

Kluwer - Handbook of Biomedical Image Analysis Vol
.2.pdf734 |
Kallergi, Heine, and Tembey |
Table 13.2: Feature set selected from the shape analysis of the segmented individual calcifications and clusters and demographic dataa
Feature No. |
Feature |
Nature of feature |
|
|
|
1 |
Age of the patient |
Demographic feature; |
|
|
describes the patient |
Individual calcification characteristics |
|
|
2 |
Mean—Area of calcification |
Describes the morphology (shape) |
3 |
Mean—Compactness |
|
4 |
Mean—Moments |
|
5 |
Mean—Fourier Descriptor (FD) |
Describes the margins |
6 |
Mean—Eccentricity |
|
7 |
Mean—Spread (S) |
|
8 |
Number of calcifications in cluster |
Regional descriptor; |
|
(median of range) |
describes distribution |
Cluster characteristics |
|
|
9 |
SD—Area |
Describes the morphology |
10 |
SD—Compactness |
|
11 |
SD—Moments |
|
12 |
SD—Fourier Descriptor |
Describes the margins |
13 |
SD—Eccentricity |
|
14 |
SD—Spread |
|
|
|
|
a Features are limited to morphological and distributional characteristics (with the exception of “age”) in order to reproduce the visual analysis system and indirectly use the classification as a measure of segmentation.
13.5 Classification Algorithm
Classification was done with a three-layer, feed-forward artificial neural network (ANN) consisting of an input layer, one hidden layer, and an output layer. The NevProp4 backpropagation software was used in this study. NevProp4 is a general backpropagation algorithm developed by Philip H. Goodman at the University of Nevada, Reno [60]. Figure 13.15 shows a diagram of the network structure.
The feature vector of the input layer consisted of 14 elements (features) defined in the previous stage (Table 13.2) and a bias element [60]. The hidden layer consisted of 12 nodes and the output layer had one node. For each cluster, the network was given the set of shape features at its input layer, merged these inputs internally using the hidden and output layers, and assigned a value in the range of 0–1, where 0 was the target output for the benign cases and 1 was the

Computer-Aided Diagnosis of Mammographic Calcification Clusters |
735 |
||||
F1 |
I1 |
|
|
|
|
|
|
H1 |
|
|
|
F2 |
I2 |
|
|
|
|
|
|
H2 |
|
|
|
F3 |
I3 |
|
|
Percent |
|
|
|
H3 |
O |
likelihood of |
|
F4 |
I4 |
: |
|
malignancy |
|
Output layer |
|
|
|||
|
: |
: |
|
|
|
|
|
|
|
||
|
: |
|
|
|
|
|
: |
|
|
|
|
|
|
|
|
|
|
: H12
H12
F14 I14
I14
Input layer |
Hidden layer |
Figure 13.15: Diagram of the NevProp4 artificial neural network (ANN) used for cluster classification. This is a standard three-layer, feed-forward ANN where F1–F14 are the input features, I1–I14 are the input units, H1–H12 are the hidden units, and O is the output layer [20, 59, 60].
target output for the cancer cases. This value could be interpreted as a percent likelihood for a cluster to be malignant.
The generalization error of the ANN classifier was estimated by the “leave- one-out” resampling method [61, 62]. Leave-one-out is a method generally recommended for the validation of pattern recognition algorithms using small datasets. The use of this approach usually leads to a more realistic index of performance and eliminates database problems such as small size and not fully representative contents and problems associated with the mixing of training and testing datasets [61, 63]. In the leave-one-out validation process, the network was trained on all but one of the cases in the set for a fixed number of iterations and then tested on the one excluded case. The excluded case was then replaced, the network weights were reinitialized, and the training was repeated by excluding a different case until every case had been excluded once. For N cases, each exclusion of one case resulted in N–1 training cases, 1 testing case and a unique set of network weights. As the process was repeated over all N, there were N(N−1) training outputs and N testing outputs from which the training and testing mean square error (MSE) was, respectively, determined.
