

Вывод результатов и их анализ
Пользователь может вызвать на экран горизонтальную и вертикальную дендрограмму (Horizontal hierarchical plot или Vertical icicle plot), показывающую объединение объектов, расстояние между которыми является наименьшим, в кластеры (кластеризация методом одиночной связи). Наиболее традиционное – вертикальное представление (рис. 1.21).
Теперь представим себе, что постепенно (очень малыми шагами) происходит «ослабление» критерия о том, какие объекты являются уникальными, а какие нет. Другими словами, понижается порог, относящийся к решению об объединении двух или более объектов в один кластер. В результате происходит связывание вместе всё большего и большего числа объектов и агрегирование (объединение) все большего и большего числа кластеров, состоящих из различающихся все сильнее элементов. Окончательно на последнем шаге все объекты объединяются вместе. Когда данные имеют ясную «структуру» в терминах кластеров объектов, сходных между собой, тогда эта структура, скорее всего, должна быть отражена в иерархическом дереве различными ветвями. В результате успешного анализа методом объединения появляется возможность обнаружить кластеры (ветви) и интерпретировать их.
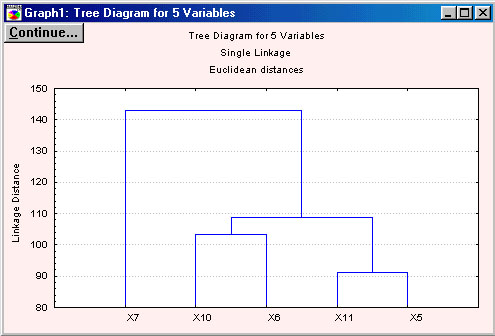
Рис. 1.21. Vertical icicle plot
Чтобы вернуться в окно, содержащее другие результаты кластерного анализа, необходимо щелкнуть по кнопке Continue.
Щелчком мыши можно раскрыть строку Amalgamation schedule, содержащую протокол объединения кластеров (рис. 1.22). В заголовке указан иерархический агломеративный метод и метрика расстояния. Таблица может занимать несколько окон.
Следующей в окне результатов идет кнопка Graph of amalgamation schedule. После щелчка, раскрывается окно, содержащее ступенчатое, графическое изображение изменений расстояний при объединении кластеров рис. 1.23.
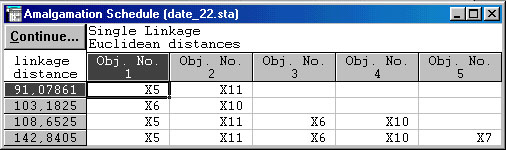
Рис. 1.22. Amalgamation schedule
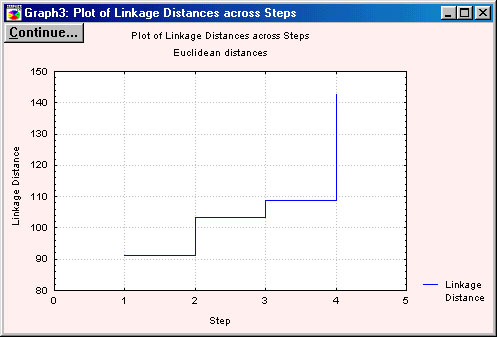
Рис. 1.23. Graph of amalgamation schedule
Вернувшись в основное окно результатов и классификации. Для просмотра же матрицы расстояний между объектами необходимо щелкнуть на строке Distance matrix (рис. 1.24).
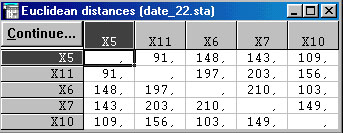
Рис. 1.24. Матрица расстояний
В основном окне результатов классификации имеется строка Save distance matrix as: (Сохранить матрицу расстояний как:) позволяющая задать имя файла, в котором будет сохранена матрица расстояний, которая в дальнейшем будет подвергнута обработке.
Строка Descriptive statistics содержит такие важнейшие описательные статистики, как среднее (means) и среднеквадратическое отклонение (standart deviations) для каждого наблюдения (рис. 1.25). При проведении классификации n объектов по k признакам, для пользователя представляют большой интерес значения этих показателей для каждого признака.
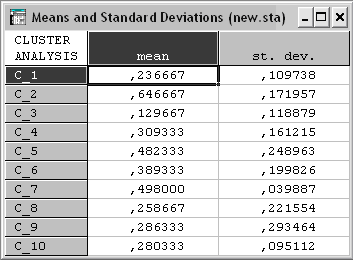
Рис. 1.25. Средние и среднеквадратичные отклонения для каждого исходного объекта
Для того чтобы эти характеристики рассчитывались именно по признакам необходимо вернутся в основное окно настройки параметров и задать в строке Cluster значение variables (columns).
Задача 3.
