

1.5 Пошук та захоплення поштового індексу
Визначення орієнтації листа відносно зчитувального пристою має важливе значення у випадку використання високопродуктивних листосортувальних машин, де є надзвичайно важливою швидкість виділення поштового індексу та його розпізнавання. У цих машинах використовуються спеціальні пристрої, що орієнтують лист таким чином, щоб поштовий індекс пройшов повз зчитувальний пристрій.
У тому випадку, коли обробляється зображення всього конверту, його орієнтація може бути довільною. Необхідно лише розробити метод пошуку та виділення поштового індексу.
Одна з проблем, яка на сьогодні ще не має остаточного вирішення у контексті проблематики аналізу зображень, полягає у розробці методів, алгоритмів та застосувань щодо пошуку, локалізації та захоплення певних об’єктів на зображенні. Існуючі методи, а також алгоритми пошуку та локалізації заданих об’єктів на зображенні розробляються з урахуванням того, що об’єкт має попередньо відомі інваріантні характеристики. Наприклад, в системах ідентифікації особистості використовуються методи, які враховують інваріантні характеристики кольору обличчя та його деякі геометричні властивості. В системах оптичного розпізнавання текстової інформації рядки тексту та його символи локалізуються, переважно гістограмним методом.
Для того
щоб розробити метод та алгоритм
локалізації та захоплення поштового
індексу необхідно у першу чергу
визначитися з множиною його суттєвих
ознак. Для цього розглянемо ковариаційну
матрицю поштового індексу
![]() елементи якої будемо обчислювати по
формулі:
елементи якої будемо обчислювати по
формулі:
![]() (1.29)
(1.29)
де
![]() -
–та
координата
-го
піксела, що належить зображенню індексу,
величини
-
–та
координата
-го
піксела, що належить зображенню індексу,
величини
![]() – це відповідні середні значення або
координати центру мас індексу.
– це відповідні середні значення або
координати центру мас індексу.
Цю
матрицю можна подати у вигляді суми
ковариаційних матриць: рамки поштового
індексу
![]() та його цифр
та його цифр
![]() ,
тобто
,
тобто
![]() . (1.30)
. (1.30)
Відомо,
що мінімальне значення
![]() ,
де
,
де
![]() –
матрична норма, на множині коваріаційних
матриць
–
матрична норма, на множині коваріаційних
матриць
![]() довільних поштових індексів досягається,
якщо
довільних поштових індексів досягається,
якщо
![]() – середнє значення матриці ковариацій
на певній множині поштових індексів
потужності
.
Матрицю
– середнє значення матриці ковариацій
на певній множині поштових індексів
потужності
.
Матрицю
![]() поштового індексу також можна подати
у вигляді
поштового індексу також можна подати
у вигляді
![]() (1.31)
(1.31)
Тоді
![]() . (1.32)
. (1.32)
Тут ми
врахували, що
практично не відрізняється від
![]() .
Таким чином
.
Таким чином
![]() (1.33)
(1.33)
Звідси можна зробити висновок, що відмінність ковариаційних матриць поштових індексів переважно зумовлена відмінністю цифр у його написанні.
Відомо,
що для оцінки власних значень матриці
розмірності
![]() використовується співвідношення
використовується співвідношення
![]() ,
де
,
де
![]() ,
а
,
а
![]() .
.
У нашому
випадку для симетричної ковариаційної
матриці розмірності
![]() .
.
![]() (1.34)
(1.34)
Тоді із співвідношення (1) для оцінки власних значень ковариаційної матриці поштового індексу отримаємо, що
![]() (1.35)
(1.35)
Аналогічним
чином, для оцінки середніх значень
власних чисел
![]() отримаємо
отримаємо
![]()
Тоді, з урахуванням (2), отримаємо
![]() (1.36).
(1.36).
Отже як і випадку ковариаційних матриць, для матриць власних значень також буде виконуватись умова
![]() . (1.37)
. (1.37)
де
![]() – матриця середніх значень власних
чисел поштових індексів.
– матриця середніх значень власних
чисел поштових індексів.
