

4.2.4 Проведення експерименту і обробка його результатів
Після планування проводять безпосередньо сам експеримент. Для
кожного прийнятого поєднання факторів вимірюють значення параметрів оптимізації. За цими значеннями вже відразу приблизно видно, комбінація яких значень факторів є найкращою (близькою до оптимальної), а яка найгіршою. Однак перед тим, як перейти до оптимізації, необхідно виконати низку операцій з аналізування отриманих даних [7].
Насамперед, потрібно враховувати, що результати кожного досліду мають статистичну невизначеність. Вона існує за рахунок похибки вимі-рювання значень факторів і самого параметра Y, впливу неврахованих фак-торів і т.п. Тому якщо відтворити декілька разів дослід при одних і тих самих значення факторів, то кожний раз значення параметра оптимізації Y будуть різними. Звичайно, що дослідники намагаються при кожному сполученні значень факторів (“в кожній точці”) проводити по декілька повторних дослідів (n). Спочатку проводять обробку дослідів за звичайними формулами:
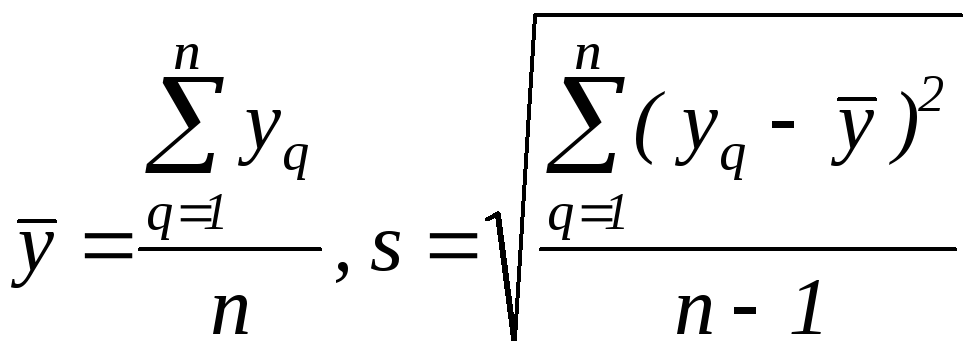 .
(4.56)
.
(4.56)
де q – поточний номер повторного досліду (із загальної кількості n) при визначеному поєднанні значень факторів.
Потім можна порівнювати дві будь-які серії по n дослідів: щоб оцінити їх значимість, тобто зрозуміти суттєво чи ні відрізняються значення y при двох комбінаціях значень факторів (“в двох точках”); щоб визначити, чи дійсно ця відмінність мала порівняно з розкидом при відтворенні n дослідів при одних і тих самих значеннях факторів. Якщо в кожній точці похибки дослідів практично однакові, то використовується t-критерій (критерій Стьюдента):
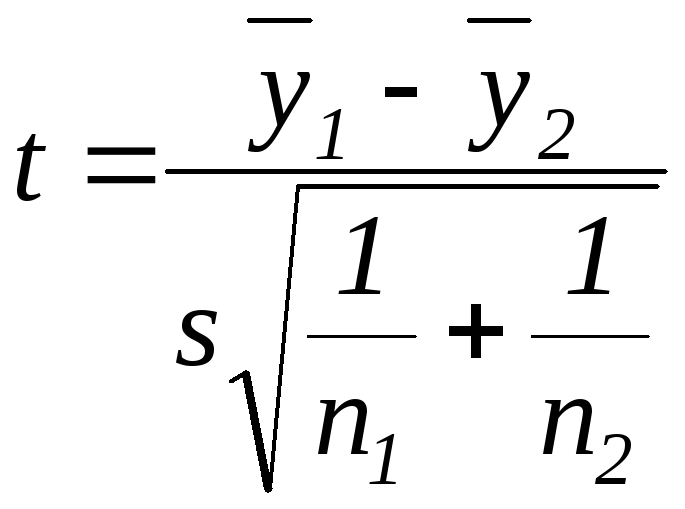 ,
(4.57)
,
(4.57)
![]() -
середнє значення
-
середнє значення
![]() дослідів при визначеному поєднані
значень фак-торів;
дослідів при визначеному поєднані
значень фак-торів;
![]() -
середнє значення
-
середнє значення
![]() дослідів при іншому поєднані значень
факторів
дослідів при іншому поєднані значень
факторів
s-
розкид значень y
(однаковий
в
![]() і
і
![]() )
дослідах.
)
дослідах.
Обчислене
значення t порівнюють з табличним, яке
знаходять для кількості ступенів свободи
![]() і рівня значимості
(часто приймають
і рівня значимості
(часто приймають
![]() ).
Якщо розрахункове значення t
менше табличного, то з вірогідністю
).
