

8.2 Определение количества информации при наличии помех
При наличии помех количество информации, которое содержится в принятом сообщении Y относительно переданного Х, определяется как разница между энтропией источника и помехами: I(Y,X)=H(X)-H(X/Y).
При условии что уровень помех очень большой, считается, что сообщение Х и У являются статистически независимыми, и тогда: І(Y,X) = H(X) — H(X/Y)=0
При условии что уровень помех незначительный, считается, что сообщение Х и У являются жестко статистически зависимыми, и тогда: І(Y,X) = H(X)
Величина І(Y,X) называется полной взаимной информацией, ее можно также вычислить с помощью дополнительной энтропии – энтропии помех Н(Y,X)= H(N):
І(Y,X) = H(X) + H(Y) — Н(Y,X)
Для дискретных сообщений:
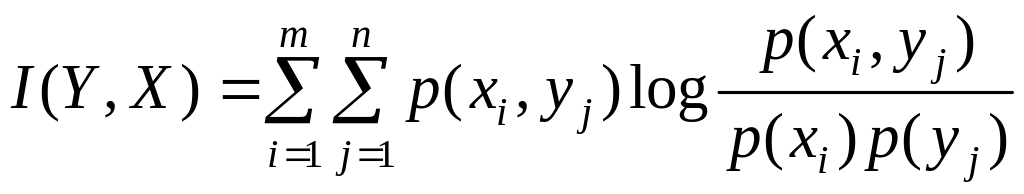
Для оценки непрерывных сообщений:
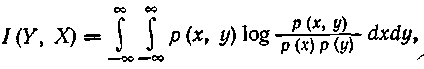
При статистически независимых Х и N: I(Y,X) = H(Y)-H(N).
При нормальном распределении помехи
при длительности сообщения Тс, при
условий, что принятое сообщение у(t)
имеет ограниченный спектр с верхней
частотой Fв, то можно записать:
![]() .
.
8.3 Код, обнаруживающий пакетную ошибку
Групповая ошибка называется пакетной
ошибкой. Пакетная ошибка – это
участок искаженной последовательности
символов, который начинается неправильным
(искаженным) символом и заканчивается
искаженным, в котором могут быть, как
искаженные так и неискаженные, но
количество искаженных подряд символов
не превышает допустимое число (![]() )
. Длина пакета – это количество символов
между первым и последним искаженным
символом, включая эти символы.
)
. Длина пакета – это количество символов
между первым и последним искаженным
символом, включая эти символы.
Для обнаружения пакетной ошибки
используются групповые коды с
проверкой на четность. Если использовать
код с четным числом единиц, то его
недостатком будет необнаружение четных
групповых ошибок. Для обнаружения
групповых ошибок эффективно используется
матричный код, который разбивает
комбинацию на матрицу, состоящую из
определенного количества столбцов и
рядков. 
Контрольные символы хki определяется сумой по модулю 2 символов расположенных в столбце
П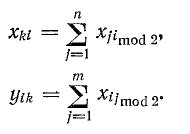 ри
ошибке, длина которой не больше длинны
рядка, в каждую проверку при приеме
сообщения будут входить не более одного
искаженного символа и эти ошибки будут
обнаружены. Для повышения обнаруживающей
способности проверку можно делать по
строкам и по столбцам, для еще более
точного обнаружения можно использовать
диагональные проверки. Недостаток
такого кодирования в том, что для
формирования матрицы нужно время,
которое будет вносить задержку в передачу
информации.
ри
ошибке, длина которой не больше длинны
рядка, в каждую проверку при приеме
сообщения будут входить не более одного
искаженного символа и эти ошибки будут
обнаружены. Для повышения обнаруживающей
способности проверку можно делать по
строкам и по столбцам, для еще более
точного обнаружения можно использовать
диагональные проверки. Недостаток
такого кодирования в том, что для
формирования матрицы нужно время,
которое будет вносить задержку в передачу
информации.
9.1 Энтропия непрерывных сообщений
Непрерывные сообщения могут принимать любые значения в некоторых приделах и являются непрерывными функциями времени.
Особенностью непрерывных сообщений является то, что вероятность появления каждого из отдельных значений равна нулю.