Крім
цього, оскільки
![]() ,
буде мати місце співвідношення
,
буде мати місце співвідношення
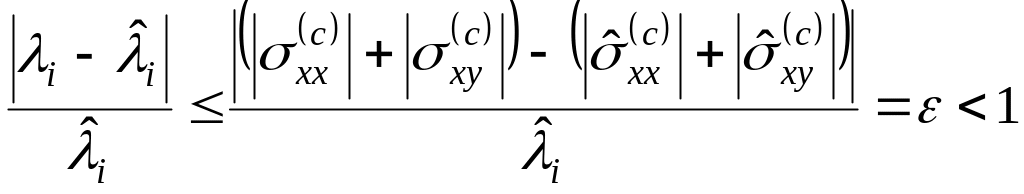 . (1.38)
. (1.38)
Виходячи з цього, у якості суттєвих ознак поштового індексу оберемо власні значення його ковариаційної матриці.
Таким чином метод локалізації та виділення поштового індексу буде полягати в наступному. В межах навчальної вибірки обчислимо власні числа ковариційної матриці
![]() (1.39)
(1.39)
та
знайдемо матрицю
,
яка буде визначати еталонні суттєві
ознаки поштового індексу. Зображення
конверту сканується маскою
![]() розміром
розміром
![]() пікселів. Розміри маски слід обрати так
щоб індекс цілком розміщувався в ній.
В межах маски розраховуються власні
значення ковариаційної матриці
пікселів. Розміри маски слід обрати так
щоб індекс цілком розміщувався в ній.
В межах маски розраховуються власні
значення ковариаційної матриці
![]() .
Для визначення подібності між
та
оберемо Евклідову норму. З метою економії
обчислювальних ресурсів уведемо
процедуру попереднього відбору
.
Для визначення подібності між
та
оберемо Евклідову норму. З метою економії
обчислювальних ресурсів уведемо
процедуру попереднього відбору
![]() підозрілих на те що в них міститься
індекс. Для цього в межах навчальної
вибірки розрахуємо середнє значення
щільності пікселів
підозрілих на те що в них міститься
індекс. Для цього в межах навчальної
вибірки розрахуємо середнє значення
щільності пікселів
![]() .
Враховуючи (11), будемо вважити що в
.
Враховуючи (11), будемо вважити що в
![]() можливо міститься індекс, якщо виконується
умова
можливо міститься індекс, якщо виконується
умова
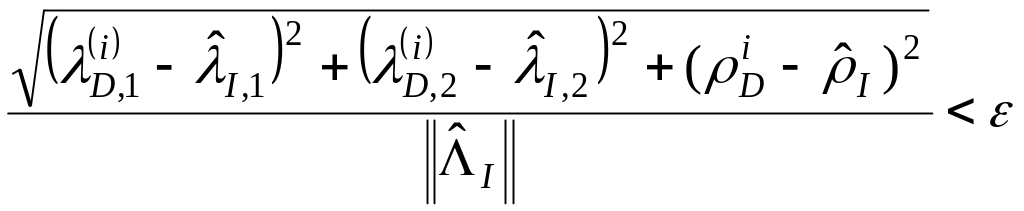 , (1.40)
, (1.40)
де
параметр
![]() обирається експериментально. Після
того як проскановане все зображення
конверту, з множини
обирається експериментально. Після
того як проскановане все зображення
конверту, з множини
![]() обираємо ту
обираємо ту
![]() ,
що задовольняє умові
,
що задовольняє умові
![]() (1.41)
(1.41)
При цьому координати розташування індексу визначаються координатами лівого верхнього кута маски .
Алгоритм локалізації та захоплення поштового індексу складається з наступних кроків (вважаємо що , та відомі):
Задати початкове положення маски на зображенні конверту, а саме координати її лівого верхнього кута
 .
