

2.1.1 Характеристика систем оптичного розпізнавання символів
Системи ОРС поділяються на дві групи: розпізнавання в реальному режимі часу і розпізнавання в пакетному режимі. Кожна з них характеризується як специфічною апаратною частиною так власними алгоритмами розпізнавання. У свою чергу у кожній з цих груп можна виділити два класи систем ОРС. Системи ОРС з розпізнаванням у реальному ружимі часу використовуються в автоматизованих системах, таких наприклад як системи автоматичного оброблення поштової кореспонденції. Пакетний режим ОРС використовується в системах автоматизації документообігу, для розпізнавання та перетворення паперових документів у цифрову форму. Найбільш відомим серед цього класу систем ОРС є FineReader. Це програмний продукт фірми ABBYY Software согодні може розпізнавати не тільки друковані а й рукописні тексти.
У типовій системі (OРС) зображення документу отримують за допомогою оптичного приладу. Це може бути сканер, цифрова фотокамера, відеокамера, спеціальна світлочутлива матриця тощо. Отримане зображення, піддається попередній обробці: згладжуванню, фільтрації та бінаризації. Оброблене зображення сегментується: виділяються рядки тексту, а потім у кожному рядку – символи. Після цього символи розпізнаються. Якість роботи OРC-систем в основному залежить від якості оригіналу, у випадку неякісних зображень істотно збільшується кількість помилок розпізнавання. У загальному випадку надійність розпізнавання OРC-систем складає 90-95%. Для відповідальних застосувань, таких як, наприклад, системи обробки паспортно-візової інформації надійність розпізнавання повинна бути не меншою чим 99%, незалежно від якості образу документа. У системах розпізнавання рукописних поштових індексів – вимоги ще більш жорсткі: помилка розпізнавання повинна складати не більш ніж 10-3%.
Системи ОРС за методами розпізнавання поділяються на два класи: шрифтозалежні та шрифтонезалежні системи.
У
шрифтозалежних системах роспізнавання
символів ґрунтується на методах та
алгоритмах порівняння з еталоном. Основу
цих систем складають бази еталонів
(зразків) символів різних найбільш
уживаних шрифтів. Розпізнавання
здійснюється за рахунок поелементного
(попіксельного) порівняння символу з
еталонами, за умови якщо тип шрифту
символу співпадає з одним із еталонних
шрифтів. Розглянемо схематично цю
процедуру, коли для розпізнавання
використовується лише один вид шрифту.
Для того щоб розпізнати символ його
зображення накладається на зображення
еталону (див. Рис. 2.1). Далі підраховується
кількість пікселів які співпали
![]() та кількість пікселів
та кількість пікселів
![]() ,
що не співпали. Потім обчислюється міра
подібності
,
що не співпали. Потім обчислюється міра
подібності
![]() (2.1)
(2.1)
Порівняння
символу та обчислення величини
здійснюється для всіх еталонів. При
цьому вважається, що символ
![]() співпав
з еталоном
співпав
з еталоном
![]() ,
якщо
,
якщо
![]() є максимальним.
є максимальним.
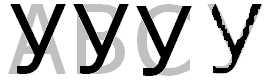
Рисунок .2.1.– Порівняння символу з еталонами.
На рис.
2.1 сірі букви – це еталони. Очевидно, що
для еталонів А,В та С буде від’ємним, а
для еталону У – додатнім і максимальним
навіть у випадку, коли розпізнається
символ зі спотвореннями форми. Звичайно,
що такий простий метод не забезпечить
високу надійність розпізнавання.
Розглянемо (див. рис. 2.2), наприклад,
ситуацію коли на вхід системи розпізнавання
надійшов спотворений символ ‘S’. У
цьому випадку, може статися так, що
![]() ,
тоді символ ‘S’ буде ідентифікований
неправильно як цифра 5.
,
тоді символ ‘S’ буде ідентифікований
неправильно як цифра 5.
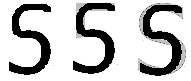
Рисунок 2.2 – Приклад можливого помилкового розпізнавання
Для того щоб запобігти подібним ситуаціям, елементам (пікселам) зображення еталону приписують вагові коефіцієнти. Ці вагові коефіцієнти обираються на підґрунті статистичного аналізу спотворень символів, так щоб вірогідність правильного розпізнавання була максимальною. Крім цього додатково застосовуються спеціальні процедури так званого контекстного дорозпізнавання.