С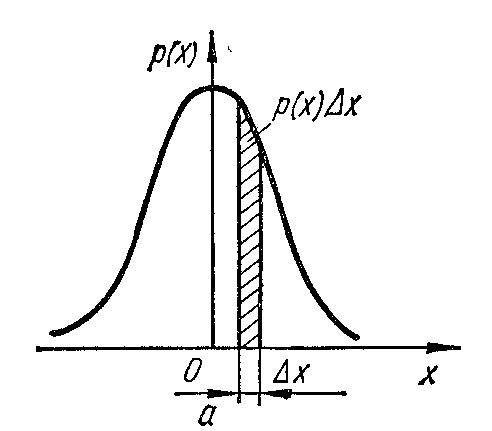 татистические
свойства непрерывной величины
характеризуют функцией плотности
вероятности распределения ее значений
р
(х). Функцию
р
(х) называют также
дифференциальным законом распределения
величины х. Данная
функция характеризует вероятность
попадания непрерывной
случайной величины х
в
некоторый элементарный интервал значений
Δx. Эта вероятность определяется
произведением р(х)Δx;
и стремится
к нулю при уменьшении ширины интервала.
Таким образом энтропия
татистические
свойства непрерывной величины
характеризуют функцией плотности
вероятности распределения ее значений
р
(х). Функцию
р
(х) называют также
дифференциальным законом распределения
величины х. Данная
функция характеризует вероятность
попадания непрерывной
случайной величины х
в
некоторый элементарный интервал значений
Δx. Эта вероятность определяется
произведением р(х)Δx;
и стремится
к нулю при уменьшении ширины интервала.
Таким образом энтропия

При уменьшении Δx; (увеличении m) первое слагаемое в пределе стремится к интегралу, пределом второго слагаемого
будет
— logΔx.
Таким
образом получим:
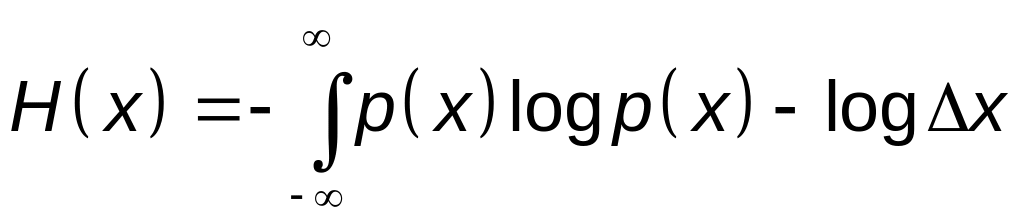 .
.
Информативность
непрерывных сообщений, обусловленная
их статистическими
свойствами, полностью определяется
первым слагаемым,
тогда как второе слагаемое зависит лишь
от выбранного интервала
Δx
и является постоянной величиной (при
постоянном Δx).
Первое
слагаемое называется дифференциальной
энтропией.
При
решении конкретных задач обычно
используется выражение для дифференциальной
энтропии без специальных оговорок, а
величина
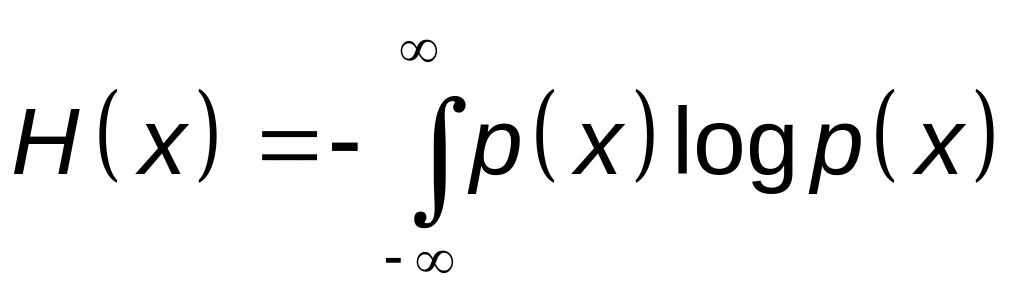 называется
энтропией и характеризует количество
информации, приходящейся
на один отсчет непрерывного сообщения.
называется
энтропией и характеризует количество
информации, приходящейся
на один отсчет непрерывного сообщения.