.В межах маски
 обчислити власні значення
обчислити власні значення
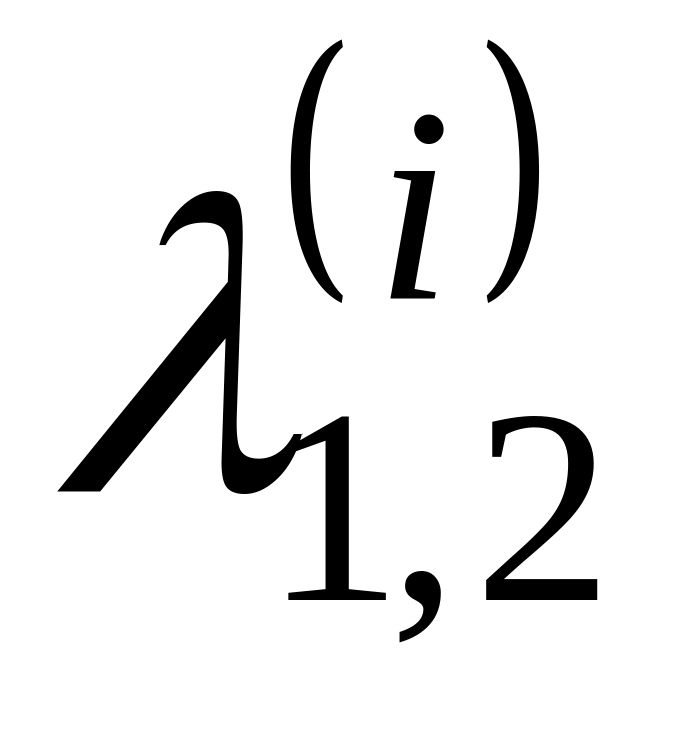 та
та
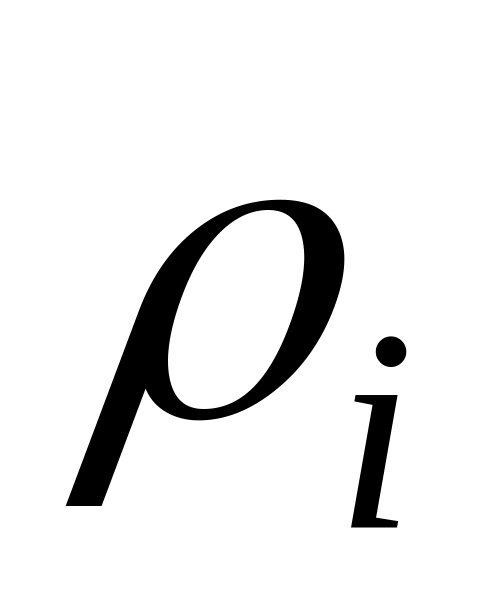 .
.Якщо виконується умова (13) запам’ятати та положення маски :
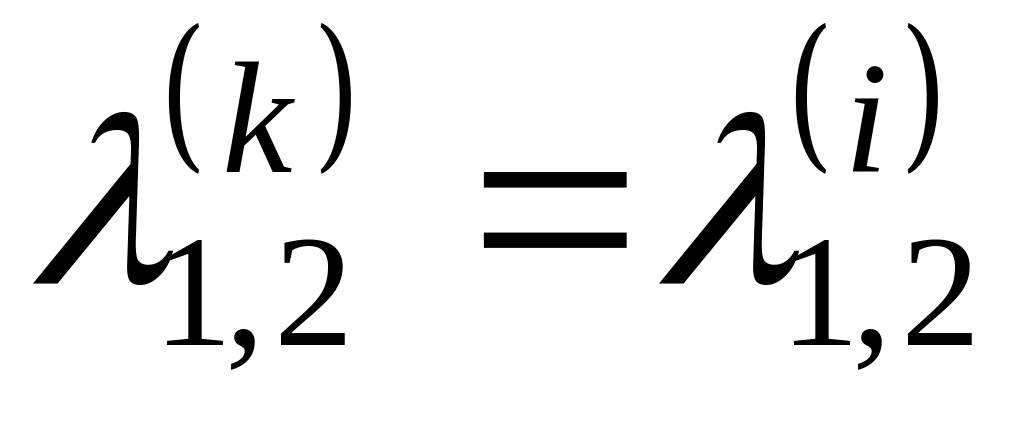 ,
,
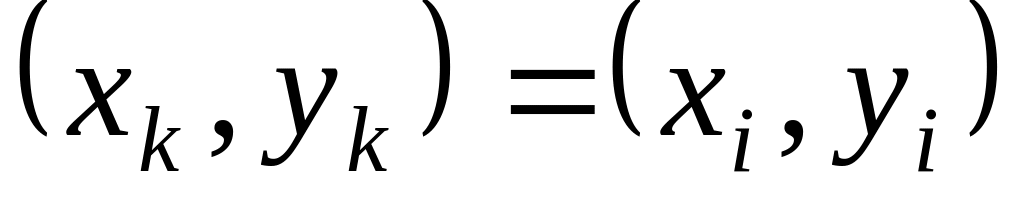 .