Якщо розрахункове значення t
менше табличного, то з вірогідністю
![]() можна вважати, що різниці між серіями
дослідів
можна вважати, що різниці між серіями
дослідів
![]() і
і
![]() немає, тобто їх відмінність незначна.
немає, тобто їх відмінність незначна.
Обробка експериментальних результатів, врахування при необхідно-сті декількох складових похибок, виключення грубих помилок і т.п. вико-нується за методом теорії похибок .
Крім
дисперсії
![]() в серії з n
дослідів обчислюється також загальна
дисперсія параметра оптимізації
в серії з n
дослідів обчислюється також загальна
дисперсія параметра оптимізації
![]() ,
яка інакше називається дисперсією
відтворюваності експерименту
,
яка інакше називається дисперсією
відтворюваності експерименту
![]() .
Цю дисперсію визначають за формулою:
.
Цю дисперсію визначають за формулою:
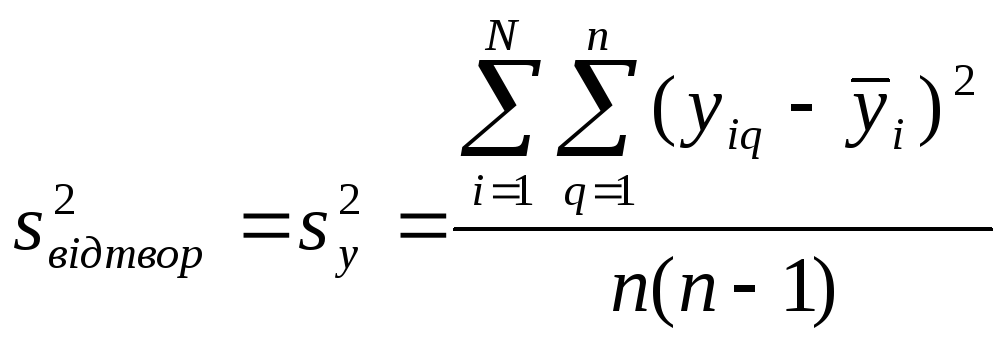 ,
(4.58)
,
(4.58)
де i=1, 2, 3, …, N;
q=1, 2, 3, …,
n- кількість повторних дослідів, однакова по всій матриці.
При різній кількості дослідів n доводиться користуватися середнім зваженим значенням дисперсій, взятим з урахуванням кількості степенів свободи:
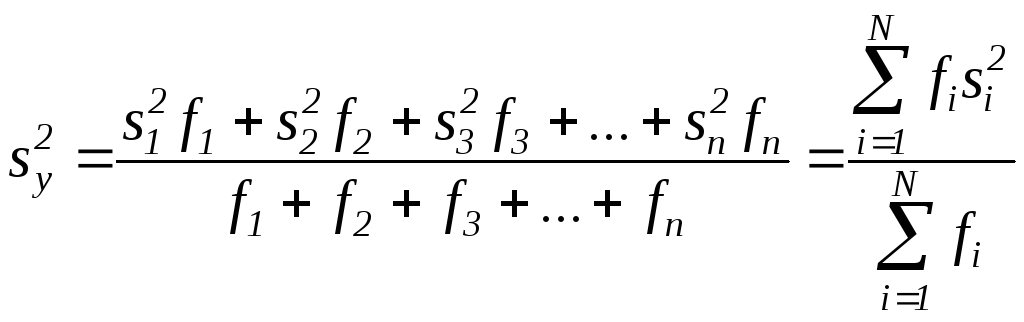 ,
(4.59)
,
(4.59)
де f1 - кількість ступенів свободи в кожній серії дослідів (f1=n-1).
Остання формула справедлива тільки в тому випадку, коли дисперсії si однорідні, тобто, серед них немає таких, які значно перевищують всі інші. Перевірку однорідності часто проводять за різними критеріями. Для двох дисперсій застосовують критерій Фішера (F-критерій), який є відношенням більшої дисперсії до меншої. Якщо отримані значення відношення більше наведеного в таблиці для відповідних ступенів свободи і, відповідно, до вибраного рівня значимості, то дисперсії суттєво відрізняються одна від одної, тобто вони неоднорідні.
Приклад. Нехай
![]() ;
;
![]() .
.
Розв’язок.
Критерій Фішера
![]() .
.
Для ступенів свободи f1=6, f2=5 і рівня значимості 0,05 з таблиці А1 знаходимо значення 4,95. Значить, дисперсії неоднорідні.
Якщо
порівнювана кількість дисперсій більша
двох і одна дисперсія значно перевищує
решту, можна скористатися критерієм
Кохрена.
Цей критерій використовується у
випадках, коли кількість дослідів у
всіх точках однакова. При цьому
обчислюється дисперсія в кожному
горизонтальному рядку матриці
![]() .
Потім з усіх дисперсій вибирають
найбільшу
.
Потім з усіх дисперсій вибирають
найбільшу
![]() ,
яку ділять на суму всіх дисперсій.