In addition to the leave-one-out method, other resampling approaches have been proposed for CADiagnosis algorithm training that could yield unbiased
736 |
Kallergi, Heine, and Tembey |
results and provide meaningful and realistic estimates of performance. A preference toward the bootstrap technique is found in the literature although this is strongly dependent on the application and availability of resources [64]. There is considerable work reported in the field and we will not elaborate more in this chapter. The reader, however, should be aware of the bias issues associated with large feature sets and small sample sizes and the possible methods of training and testing an algorithm. An approach should generally be selected that yields no overestimates of performance and avoids training bias.
The clinical value of CADiagnosis methods is usually assessed in two stages: First, computer performance is evaluated based on truth files defined by the experts and biopsy information using computer generated receiver operating characteristic (ROC) curves [65, 66]. Computer ROC is implemented in the evaluation of classification algorithms where sensitivity and specificity indices are generated by adjusting the algorithms’ parameters. Classification algorithms differentiate usually between benign vs. cancer lesions, disease vs. not disease, disease type 1 vs. disease type 2, etc. The pairs of sensitivity and specificity generated by these algorithms can be plotted as a true positive fraction (TPF) vs. false positive fraction (FPF) to form an ROC curve [65]. Publicly available software tools, e.g., the ROCKIT from Metz at the University of Chicago [67], may be used to fit the data and estimate performance parameters such as the area under the curve, AZ , its standard error (SE), confidence intervals, and statistical significance.
Following the laboratory evaluation, a true ROC experiment is usually performed that involves relatively large number of cases and human observers [68]. The cost and time requirements of an observer ROC study are significant impediments in its implementation and such analysis is usually reserved for fully optimized techniques, namely for techniques that have been through rigorous computer ROC evaluation. Computer ROC evaluation poses specific requirements on database size and contents and the criteria used for the estimation of TPF and FPF values at the detection or the classification level. We will not labor on these issues in this chapter; guidelines may be found in several publications in the field of CAD and elsewhere [65, 69, 70]. We will only mention that a sufficiently large set should be selected for CADiagnosis validation to meet the requirements of the classification scheme, while the contents of the dataset should be such as to address the specific clinical goals of the methodology. In addition, performance criteria should follow clinical guidelines and
Computer-Aided Diagnosis of Mammographic Calcification Clusters |
737 |
be consistently and uniformly applied throughout the validation process. In the CADiagnosis algorithm applications presented below, equal numbers of benign and malignant cases with calcification clusters were used and almost all cluster shapes described in the BIRADS Lexicon [71] were represented in the sets. Performance parameters such as number of TP and FP clusters at the segmentation output or TPF and FPF at the classification output were estimated based on well-defined criteria that were consistently applied to all experiments.
13.6 CADiagnosis Algorithm Applications
Several applications of the algorithm described here have been reported in the literature [20, 28, 29]. In this chapter, we summarize the most important ones, report on new experiments that are linked to segmentation issues and reveal some of the open questions remaining in this area.
13.6.1Mammographic Cluster Classification—Single View Application
A set of 260 single-view mammograms with calcification clusters was first used for the validation of the CADiagnosis algorithm described previously. The set included 138 calcification clusters associated with benign disease that are commonly referred to as benign calcifications or clusters and 122 calcification clusters associated with cancer that are commonly referred to as malignant calcifications or clusters. All mammograms were selected from the patient files of the H. Lee Moffitt Cancer Center & Research Institute at the University of South Florida. Original mammograms were acquired on two different mammography systems, both accredited by the American College of Radiology (ACR) and having similar performances. A DuPont Microvision film combined with a Kodak Min-R (one-sided) screen was used for all mammograms. Films were digitized with a DBA (DBA Inc., Melbourne, FL) ImagClear R3000 CCD-based film digitizer with a pixel size of 30 m, a pixel depth of 16 bits, and a nonlinear response to optical density [72]. Full images were resized to 60 m by mathematical interpolation keeping the pixel depth the same. For this application, 512 × 512 pixel ROIs were processed. ROIs were selected from the full 60 m images to contain the calcification cluster of interest.