Збільшити
на одиницю.
.
Збільшити
на одиницю.Якщо проскановано ще не увесь конверт збільшити
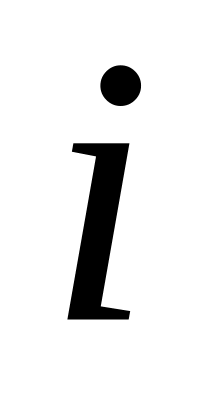 на
одиницю та визначити нове положення
маски, тобто координати
на
одиницю та визначити нове положення
маски, тобто координати
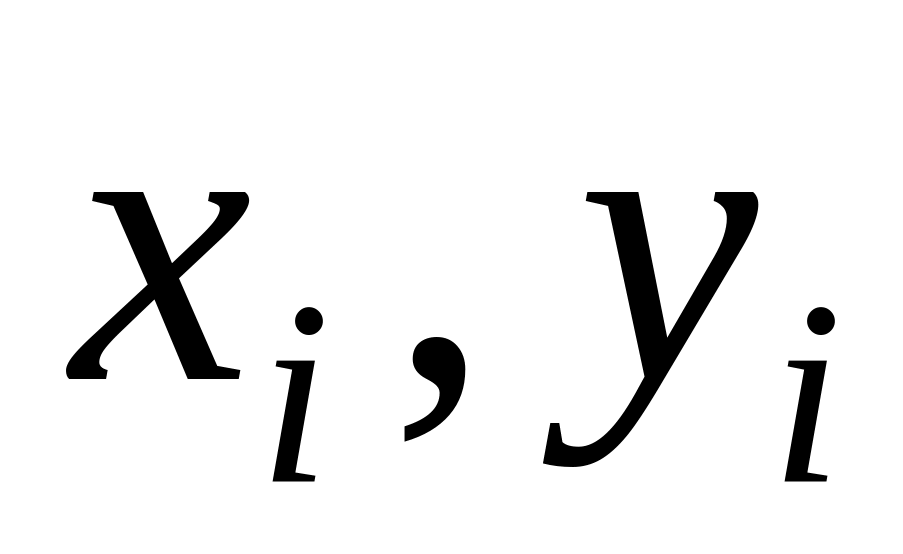 (при зміні положення маски використовуються
прирощення координат
(при зміні положення маски використовуються
прирощення координат
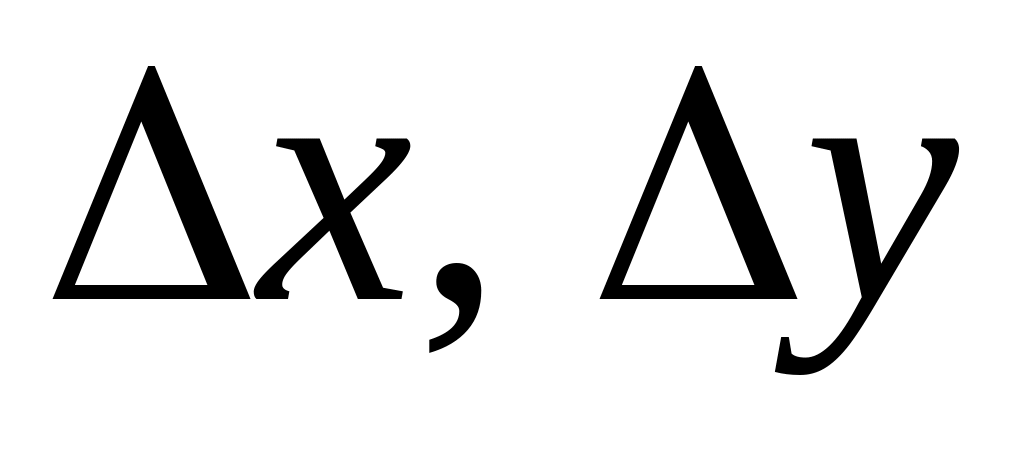 значення яких складають 10 пікселів).
