

-
Переборные алгоритмы
Рассмотрим переборные алгоритмы, основанные на методах обхода графа (см. п. 3.6.2) на примере задачи нахождения кратчайшего пути в лабиринте. Поскольку существует два метода обхода графа, то и переборных алгоритмов будем рассматривать два.
Лабиринт, состоящий из проходимых и непроходимых клеток, задан матрицей A размером mn. Элемент матрицы A[i, j]=0, если клетка (i, j) проходима. В противном случае A[i, j]=.
Требуется найти кратчайший путь из клетки (1, 1) в клетку (m, n).
Фактически дана инвертированная матрица смежности (в ней нули заменены , а единицы – нулями). Лабиринт представляет собой граф.
Метод перебора с возвратом (по-английски называемый backtracking) основан на методе поиска в глубину. Перебор с возвратом – это метод проб и ошибок («попробуем сходить в эту сторону: не получится – вернемся и попробуем в другую»). Поскольку речь идет о переборе вариантов методом поиска в глубину, то во время работы алгоритма надо хранить текущий путь в дереве. Этот путь представляет собой стек Way. Кроме того, необходим массив Dest, размерность которого соответствует количеству вершин графа, хранящий для каждой вершины расстояние от нее до исходной вершины.
Вернемся к нашей задаче. Пусть текущей является некоторая клетка (в начале работы алгоритма – клетка (1, 1)). Далее
if для текущей клетки есть клетка-сосед Neighbor, такая что:
(отсутствует в Way) and
(Dist[Neighbor]=0 or (Dist[Neighbor] > Length(Way))) then begin
добавить Neighbor в Way;
текущая клетка := Neighbor;
end else
извлечь из Way;
Из приведенного выше фрагмента ясно, почему этот метод называется перебором с возвратом. Возврату здесь соответствует операция «извлечь из Way», которая уменьшает длину Way на 1.
Перебор заканчивается, когда Way пуст и делается попытка возврата назад. В этой ситуации возвращаться уже некуда.
Way – это путь текущий, но в процессе работы необходимо хранить еще и оптимальный путь OptimalWay.
Заметим, что алгоритм можно усовершенствовать, если не позволять, чтобы длина Way была больше или равна длине OptimalWay. В этом случае если и будет найден какой-то вариант большей длины, он заведомо не будет оптимальным. Такое усовершенствование в общем случае означает, что как только текущий путь станет заведомо неоптимальным, надо вернуться назад. В некоторых случаях это улучшение алгоритма позволяет сильно сократить перебор.
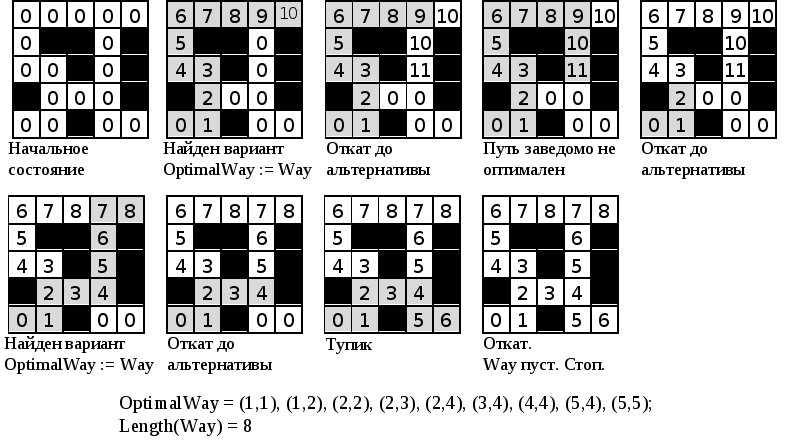
Рисунок 55. Перебор методом поиска в глубину
Переборный алгоритм, основанный на поиске в ширину, состоит из двух этапов:
-
распространение волны;
-
обратный ход.
Распространение волны и есть собственно поиск в ширину (см. п. 3.6.2.2), при котором клетки помечаются номером шага метода, на котором клетка посещается. При обратном ходе, начиная с конечной вершины, идет восстановление кратчайшего пути, по которому в нее попали путем включения в него клеток с минимальной пометкой. Важно, что восстановление начинается с конца (с начала оно зачастую невозможно).
Надо сказать, что перебор методом поиска в ширину по сравнению с перебором с возвратом, как правило, требует больше дополнительной памяти, расходуемой на хранение информации нужной для построения пути при обратном ходе и пометки посещенных вершин, но и работает быстрее, так как совершенно исключается посещение одной и той же клетки более, чем один раз.
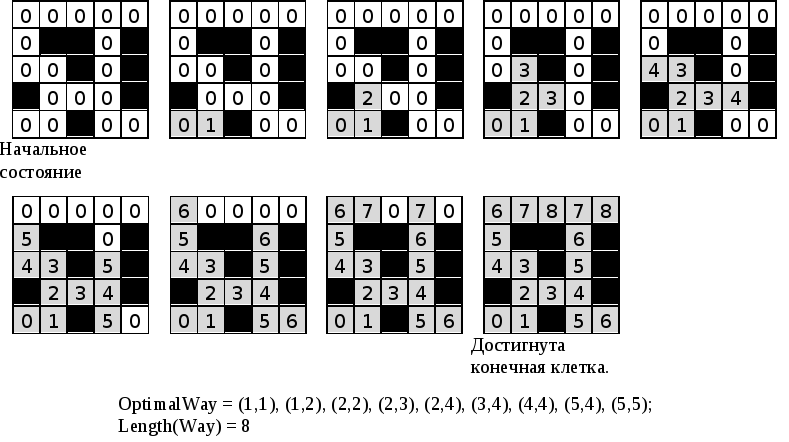
Рисунок 56. Перебор методом поиска в ширину