновити підсвічення значимих факторів для щойно встановленого рівня значимості.
 – А
– А – Г
– Г
 – Г
– Г
Апроксимація зв’язків багатофакторними регресійними моделями 355
7.4.3.3. Розрахунок кореляційної матриці. Розрахунок кореляцій-
ної матриці дає можливість виявити, так звані, мультиколінеарні фактори, тобто пари факторів, між якими існує значимий кореляційний зв’язок (один фактор залежить від другого чи навпаки). Кореляційна матриця є квадратною та містить стільки рядків та стовпчиків, скільки незалежних змінних міститься у рівнянні регресії.
Для побудови кореляційної матриці слід натиснути у вікні MULTIPLE REGRESSION RESULTS – РЕЗУЛЬТАТИ МНОЖИННОЇ РЕГРЕСІЇ (рис.
9.5) кнопку  – КОРЕЛЯЦІЙНІ ТА ОПИСОВІ СТАТИС-
– КОРЕЛЯЦІЙНІ ТА ОПИСОВІ СТАТИС-
ТИКИ, після чого на екрані з’явиться діалогове вікно REVIEW DESCRIPTIVE STATISTIC – ПЕРЕГЛЯД ОПИСОВИХ СТАТИСТИК (рис. 7.20).
Рис. 7.20. Діалогове вікно описових статистик
Надалі у цьому вікні слід натиснути кнопку  – КОРЕЛЯЦІЯ. Вікно результатів розрахунку кореляційної матриці для вихідних даних нашого прикладу наведене на рис. 7.21.
– КОРЕЛЯЦІЯ. Вікно результатів розрахунку кореляційної матриці для вихідних даних нашого прикладу наведене на рис. 7.21.
Рис. 7.21. Кореляційна матриця
Значимі коефіцієнти кореляції підсвічуються червоним кольором на рівні значимості 0,05.

Апроксимація зв’язків багатофакторними регресійними моделями 357
Приклад 2. Проведені дослідження на трьох однотипних вантажних пунктах металургійного комбінату дали підстави стверджувати, що величина  загального прос-
загального прос-
тою вагонів на комбінаті залежить від таких, апріорі вибраних, факторів:
 – сумарної кількості вагонів, що надходять в систему за добу;
– сумарної кількості вагонів, що надходять в систему за добу;
 – частки вантажів, що надходять в критих вагонах;
– частки вантажів, що надходять в критих вагонах;
 – частки вантажів, що надходять в піввагонах;
– частки вантажів, що надходять в піввагонах;
 – інтервалів між черговим прибуттям вагонів;
– інтервалів між черговим прибуттям вагонів;
 – коефіцієнта завантаження транспортної системи.
– коефіцієнта завантаження транспортної системи.
В табл. 7.3 наведені статистичні дані спостережень, зібрані на трьох однотипних вантажних пунктах.
Таблиця 7.3
Дані статистичних спостережень
|
|
|
Пункт 1 |
|
|
|
|
Пункт 2 |
|
|
|
Пункт 3 |
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
1 |
120 |
39 |
0,40 |
0,60 |
2,4 |
2,67 |
210 |
10 |
0,21 |
0,79 |
1,3 |
0,68 |
562 |
17 |
0,16 |
0,84 |
3,8 |
1,88 |
2 |
671 |
16 |
0,21 |
0,79 |
2,3 |
1,10 |
396 |
7 |
0,58 |
0,42 |
9,5 |
0,48 |
262 |
10 |
0,62 |
0,38 |
6,3 |
0,75 |
3 |
1119 |
19 |
0,35 |
0,65 |
4,5 |
1,30 |
498 |
17 |
0,35 |
0,65 |
3,0 |
1,16 |
434 |
17 |
0,10 |
0,90 |
3,8 |
1,33 |
4 |
742 |
22 |
0,15 |
1,00 |
4,0 |
1,50 |
651 |
15 |
0,13 |
0,87 |
3,8 |
1,00 |
638 |
9 |
0,33 |
0,67 |
3,8 |
0,68 |
5 |
651 |
15 |
0,58 |
0,42 |
4,3 |
1,00 |
420 |
20 |
0,38 |
0,62 |
3,3 |
1,37 |
203 |
4 |
0,59 |
0,41 |
11,0 |
0,30 |
6 |
482 |
14 |
0,21 |
0,79 |
2,7 |
0,96 |
815 |
18 |
0,12 |
0,88 |
2,3 |
1,23 |
312 |
8 |
0,52 |
0,48 |
3,5 |
0,60 |
7 |
151 |
5 |
0,57 |
0,43 |
6,0 |
0,34 |
413 |
13 |
0,13 |
0,87 |
4,4 |
0,89 |
357 |
8 |
0,21 |
0,79 |
4,8 |
0,60 |
8 |
367 |
14 |
0,21 |
0,79 |
3,6 |
0,96 |
493 |
10 |
0,12 |
0,88 |
4,3 |
0,68 |
120 |
7 |
0,58 |
0,42 |
6,3 |
0,53 |
9 |
714 |
20 |
0,37 |
0,63 |
3,0 |
1,37 |
567 |
22 |
0,15 |
0,85 |
3,2 |
1,65 |
337 |
8 |
0,37 |
0,63 |
3,0 |
0,60 |
10 |
505 |
6 |
0,12 |
1,00 |
5,3 |
0,41 |
859 |
20 |
0,06 |
0,94 |
3,6 |
1,37 |
625 |
14 |
0,32 |
0,68 |
5,7 |
1,10 |
11 |
484 |
5 |
0,48 |
0,52 |
2,0 |
0,34 |
422 |
10 |
0,08 |
1,00 |
4,6 |
0,60 |
662 |
34 |
0,28 |
0,72 |
3,3 |
2,56 |
12 |
126 |
5 |
0,69 |
0,31 |
5,3 |
0,34 |
1016 |
23 |
0,16 |
0,84 |
4,0 |
1,57 |
802 |
15 |
0,43 |
0,57 |
5,7 |
1,13 |
13 |
564 |
13 |
0,12 |
0,88 |
4,5 |
0,89 |
638 |
24 |
0,50 |
0,50 |
2,4 |
1,81 |
253 |
5 |
0,48 |
0,52 |
3,0 |
0,38 |
14 |
497 |
17 |
0,30 |
0,70 |
4,3 |
1,16 |
494 |
13 |
0,22 |
0,78 |
5,3 |
0,98 |
483 |
13 |
0,26 |
0,74 |
4,0 |
0,38 |
15 |
429 |
10 |
0,19 |
0,81 |
5,7 |
0,68 |
580 |
7 |
1,00 |
0,20 |
2,0 |
0,54 |
781 |
16 |
0,20 |
0,80 |
3,8 |
1,20 |
16 |
396 |
14 |
0,21 |
0,79 |
5,0 |
0,96 |
474 |
15 |
0,31 |
0,69 |
3,2 |
1,88 |
|
|
|
|
|
|
17 |
240 |
6 |
0,45 |
0,55 |
13,0 |
0,41 |
576 |
17 |
0,19 |
0,81 |
3,3 |
1,28 |
|
|
|
|
|
|
18 |
|
|
|
|
|
|
546 |
12 |
0,16 |
0,84 |
2,0 |
0,96 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Необхідно побудувати багатофакторну регресійну модель процесу переробки вагонів на металургійному комбінаті.