Перейти до кроку 2.
значення яких складають 10 пікселів).
Перейти до кроку 2.Знайти таке
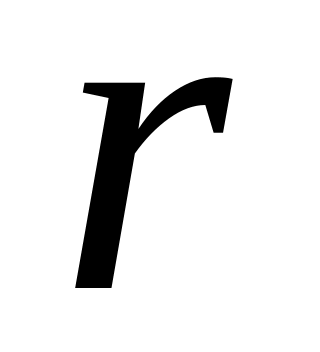 для
якого
для
якого
 .
Тоді індекс локалізований у масці яка
розташована на зображенні конверту у
положенні
.
Тоді індекс локалізований у масці яка
розташована на зображенні конверту у
положенні
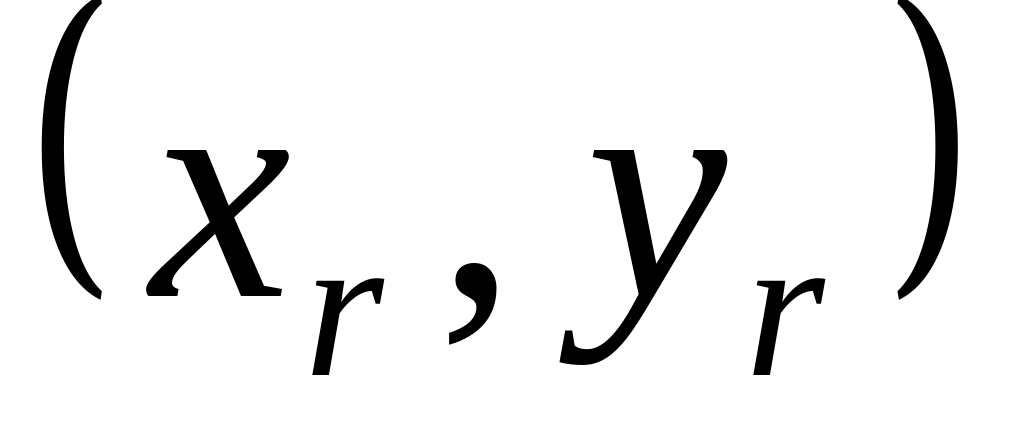 .
.
Для того
щоб реалізувати цей метод, необхідно
виконати додаткові дослідження, а саме
встановити середні значення власних
чисел та щільності чорних пікселів, що
будіть використовуватися у якості
еталонних ознак поштового індексу. Для
цього оброблялись виділені на зображенні
конверту у ручну поштові індекси. При
цьому розмір зображення індексу співпадав
з розмірами маски:
![]() пікселів.
пікселів.
У таблиці 1.7 наведені окремі результати обробки 60 зображень поштових індексів, для кожного з яких були розраховані коваріаційна матриця, власні значення та щільність чорних пікселів.
Таблиця 1.7 – Експериментальні результати встановлення еталонних ознак.
№ |
|
|
|
1 |
5726.765 |
342.685 |
0.114 |
2 |
6620.983 |
355.293 |
0.077 |
3 |
5981.063 |
309.570 |
0.081 |
4 |
6303.626 |
247.176 |
0.120 |
5 |
5976.008 |
309.855 |
0.081 |
6 |
6896.785 |
340.668 |
0.072 |
7 |
7550.370 |
340.451 |
0.053 |
8 |
6476.314 |
271.616 |
0.119 |
9 |
6205.145 |
239.331 |
0.106 |
10 |
6958.575 |
410.321 |
0.042 |
Як
свідчать наведені дані, власні значення
та щільність змінюються у проміжках
![]() ,
,
![]() ,
,
![]() ,
причому подальше збільшення обсягу
вибірки поштових індексі не приводить
до суттєвих змін отриманих результатів.
Тому будемо вважати що результати
обробки 60 поштових індексів є
репрезентативною вибіркою.
,
причому подальше збільшення обсягу
вибірки поштових індексі не приводить
до суттєвих змін отриманих результатів.