Другий клас систем ОРС – безшрифтові або шрифтонезалежні, у яких використовуються інваріантні ознаки символів, тобто такі ознаки які не залежать від типу шрифта та розмірів символів. Ці інваріантні ознаки формуються на підгрунті статистичного аналізу ознак символів, при цьому процедуру їх формування називабть навчанням системи. Цей клас ОРС має ряд переваг та недоліків у порівннянні з шрифтозалежними системами:
1) Реально досяжна якість розпізнавання нижче, ніж у шрифтозалежних алгоритмів. Це зв'язано з тим, що рівень узагальнення при визначенні ознак символів набагато більш високий, ніж у випадку шрифтозалежних алгоритмів. Фактично це означає, що різні завади при визначенні ознак символів для роботи безшрифтових алгоритмів можуть бути в 2-20 разів більшими в порівнянні зі шрифтовими.
2) Неможливість формального та обґрунтованого визначення коефіцієнту надійності розпізнавання.
3) Універсальність. Це означає з однієї сторони можливість використання цього підходу у випадках, коли потенційна розмаїтість символів, що можуть надійти на вхід системи, велика. З іншого боку, за рахунок закладеної у ньому здатності узагальнення, такий алгоритм може екстраполювати накопичені знання за межі навчальної вибірки, тобто надійно розпізнавати символи, що по виду відрізняються від тих, які є присутні в навчальній вибірці.
3) Технологічність. Процес навчання шрифтонезалежних алгоритмів є більш простим та інтегрованим у тому сенсі, що навчальна вибірка не фрагментирована на різні класи (за шрифтами, кеглям і т.д.). При цьому немає необхідності підтримувати в базі ознак різні умови, що забезпечують сепарабельність класів (система унікального іменування і т.п.). Ознакою технологічності є також той факт, що часто вдається створити майже цілком автоматизовану процедуру навчання.
4) Зручність у процесі використання програми. У випадку, якщо програма побудована на шрифтонезалежних алгоритмах, користувач не зобов'язаний знати що-небудь про документ, що він хоче увести в комп'ютерну пам'ять і повідомляти про ці знання програму. Також спрощується користувальницький інтерфейс програми за рахунок відсутності набору опцій та діалогів, що обслуговують навчання і керування базою ознак. У цьому випадку процес розпізнавання для користувача – це “чорна скринька” (при цьому користувач не має можливості керувати або яким-небудь чином модифікувати хід процесу розпізнавання). Взагалі це приводить до розширення кола потенційних користувачів за рахунок включення в нього людей, що мають мінімальні комп'ютерні знання.
Будь-який алгоритм розпізнавання символів може застосовуватись на практиці при якості розпізнавання 95%. Остаточне доведення алгоритму до 100% надійності завжди є трудомісткою роботою. У цілому, шлях збільшення якості розпізнавання лежить не у винаході надінтелектуального алгоритму, що замінить собою всі інші, а в комбінуванні декількох алгоритмів, кожний з яких сам по собі простий та є ефективною обчислювальною процедурою. При комбінуванні різних алгоритмів важливо, щоб вони спиралися на незалежні джерела інформації про символи. У випадку, якщо два алгоритми обробляють сильно корельовані між собою дані, то замість збільшення якості розпізнавання буде збільшуватися остаточна помилка. З іншого боку, знання про розпізнані символи повинні накопичуватися і використовуватися в наступних кроках процесу розпізнавання. При цьому, як остаточний критерій можна використовувати точний шрифтозалежний алгоритм, база ознак якого побудована прямо в процесі роботи за результатами попередніх кроків розпізнавання. Метод, що має зазначені вище властивості, будемо називати адаптивним розпізнаванням, тому що він використовує динамічне настроювання (адаптацію) на конкретні вхідні символи.
Що стосується систем ОРС, які використовуються при автоматизації оброблення поштової кореспонденції, то історично першою було розроблено шрифтозалежну систему, яка розпізнає цифри у реальному режимі часу написані з використанням так званого стилізованого шрифту.