

Крючков Фундаменталс оф Нуцлеар Материалс Пхысицал Протецтион 2011
.pdf
|
|
|
|
D N - D |
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
n |
|
n |
|
n |
|
|||||
|
|
|
|
0 |
n |
|
|
|
|
|
|
|
|
|||||||||
p(x = 0) = |
|
|
|
|
|
|
|
= 1- |
|
× 1 |
- |
|
× 1 |
- |
|
|
´. |
|||||
|
|
N |
|
|
|
|
|
|
|
|||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
N |
|
N -1 |
|
N - 2 |
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
n |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
n |
|
|
|
|
|
n D |
|
|
|
|
|
|
|
|
|
|
|||
´ 1 |
- |
|
|
|
|
£ |
1 |
- |
|
|
|
|
= 0.05; |
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
N |
- D +1 |
|
|
|
N |
|
|
|
|
|
|
|
|
|
|
|||||
0.05 £ (1- n N )D ;
N )D ;
0.05 £ (1- n 2000)100 ®1- n
2000)100 ®1- n 2000 ³ 100 0.05 n = 2000 ×(1- 0.97).
2000 ³ 100 0.05 n = 2000 ×(1- 0.97).
We will get n = 60.
Similarly, we can determine the sample size to check condition 1: p = 0.05, N = 2000, d < 1 % = 20, x = 0.
N = 278.2 or, by rounding to an integer, n = 279.
If the number of elements in a set is rather great, one needs to go on with the study even if one defective item has been found. What should the sample be if we accept that there is one defect? The sample should be such that, provided there are no defects or there is one defect, one can state with a 95% probability that the total number of defects does not exceed 1%, that is
p(x ≤ 1) = p(x = 0) + p(x = 1) ≤ 0.05; |
|
|
|
|
||||||||||||||||
|
|
|
|
|
n D |
|
|
|
|
|
|
|
|
|
||||||
p(x = 0) = 1 |
- |
|
|
|
; |
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
|
|
|
N |
|
|
|
|
|
|
|
|
|
||||||
|
|
D N - D |
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
p(x = 1) = 1 |
n -1 |
= |
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
N |
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
n |
|
|
|
|
|
|
|
|
|
|
||||||
|
|
D × n |
|
|
|
|
|
n |
|
n |
|
|
|
n |
|
|
||||
= |
|
|
× 1 |
- |
|
|
|
|
× 1 |
- |
|
|
××× 1 |
- |
|
|
£ |
|||
|
|
|
|
|||||||||||||||||
|
|
(N - D +1) |
|
|
|
|
N |
|
N -1 |
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
N - (D - 2) |
|
||||||||||
|
|
D × n |
|
|
|
|
|
n D−1 |
|
|
|
|
|
|
|
|
||||
£ |
|
|
× 1 |
- |
|
|
|
|
|
£ 0.05. |
|
|
|
|
|
|
||||
|
(N - D +1) |
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
N |
|
|
|
|
|
|
|
|
|
||||
201
The computation gives the results (N = 2000) as shown in Tables 4.6 and 4.7.
|
|
|
|
Table 4.6 |
|
Minimum sample size to check conditions 1 and 2 |
|
|
|||
|
|
|
|
|
|
Check of condition 1 |
Check of condition 2 |
|
|
||
Maximum number of |
Sample |
Maximum number of |
|
Sample |
|
defects |
|
defects |
|
|
|
0 |
279 |
0 |
|
60 |
|
1 |
432 |
1 |
|
93 |
|
2 |
564 |
2 |
|
122 |
|
Table 4.7
Determination of the minimum sample size to check condition 2 depending on the permissible number of defects in sample
Maximum permissible |
Minimum sample size |
|
number of defects |
||
|
||
0 |
60 |
|
1 |
93 |
|
2 |
122 |
|
3 |
150 |
|
4 |
177 |
|
5 |
203 |
|
6 |
228 |
|
7 |
253 |
|
8 |
277 |
|
9 |
302 |
|
10 |
325 |
If defects were nevertheless found, corrective measures should be taken and the sample study should be replicated or a 100% inventory taking should be conducted.