738 |
Kallergi, Heine, and Tembey |
Mammographic views were either cranio-caudal (CC) or medio-lateral oblique (MLO) views of the right of left breast. Two hundred two (202) views from this set were images of the same cluster that is they were CC and MLO views of the same breast and the same patient. For this application, however, they were considered as independent samples. This is common practice in the field not only because of the rarity of the data but also because most CADetection schemes today are applied to single views only and do not usually consider the full mammogram or the “other” breast view in the process. A bias is certainly expected when views from the same patient and of the same cluster are treated as independent samples and this bias could affect performance. This is investigated in the following application example described in section 13.6.2.
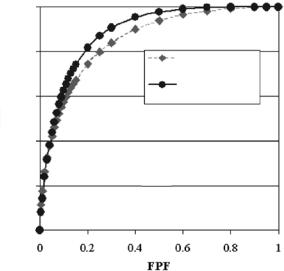
The CADiagnosis scheme of Fig. 13.3 was applied to the set of 260 ROIs first using the symmlet wavelet filter and then using the donut filter in the detection/segmentation stage. The computer ROC curves obtained from the two classification experiments are shown in Fig. 13.16. The corresponding AZ performance index values and standard errors (SE) are included on the figure. The difference between the two curves was statistically significant indicat-
1.0
0.8
|
|
|
|
Symmletl t Waveletl t |
|
|
|
|
|
|
Az=0..86;; SE=0..02 |
|
|
0.6 |
|
|
|
Donutt Filterilt |
|
|
|
|
|
Az=0..89;; SE=0..02 |
|
||
TPF |
|
|
|
|
|
|
0.4 |
|
|
|
|
|
|
0.2 |
|
|
|
|
|
|
0.0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0 |
0.2 |
0.4 |
0.6 |
0.8 |
1 |
|
|
|
|
FPF |
|
|
Figure 13.16: Computer ROC plots of the TPF and FPF pairs obtained from the classification of 260 clusters. The dashed curve corresponds to the results obtained with the symmlet wavelet filter and the solid curve corresponds to the results obtained with the donut filter. The estimated area indices AZ and corresponding SE values are included in the insert.
Computer-Aided Diagnosis of Mammographic Calcification Clusters |
739 |
ing that cluster classification using the donut filter in the detection and segmentation stage was significantly better than classification using the symmlet wavelet.
13.6.2Mammographic Cluster Classification—Two-View Application
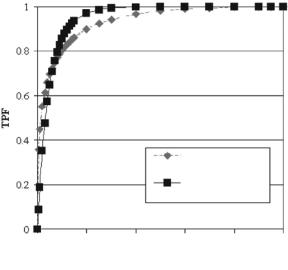
In this application of the algorithm, the two views of the same cluster were combined for the selection of the classification features [59]. A total of 101 paired clusters were available for this test. The 14 features of Table 13.2 were first determined on the 101 CC and 101 MLO views of the cluster and then averaged. The set of average feature values were then used as input to the classification stage of the algorithm (Fig. 13.3). The computer generated ROC curves of the classification performance of the algorithm obtained with the symmlet wavelet and the donut filter are shown in Fig. 13.17. Similar to the previous experiment, the classifier with the donut filter outperformed the classifier with the
1 |
|
|
|
|
|
|
0.8 |
|
|
|
|
|
|
0.6 |
|
|
|
|
|
|
TPF |
|
|
|
|
|
|
0.4 |
|
|
|
|
|
|
|
|
|
|
Symmlet Wavelet |
|
|
|
|
|
|
Az=0.93; SE=0.02 |
|
|
0.2 |
|
|
|
Donut Filter |
|
|
|
|
|
|
Az=0.96; SE=0.02 |
|
|
0 |
|
|
|
|
|
|
0 |
0.2 |
0.4 |
0.6 |
0.8 |
1 |
|
FPF
Figure 13.17: Computer ROC plots of the TPF and FPF pairs obtained from the classification of 101 clusters using two-view information for feature estimation. The dashed curve corresponds to the results obtained with the symmlet wavelet filter and the solid curve corresponds to the results obtained with the donut filter. The estimated area indices AZ and corresponding SE values are included in the insert.