Тому будемо вважати що результати
обробки 60 поштових індексів є
репрезентативною вибіркою.
Виходячи
з отриманих даних було розраховані
математичні очікування власних значень
![]() та їх середньоквадратичні відхилення
та їх середньоквадратичні відхилення
![]() .
.
Середнє
значення щільності та її середньоквадратичне
відхилення складають:
![]() .
Крім цього в межах репрезентативної
вибірки було встановлено діапазон в
якому змінюються значенння відстані
Евкліда між еталоном та поточним індексом
.
Крім цього в межах репрезентативної
вибірки було встановлено діапазон в
якому змінюються значенння відстані
Евкліда між еталоном та поточним індексом
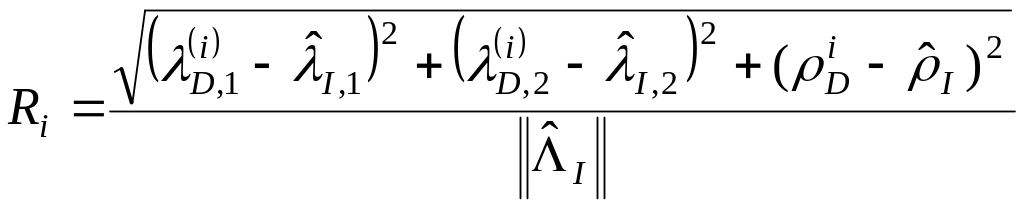 (1.42)
(1.42)
У випадку,
коли в масці міститься поштовий індекс
![]() .
.
На
другому етапі в результаті обробки
зображень конвертів з поштовим індексом
було встановлене значення параметру
![]() .
При цьому враховувалось, що в множині
є поштовий індекс якщо
.
При цьому враховувалось, що в множині
є поштовий індекс якщо
![]() .
На рис. 1.23 наведена множина
серед елементів якої є індекс.
.
На рис. 1.23 наведена множина
серед елементів якої є індекс.

Рисунок 1.23 – Області зображення конверту «схожі» на індекс
Для того
щоб, остаточно локалізувати, в межах
зображення конверту, а потім захопити
поштовий індекс аналізується
![]() ,
з використанням умови (14), та встановлюється
положення індексу.
,
з використанням умови (14), та встановлюється
положення індексу.
На рис. 1.24 наведено результат локалізації та захоплення поштового індексу з використанням розробленого застосування.
Експериментальна перевірка локалізації та захоплення області з поштовим індексом проводилась на множині трьох сотень реалістичних зображень конвертів. При цьому у 99.5% випадків було правильно локалізовано та захоплено поштовий індекс. Помилки в локалізації індексу були зумовлені завадами на оригіналі – неповністю пропечатана рамка поштового індексу, а також наявністю радіометричних спотворень.
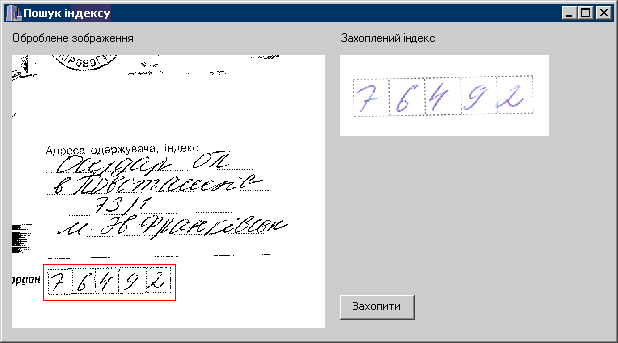
Рисунок 1.24 – Остаточна локалізація та виділення індексу
Для того щоб не визначатись з орієнтацією конверту необхідно приблизно встановити область де розташований поштовий індекс у випадку коли конверт має нормальну орієнтацію та у випадку коли конверт повернутий на 1800. Зображення конверту сканується обраною маскою у цих областях, та виділяється поштовий індекс. Якщо він розташований у верхній частині зображення конверту то його необхідно повернути на 1800.
Отримане зображення поштового індексу обробляється для того щоб виділити цифри, що входять до його складу. Потім цифри розпізнаються.