As so the sample size, small samples are absolutely evident to be less informative while large samples rather informative and to have higher significance levels, but are however more expensive.
202
Sampling strategy
There are several sampling options to choose the one to give a maximum of information at a minimum cost:
∙simple random sampling;
∙systematic random sampling;
∙nested (cluster) sampling;
∙stratified random sampling;
∙probability sampling.
Let us compare these options.
Simple random sampling. All elements in a set are listed and numbered 1,… , N, where N is the set size. Then n numbers are selected from the list in a random manner (e.g. using a generator of random numbers), after which the listed items matching the selected numbers are picked out.
Advantages (+) and drawbacks (–):
∙the listed items are not hard to select from (+);
∙the estimates of the mean and the variance are not biased (+);
∙the elements of the set need to be identified and designated before the sampling test is done (–);
∙search for the item to select may take time (–);
∙essential, still small subgroups can have an inadequate representation (–). Systematic random sampling. Each k–th element of the set is selected. Advantages (+) and drawbacks (–):
∙items are not hard to select (+);
∙one does not need to know the total number of elements in the set (+);
∙the elements of the set may need to be ordered (–).
Cluster sampling. Clusters of nuclear material form pileups depending on how NM is stored. For instance, containers are normally shelved, racked or stored otherwise as specially determined being so naturally grouped. Log entries with respect to a container often provide information on only that cluster to which this belongs, e.g. room and shelf number and so on. So, considering clusters as the elements of the set to be sampled from with the subsequent check of containers in each selected cluster, may turn out to be highly advantageous in terms of time and cost.
There are many cluster sampling types to choose from. Of these, singlestage and two-stage samplings are most common.
Single-stage cluster sampling suggests sampling, as such, done from clusters with a 100% check inside each cluster. Two-stage sampling
203
suggests sampling both among clusters and inside clusters. In the latter case, fewer items are checked in each cluster but more clusters are tested. A potential drawback is the requirement to have information about each container in each cluster.
Advantages (+) and drawbacks (–):
∙a time and cost saving potential, specifically for large sets with a marked nest structure (+);
∙essential clusters may fall out of view (–);
∙if the cluster elements are homogeneous, parameters will have an underestimated uncertainty (–).
Stratified sampling. Stratum is a uniform material. NM can be stratified by enrichment and content of uranium, by physical or chemical form or by measurement technique. The stratification procedure can be broken down into the following steps:
1)complete information on all items (NM types, rough NM enrichments (by elements or by isotopes), container location data and predicted measurement errors) shall be obtained;
2)items shall be grouped by a certain quantity feature, e.g. enrichment, isotope content, uranium concentration and so on;
3)if the universe contains different NM types (UF6, UO2), the groups obtained in step 2 shall be divided into subgroups by the type of material;
4)if the subgroups from step 3 contain material to which different measurement techniques with different errors will be applied, the subgroups obtained shall be divided into smaller groups by the type of measurements;
5)the stratification is over after step 4 so sampling can be done. Advantages (+) and drawbacks (–):
∙the sample represents at least one element of each layer which ensures the best possible coverage of NM (+);
∙one can estimate parameters both for each layer and for the whole of the set (+);
∙the elements within a layer should be homogeneous (–);
∙a more sizeable sample may be required than if other methods are used
(–).
Probability sampling. The set is sampled given the relative relevance measure (with scale attachment) pro rata the significance of the elements tested.
Advantages (+) and drawbacks (–):
∙prime attention will be given to the material most attractive for theft (+);
204

· the sample size depends on the selected relevance measure (–).
