

Выполнение работы
Для выполнения лабораторной работы подготовьте исходные данные для проведения интеллектуального анализа в системе STATISTICA (рис. 4.13).

Рис. 4.13. Исходная выборка данных
В стартовой панели модуля Nonparametric Statistics (Непараметрические статистики) (рис. 4.14) выбираем Correlations (Spearman, Kendall tau, gamma) (Коэффициенты ранговой корреляции Спирмена, Кендалла, гамма) и нажимаем OK.
Рис. 4.14. Стартовая панель модуля Nonparametric Statistics (Непараметрические статистики)
Коэффициент ранговой корреляции Спирмена:
В появившемся окне (рис. 4.15) выбираем соответствующий коэффициент ранговой корреляции, нажимаем Variables и задаем переменные (рис. 4.16). Нажимаем OK (рис. 4.17).
Рис. 4.15. Окно Nonparametric Correlations (Непараметрические корреляции)

Рис. 4.16. Окно выбора переменных
Рис. 4.17. Окно Nonparametric Correlations (Непараметрические корреляции)
получаем следующую таблицу результатов:
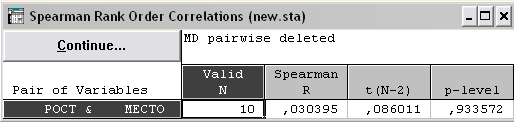
Рис. 4.18. Таблица результатов анализа
Вывод: гипотеза H0 принимается, если rs < (, n).
Из таблицы находим выборочный коэффициент ранговой корреляции Спирмена rs = 0.03.
Находим теоретическое значение s(0.01, 10) = 0.58, сравниваем и получаем, гипотеза принимается, рост спортсмена и место, занимаемое им на соревновании, некоррелированы (независимы).
Коэффициент ранговой корреляции Кендалла:
В окне Nonparametric Correlations (Непараметрические корреляции) (рис. 4.19) выбираем соответствующий коэффициент ранговой корреляции, нажимаем Variables и задаем переменные. Нажимаем OK.

Рис. 4.19. Окно Nonparametric Correlations (Непараметрические корреляции)
Получаем следующую таблицу результатов (рис. 4.20):
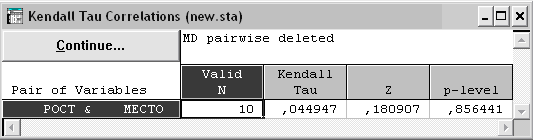
Рис. 4.20. Таблица результатов анализа
Вывод: выборочное значение коэффициент ранговой корреляции Кендалла = 0.045.
По таблице находим критическое значение (, n) = 0.45.
Так как < 0.45, то гипотеза H0 принимается, рост спортсмена и место, занимаемое им на соревновании, некоррелированы (независимы).
На уровне значимости = 0.01 оба коэффициента ранговой корреляции незначимы, это говорит о том, что и в том и в другом случае гипотеза принимается.
Задача 4. Критерий серий Вальда-Вольфовица.
Задание:
При изучении иностранного языка в 2-х группах студентов (
 – количество студентов в каждой группе)
использовались две различные методики.
После изучения части курса студенты
обеих групп написали диктант (
– количество студентов в каждой группе)
использовались две различные методики.
После изучения части курса студенты
обеих групп написали диктант ( –
количество ошибок в диктанте, допущенных
i-м студентом j-ой
группы).
–
количество ошибок в диктанте, допущенных
i-м студентом j-ой
группы).
Например:
1 группа: 1, 6, 3, 11, 13, 5, 8, 31, 2, 16, 7, 23, 20, 21, 9.
2 группа: 12, 7, 4, 8, 3, 6, 10, 1, 2, 5, 9, 13, 20, 14, 21, 10, 11, 17, 19, 15, 22, 16.
Можно ли считать, что применение разных методик не приводит к существенному различию в результатах диктанта? Принять .
Выполнение работы:
Для выполнения лабораторной работы подготовьте исходные данные для проведения интеллектуального анализа в системе STATISTICA (рис. 4.21).
Чтобы решить задачу надо записать данные в две переменные. В одну переменную (dependent) надо последовательно занести обе выборки, а в другую (grouping) – коды, определяющие принадлежность элементов к той или иной выборке.
В стартовой панели модуля Nonparametric Statistics (Непараметрические статистики) (рис. 4.22) выбираем Wald-Wolfowitz runs test (Критерий серий Вальда-Вольфовица) и нажимаем OK.
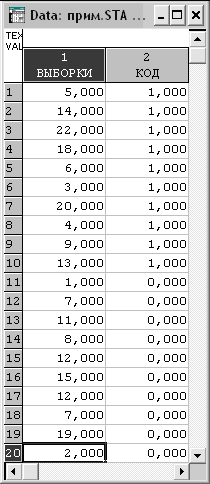
Рис. 4.21. Исходная выборка данных
Рис. 4.22. Стартовая панель модуля Nonparametric Statistics (Непараметрические статистики)
В появившемся окне (рис. 4.23) нажимаем Variables и задаем переменные (рис. 4.24). Нажимаем OK (рис. 4.25).
Рис. 4.23. Окно Wald-Wolfowitz runs test
(Критерий серий Вальда-Вольфовица)

Рис. 4.24. Окно выбора переменных
В появившемся окне Wald-Wolfowitz runs test (Критерий серий Вальда-Вольфовица) выполняем соответствующие установки (рис. 4.25), нажимаем OK и получаем следующую таблицу результатов (рис. 4.26):
Рис. 4.25. Окно Wald-Wolfowitz runs test
(Критерий серий Вальда-Вольфовица)

Рис. 4.26. Таблица результатов анализа
Вывод: выборочное значение Z: ze 0.46.
Так как это значение меньше квантили распределения N(0, 1) u0.99 = 2.326, то гипотеза H0 не отклоняется, т. е. различные методики обучения не повлияли на результаты диктанта.