На
предприятии существует
![]() научно-производственных отделов, занятых
выпуском различной продукции, работ,
услуг. Т. к. виды деятельности,
количество работающих, рентабельность
отделов существенно различаются между
собой, было решено сгруппировать отделы
в несколько однородных групп, а затем
для каждой группы разработать свою
систему премирования.
научно-производственных отделов, занятых
выпуском различной продукции, работ,
услуг. Т. к. виды деятельности,
количество работающих, рентабельность
отделов существенно различаются между
собой, было решено сгруппировать отделы
в несколько однородных групп, а затем
для каждой группы разработать свою
систему премирования.
Выбраны
![]() признака, с помощью которых описывались
параметры каждого отдела:
признака, с помощью которых описывались
параметры каждого отдела:
![]() – стоимость активной части основных
производственных фондов (тыс. руб.);
– стоимость активной части основных
производственных фондов (тыс. руб.);
![]() – среднемесячный объем работ отдела
(тыс. руб.);
– среднемесячный объем работ отдела
(тыс. руб.);
![]() – удельный вес работ/услуг отдела по
внутрифирменной кооперации (%);
– удельный вес работ/услуг отдела по
внутрифирменной кооперации (%);
![]() – среднемесячная прибыль отдела
(тыс. руб.).
– среднемесячная прибыль отдела
(тыс. руб.).
Исходные данные по отделам определить самостоятельно.
|
|
|
|
|
1 |
|
|
|
|
2 |
|
|
|
|
3 |
|
|
|
|
… |
|
|
|
|
16 |
|
|
|
|
Провести кластеризацию отделов, используя иерархические алгоритмы (Joining):
Используя исходные данные;
Используя стандартизированные данные (т.е. данные, преобразованные по формуле
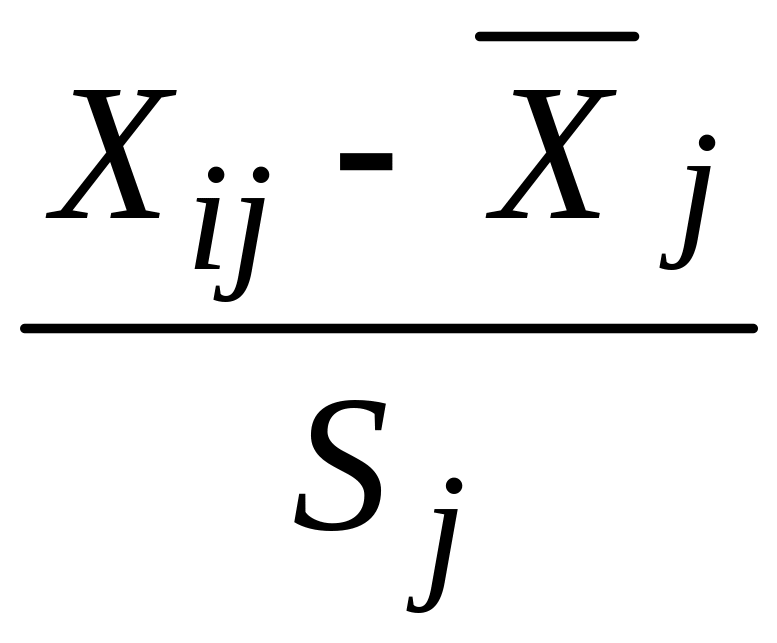 ).
).
![]() – i-е значение j-го
признака
– i-е значение j-го
признака
![]() .
.
 – оценка среднего для j-го
признака.
– оценка среднего для j-го
признака.
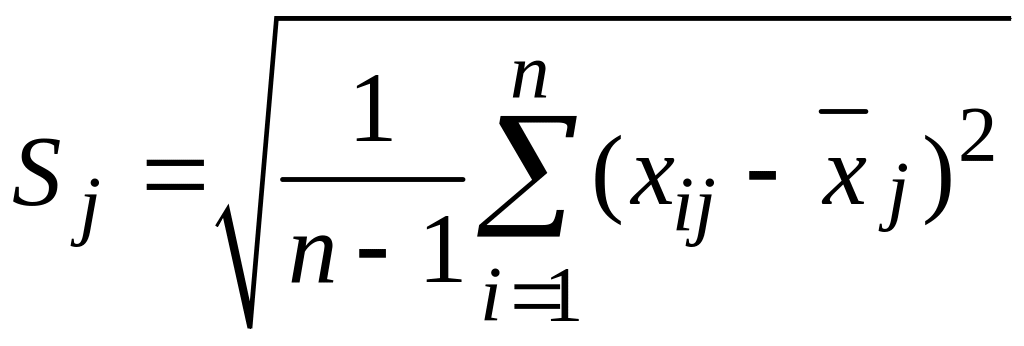 – оценка СКО для j-го
признака.
– оценка СКО для j-го
признака.
Сравните результаты кластеризации. По результатам кластеризации определите число кластеров и их состав. Найдите статистические характеристики каждого кластера.
Проведите кластеризацию, используя метод K-средних (число кластеров задайте равным 4). Сравните результаты (составы кластеров).