Determination of the sample size from variables, mean value and errors
Simple random sampling. The following formula is used to determine the size of a simple random sample from variables:
n = |
t2 |
× D2 |
× N |
(4.59) |
|
|
|
|
, |
||
|
|
|
|||
(N -1)ε 2 + t2 × D2
where D = σ x is the variance coefficient for the characteristic of interest in x
the universe (found based on expert data or from earlier measurement
|
|
|
|
|
- |
|
|
|
|
results); ε = |
|
|
|
x |
X |
is the allowable difference between the mean (true) |
|||
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
||
|
|
|
X |
||||||
|
|
|
|
|
|
||||
value of the characteristic in the universe and the mean sample value; and tN is the quantity of the standardized deviation for a normal distribution of probabilities (determined by the probability that the relative difference between the sample estimate and the set value does not exceed ε) (Table 4.8).
Table 4 .8
Quantity of standardized deviation
tN |
P |
1.0 |
0.683 |
1.5 |
0.866 |
1.96 |
0.95 |
2.0 |
0.954 |
2.5 |
0.988 |
3.0 |
0.997 |
3.5 |
0.999 |
The mean sample value is found by the following formula:
n
∑xi
|
= |
i=1 |
, |
(4.60) |
|
x |
|||||
|
|||||
|
|
n |
|
||
205

|
2 |
|
|
|
N - n |
|
σˆ |
2 |
|
|
|
|
|
|
|
|
|||||
σ |
|
(x ) = |
|
|
× |
|
|
, where |
||
|
|
|
|
|||||||
|
|
|
|
|
N |
|
n |
|||
For the total values we have:
X = N × x; σ ( X ) = N
n
∑(xi - x )2
σˆ 2 = |
i=1 |
|
. |
(4.61) |
|
|
|||
|
|
n -1 |
|
|
×σ (4.62) (x).
Here and hereinafter: n is the sample size, N is the universe size, xi is the measurement result for the i–th sample element, x is the mean value of the characteristic of interest for the sample (and for the universe), and X is the total value of the characteristic of interest for the universe.
Cluster sampling. Single-stage sampling. The following formula is used to determine the cluster sample size from variables:
n = |
m |
|
|
∑Ni, |
|
||
|
i=1 |
(4.63) |
|
|
|
t 2 × D2 × M |
|
m = |
|
, |
|
|
(M -1)ε 2 + t 2 × D2 |
||
where D = σ clust is the variance coefficient for the characteristic of
Хclust
interest between clusters (found from expert data or earlier measurement
∑M (X i - X clust )
results); σ clust2 = |
i=1 |
|
is the intercluster (estimated) variance; М |
|
|
||
|
|
М |
|
Ni
is the number of clusters in the universe; X i = ∑xij is the total value of the
j=1
characteristic in the i–th cluster; interest (variable) for the
xij is the quantity of the characteristic of j–th container in the i–th cluster;
M
X clust = ∑X i / M is the true mean value of the characteristic of interest for
i=1
206

|
|
|
|
|
- |
|
|
|
|
all clusters; ε = |
|
|
|
x |
X |
is the permissible difference between the mean |
|||
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
||
|
|
|
X |
||||||
|
|
|
|
|
|
||||
(true) value of the characteristic in the universe and the mean sample value; and t is the quantity of the standardized deviation for a normal distribution of probabilities (determined by the probability that the relative difference between the sample estimate and the set value does not exceed ε).