740 |
Kallergi, Heine, and Tembey |
symmlet wavelet. And both outperformed their respective performances on the single-view application. The results suggest that the combination of views for feature estimation seems beneficial to the classification process.
Two views could lead to the definition of more robust features improving classification performance independent of the segmentation method used in the process. But, is averaging the best approach to feature selection from the two mammographic views? Our results seem to indicate that averaging is promising. However, they are somewhat counterintuitive since averaging carries the risk of introducing a fuzziness to an otherwise good descriptor, i.e., a feature that was a good descriptor in one view but poor in the other may lose its robustness once averaged. So, should we average or possibly combine features from the two views for the generation of a larger feature set? The answer to this question is not clear and more work is needed to determine the best feature combination from two mammographic views.
13.6.3Impact of False Positive Segmentations on Classification
In this third experiment, we examined the impact of the FP segmentations on the performance of the classifier. As seen in Figs. 13.13 and 13.14, several signals remain in the segmentation output that are not true calcifications, individual, or clusters. These signals enter the classification stage of the algorithm and are likely to affect performance. To determine the degree of this effect, we first estimated the number of TP and FP segmented clusters. This was done be comparing the segmentation output to manual outlines of the clusters and their major calcifications generated by expert mammographers. The guidelines and conventions described elsewhere [70] were followed for these estimates. Specifically, a segmented group of calcifications was considered a TP when it contained at least three segmented true calcifications [71]. A FP cluster was one that consisted of at least three segmented objects outside the area of the true cluster within a distance of ≤1 cm from each other. Following the above guidelines, we determined that for a 100% TP rate, an average of 2.8 FP clusters were segmented per image with the symmlet wavelet and an average of 2.0 FP clusters were segmented with the donut filter. A reduction in either FP rate was always followed by a reduction in the TP rate to levels that were not acceptable
Computer-Aided Diagnosis of Mammographic Calcification Clusters |
741 |
by the classification stage that, in our case, is heavily based on morphology and distribution characteristics of the individual calcifications and their clusters.
To study the impact of the FP signals on performance but without losing TP information, we did the following experiments:
(a)The 512 × 512 pixel ROIs of the 260 clusters were automatically reduced to 200 × 200 pixels. As a result, several of the edge effects and associated false signals were eliminated concentrating the analysis on the center of the region where the signal of interest (cluster) should normally be present. Both algorithm versions were applied to the reduced-size ROIs. Results suggested that the classification of both the benign and malignant cases might be improved by up to 15% for the algorithm using the symmlet wavelet filter and up to 10% for the algorithm using the donut filter. The smaller improvement in the latter case was expected because the donut filter did not show major edge effects as the symmlet wavelet did in the original ROIs (see Figs. 13.13 and 13.14). This seemed to be an easy and fast remedy to the problem of FP signals with one downside. Namely, if the clusters were off-center in the initial ROI either due to their physical location in the breast (e.g., close to the chest wall or the skin area) or due to the initial ROI selection, then important information was lost and classification could not be done successfully.
