

Выполнение работы
Рассмотрим процесс формирования выборок в системе STATISTICA.
Для проведения кластерного анализа иерархическим агломеративным методом на панели инструментов нажимаем на кнопку переключателя модулей STATISTICA Module Switcher (рис. 1.7). В появившемся окне (рис. 1.8) выбираем модуль Cluster Analysis (Кластерный анализ), нажав кнопку Switch to (Переключиться в) или просто дважды щелкнув мышью по названию модуля Cluster Analysis.
На экране появится стартовая панель модуля (рис. 1.9) Clustering Method (методы кластерного анализа): Joining (tree clustering) (иерархические агломеративные методы или древовидная кластеризация), K-means clustering (метод K-средних), Two-way joining (двувходовое объединение).
Откроем файл с исходными данными (Open Data). После выбора Joining (tree clustering) и нажатия ОК появляется окно Cluster Analysis: Joining (Tree Clustering) (окно ввода режимов работы для иерархических агломеративных методов) (рис. 1.19).
В появившемся окне выбираем следующие настройки:
нажимаем на кнопку Variables и вводим переменные, участвующие в классификации; для выбора всех переменных используем Select All и нажимаем OK;
в разделе Input (тип входной информации) вводим Raw data (исходные данные);
в разделе Clusters (режим классификации (по признакам или объектам)) выбираем Cases (rows) – классификация объектов;
в разделе Amalgamation (linkage) rule (правило объединения) выбираем Single linkage (метод одиночной связи);
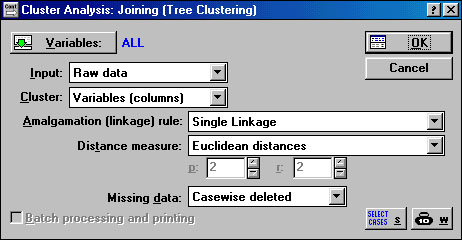
Рис. 1.19. Cluster Analysis: Joining (Tree Clustering) (окно ввода режимов работы для иерархических агломеративных методов)
в разделе Distance measure (метрика расстояний) выбираем Square Euclidean distances (квадрат евклидовой метрики);
Codes for grouping variable (коды для групп переменной) будут указывать количество анализируемых групп объектов;
Missing data (пропущенные переменные) позволяет выбрать либо построчное удаление переменных из списка, либо заменить их на средние значения;
Open Data – позволяет открыть файл с данными. Причем можно указать условия выбора наблюдений из базы данных – кнопка Select Cases;
кнопка W позволяет задавать веса переменным, выбрав их из списка.
После задания всех необходимых параметров и нажатия ОК будут произведены вычисления, а на экране появится окно, содержащее результаты кластерного анализа Joining Results (рис. 1.20).
Информационная часть диалогового окна Joining Results Discriminant Function Analysis Results (результаты анализа кластерных функций) сообщает, что:
Number of variables – число переменных.
Number of cases – число наблюдений.
Joining of variables – осуществлена классификация наблюдений или переменных (зависит от уровня параметра в строке Cluster в предыдущем окне настройки).

Рис. 1.20. Окно Joining Results, содержащее результаты кластерного анализа
Missing data were casewise deleted – Наблюдения с пропущенными данными удаляются (или заменяются средними значениями – зависит от установки в предыдущем окне в строке Missing data).
Amalgamation (joining) rule – правило объединения кластеров (название иерархического агломеративного метода, заданного в строке Amalgamation rules в предыдущем окне настройки).
Distance metric is – Метрика расстояния (зависит от установки в строке Distance measure в предыдущем окне настройки.