The mean sample value is found by the following formulas:
|
|
|
|
|
|
|
|
|
|
m |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
M × ∑X i |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
i=1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
x = |
|
|
, |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
(4.64) |
|||||||||
|
|
|
m × N |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
2 |
|
|
|
|
M - m |
|
|
M |
|
|
2 |
|
||||||||||||
|
|
σ |
(x ) |
|
|
|
|||||||||||||||||||||||
|
|
|
= |
|
|
|
|
|
|
|
× |
|
|
|
|
|
|
|
|
×σ clust , |
(4.65) |
||||||||
|
|
|
|
|
-1 |
|
|
|
|
|
|
|
|
||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
M |
|
|
|
N m |
|
|
|
||||||||||||
|
|
m |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
m |
|
||
|
|
∑(X i - |
|
clust )2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
∑X i |
|
||||
|
X |
|
M -1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
2 |
= |
i=1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
= |
i=1 |
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||
where σclust |
|
|
|
|
|
|
|
|
|
, and X clust |
is the mean |
||||||||||||||||||
m -1 |
|
|
|
|
|
M |
|
|
m |
||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
total value of the characteristic in the cluster. |
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||
For the total values we have: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
X = N × |
|
; |
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
x |
|
|
|
|
|
|
|
|
|
|
|
(4.66) |
|||||||
|
|
|
|
|
|
|
|
|
|
σ ( X ) |
= N |
×σ ( |
|
). |
|
|
|
|
|||||||||||
|
|
|
|
|
|
|
|
|
|
x |
|
|
|
|
|||||||||||||||
Here: m is the sample size; M is the number of clusters in the set; X is the estimated total value of the characteristic of interest in the set; xij is the
quantity of the characteristic of interest (variable) for the j–th container in
M
the i–th cluster; Ni is the number of containers in the cluster i; N = ∑N i is
i=1
the universe size (total number of containers); xi is the measurement result for the i–th sample element, x is the average value of the characteristic of interest for the sample (and for the universe).
Stratified sampling. The mean sample value is determined as follows:
|
|
L |
Ni |
ni |
|
|
|
|
= ∑ |
∑xij , |
(4.67) |
||
x |
||||||
|
Nni |
|||||
|
|
i=1 |
j=1 |
|
207

|
|
|
|
|
|
L |
|
N |
|
|
2 |
s |
2 |
|
N |
|
- n |
|
|
|
|||
s2 ( |
x |
) = ∑ |
|
|
|
i |
|
|
|
i |
|
|
i |
|
i |
, |
(4.68) |
||||||
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||
|
|
|
|
|
i=1 N |
ni |
|
|
Ni |
|
|
|
|||||||||||
where |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
ni |
(xij |
- |
|
j )2 |
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
∑ |
|
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
x |
|
|
|
|
|
|
|
|
|
|||||||||||
si2 = |
j=1 |
|
|
|
|
|
|
|
|
|
|
|
– |
|
|
|
|
|
|
|
(4.69) |
||
|
|
ni |
-1 |
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
is the variance inside the stratum, and |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
ni |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
∑xij |
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
i = |
i=1 |
|
|
– |
|
|
|
|
|
|
|
(4.70) |
|||||
|
|
|
|
x |
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
ni |
|
|
|
|
|
|
|
|
|
|
|
||
is the average value of the characteristic of interest in the i–th stratum. For the total values we have:
X = N × |
|
; |
|
|
|
|
x |
|
|
|
(4.71) |
||
σ ( X ) = N |
×σ ( |
|
). |
|||
x |
||||||
Here: ni is the number of containers selected from the i–th stratum; |
L is the |
|||||
number of strata in the set; X is the estimated total value of the characteristic of interest in the set; xij is the quantity of the characteristic of interest (variable) for the j–th container in the i–th stratum; Ni is the number
M
of containers in the stratum i, N = ∑N i is the universe size (total number
i=1
of containers); x is the mean value of the characteristic of interest for the sample (and for the universe).