Критерій Кохрена
G
знаходять за формулою
,
яку ділять на суму всіх дисперсій.
Критерій Кохрена
G
знаходять за формулою
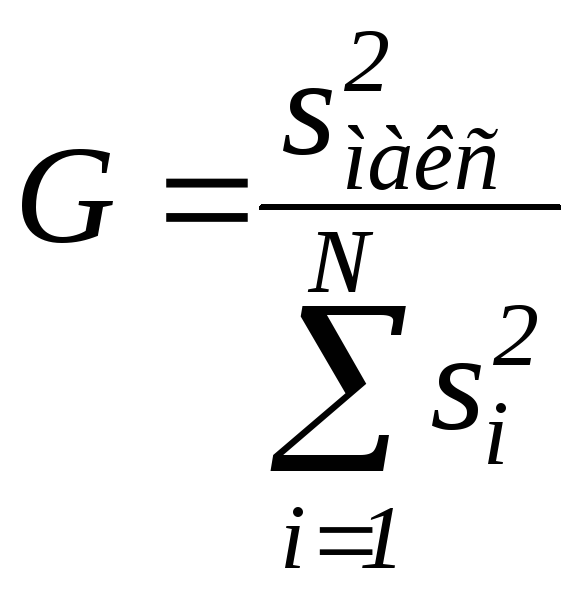 (4.60)
(4.60)
і порівнюють з табличним значенням. Якщо табличне значення більше, ніж розраховане за цією формулою, то дисперсії однорідні (табл. А.2).
Приклад. Для результатів експерименту
![]() .
(4.61)
.
(4.61)
Таблиця 4.12 - Результати експерименту
|
№ досліду |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
|
|
1,444 |
1,444 |
0,062 |
1,62 |
0,046 |
0,246 |
0,246 |
0,106 |
Табличне
значення
![]() ,
тобто більше розрахункового. Отже,
дисперсії однорідні:
,
тобто більше розрахункового. Отже,
дисперсії однорідні:
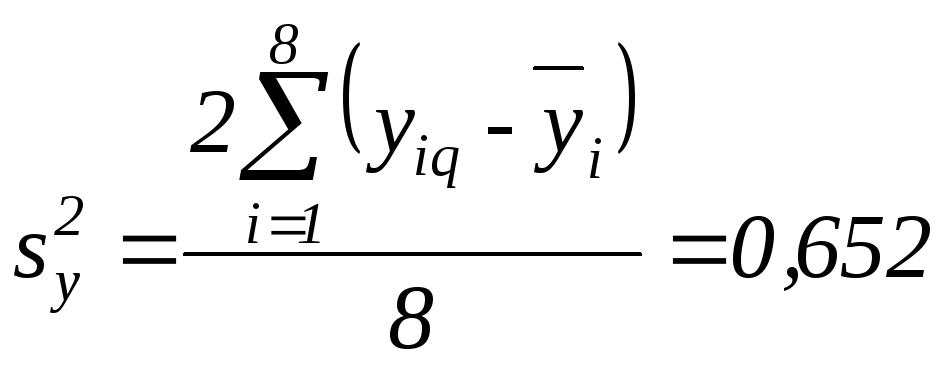 .
(4.62)
.
(4.62)
Якщо ж виникає припущення про наявність неоднорідності дисперсій, то цю неоднорідність потрібно перевірити. Для цього можна скористатися критерієм Бартлета (для розподілу, близького до нормального). Він доволі складний, тому іноді використовують (для кількості дисперсій більше двох) критерій Фішера. Тоді порівнюють з усієї низки дисперсій найбільшу і найменшу дисперсії. Якщо вони дещо відрізняються, то це означає, що всі дисперсії однорідні.
Щоб уникнути впливу систематичних похибок, викликаних зовнішніми умовами (фактори, що стають на заваді), необхідно досліди, які заплановані матрицею, проводити у випадковій послідовності. Цей прийом називається рандомізацією. Найпростіший спосіб полягає у використанні таблиці випадкових чисел, за якою вибирається послідовність проведення всіх дослідів, включаючи і ni дослідів в кожній точці.
Іншій підхід полягає в розбиванні матриці на блоки. Якщо експери-ментатор знає про зміну зовнішніх умов, він може планувати експеримент так, щоб ефект впливу цих умов був пов’язаний з визначеним впливом, яким можна знехтувати. Наприклад, матрицю 23 можна розбити на два блоки таким чином, щоб ефект впливу умов позначився на величині трифакторної взаємодії, а усі лінійні коефіцієнти і парні взаємодії були вільні від цього впливу.
Після проведення експерименту проводять аналіз адекватності (відповідності) вибраної моделі (виду полінома) дослідним даним. Потім перевіряють значимість коефіцієнта за t-критерієм Стьюдента або побудовою довірчих інтервалів.