(b)In a second experiment, all FP clusters and all single, isolated false signals that were outside the boundaries of the true cluster were manually eliminated from the 512 × 512 pixel ROIs. This manual elimination was done for a subset of 30 cases that contained small calcification clusters (3–10 calcifications per cluster). The original and FP-free ROIs were then used for feature estimation and classification. The elimination of the FP signals improved the classification of both benign and malignant cases. Significant classification improvement was observed for both benign and malignant calcification clusters and both algorithm versions. Classification errors were reduced up to 30% for the benign cases and up to 50% for the malignant cases. Further analysis of these results revealed that the presence of very small false objects in the segmentation output degraded classification performance more than large false objects such as those originating from the edge artifacts.
742 |
Kallergi, Heine, and Tembey |
13.7 Conclusions
CADiagnosis is an area that merges the fields of signal processing and pattern recognition for the creation of tools that can have a significant impact in health care delivery and patient management. CADiagnosis algorithms usually involve several modules that need to be separately optimized and validated for an overall optimum performance. In this chapter, we presented a CADiagnosis methodology for the differentiation between benign and malignant breast calcification clusters in mammograms. We specifically looked into one of the aspects of the algorithm, namely the impact of segmentation in the overall classification process, and the role of multiresolution analysis in the segmentation process.
Our classification approach was based primarily on morphological and distributional features of mammographic calcifications and, hence, the role of segmentation was particularly important in the overall implementation and performance. Knowing the limitations of image segmentation techniques that were further exaggerated by our additional challenge to preserve morphology and distribution, we developed two multiresolution filters that were able to yield successful and clinically promising results. Although far from perfect segmentations, the symmlet wavelet and the donut filter adequately preserved the characteristics of the calcifications as required by the overall algorithm’s design. A new filter, labeled as the “donut filter,” was introduced for mammogram processing that seems to offer a robust solution to the problems associated with the detection and segmentation of mammographic images. The new filter was not utilized to its full potential and several implementation pathways remain to be explored. Its initial testing, however, yielded promising results and its usefulness could go beyond mammography to other medical imaging applications.
An important question at the end of the experiments presented here is whether similar classification performance can be achieved, either with the symmlet wavelet or the donut filter, for images generated from various sources. For example, for images generated by different film digitizers (laserbased vs. charge-couple-device-based systems), or by different imaging systems (screen/film vs. direct digital systems), or with different resolution characteristics (pixel size and bit depth). Preliminary work with different data types suggests that similar classification results may be obtained if a standardization process is applied to the images prior to processing. As long as pixel size and depth are within acceptable ranges for CADiagnosis applications in mammography,
Computer-Aided Diagnosis of Mammographic Calcification Clusters |
743 |
a standardization algorithm can easily convert the characteristics of any set of data to those for which the CADiagnosis system was initially trained and optimized keeping performance consistent [20, 73].
An interesting spin-off application of our initial development originated from the FP impact observation on classification performance. We found that classification results could be used as an indirect measure of segmentation quality particularly when the classification scheme is based solely on morphological and distributional characteristics like the one described here. Segmentation evaluation is one of the most challenging issues in medical image processing. It usually requires objective and accurate “ground truth” or “gold standard” information that is often unattainable in medical imaging where the human observer is commonly the only source of “ground truth” information. Using the classifier’s output for indirect segmentation validation may offer an advantage over more traditional techniques that use absolute measures of shape and size and require exact ground truth information. After all, it is the clinical outcome that is important in these applications.
Finally, the described CADiagnosis scheme seems to be amendable to a variety of applications beyond breast cancer screening and early diagnosis. The input feature set and classification output could be modified and expanded to address problems associated with the diagnostic patient and specific breast disease types involving calcifications, e.g., ductal carcinoma in-situ, for the development of computer tools that go beyond detection and diagnosis into the domains of prognosis, patient management, and follow-up.
13.8 Acknowledgments
The authors acknowledge the valuable assistance of Angela Salem in the generation of the image databases used for algorithm development and testing, and of Joseph Murphy in the processing of the data.
Questions
1.Role of CADetection and CADiagnosis techniques in breast cancer and mammography. What is the relationship of the two systems?