The cluster sample size determined from variables as required to ensure the specified accuracy level has been estimated from the following formula:
|
|
|
|
|
|
|
|
|
|
L |
2 |
) |
|
|
|
|
|
|
|
|
|
|
|
|
ε 2 = t 2 ∑Ni2 |
σ i (Ni - ni |
, |
(4.72) |
|
|
|
|
|
|
|
|
|
|
ni (Ni -1) |
|
||||
|
|
|
|
|
|
|
|
|
|
i=1 |
|
|
|
|
|
|
|
|
|
- |
|
|
|
|
|||||
where ε = |
|
|
|
x |
X |
|
is the permissible difference between the mean (true) |
|||||||
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
||||||
|
|
|
X |
|||||||||||
|
|
|
|
|
|
|
|
|
|
|
||||
value of the characteristic in the universe and the mean value of the sample; t is the quantity of the standardized deviation from a normal distribution of probabilities (determined by the probability that the relative difference
208

between the sample estimate and the set value does not exceed ε); and
∑Ni (xij - X i )2
σ i2 = |
j=1 |
|
is the variance (variation) of the characteristic of |
|
|
||
|
|
Ni |
|
interest inside the i–th stratum.
A note should be made that Х and si are not known. Several sets of ni exist that satisfy the condition (4.72). One may determine ni from the requirement of minimizing the variance of the mean sampled and the total value of the characteristic in the sample:
L
n= ∑ni ,
i=1
where
n =
|
|
|
|
|
|
N i ×σ i |
|
|
|
ni = n |
|
, |
||
L |
||||
|
|
|
||
|
∑N i ×σ i |
|
||
|
i =1 |
|
|
|
t |
2 × ∑ N i |
×σ i |
|
× |
∑N i ×σ i |
|
||||
|
L |
2 |
2 |
|
|
L |
|
|
|
|
|
i=1 N i -1 |
i=1 |
|
|
, |
|||||
|
|
|
|
L |
2 |
2 |
|
|||
|
|
|
|
|
||||||
|
ε 2 ( X ) + t2 × |
∑ |
N i |
×σ i |
|
|
||||
|
|
|
|
|||||||
|
|
|
|
i=1 N i -1 |
|
|
||||
and the respective estimates are substituted for X and si.
4.5. Control and assurance of measurement quality
(4.73)
(4.74)
By quality control we will mean systematic actions one undertakes to ensure adequate operations of a structure, a system or a system component.
The quality of measurements is ensured by two activities: quality control and quality assessment.
1.Quality control includes procedures and actions developed and used to support the needed quality of measurement.
2.Quality assessment includes procedures and actions one undertakes to make sure that the quality control system operates properly.
NM measurement control (MC) is a component of any quality assurance program. MC is a system of procedures to track down and assess sources of errors. MC includes monitoring of instrument operations using standards and estimation of the error instability in particular measurements (this affects the variance of the value obtained and the ID calculation result).
209

Objectives of measurement quality control:
∙acquisition of quantitative data on uncertainties of measurements;
∙support of measurement process invariability;
∙detection and elimination of unusual occurrences.
Functional elements of NM measurement control systems:
∙use of standards;
∙qualification of measurement techniques;
∙interlaboratory comparisons of measurement data;
∙preparation of control charts;
∙calibrations;
∙other experiments to estimate measurement data uncertainties (auxiliary measurements).
Let us define more accurately some of the concepts.
Effect – a factor which does not represent a measurable q uantity and influences measurement results. MC suggests detection and description of effects inherent in the measurement system in use. So an error (the difference between the true and the measured values) is viewed as the result of cumulative effects.
Working standard – a material, a device or an instrument with the va lue known with respect to state standards or metrology systems.
A standard should be representative with respect to anything that affects measurements. It is normally suggested that the standard and the material to be measured have similar dimensions, shapes and chemical compositions. The hierarchy of standards is shown in Fig. 4.4.
ГосударственныйNational/internationalМеждународныйstandardэталон
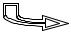 SecondaryВторичные эталоныstandards
SecondaryВторичные эталоныstandards
WorkingРабочие эталоныstandards
Fig. 4.4. Hierarchy of standards
A low-level standard is qualified by multiple measurements of its value against a higher-level standard. The mean arithmetic value of the measurement result will determine the value of the low-level standard. The uncertainty of the low-level standard value is obtained by summing up the
210