

-
Сортировка слиянием
Этот метод сортирует массив последовательным слиянием пар уже отсортированных подмассивов.
Пусть k – положительное целое число. Разобьем массив A[1]..A[n] на участки длины k. (Первый – A[1]..A[k], затем A[k+1]..A[2k] и т.д.) Последний участок будет неполным, если n не делится нацело на k. Назовем массив k-упорядоченным, если каждый из этих участков длины k упорядочен.
Ясно, что любой массив 1-упорядочен, так как его участки длиной 1 можно считать упорядоченными. Если массив k-упорядочен и n k, то он упорядочен.
Рассмотрим процедуру преобразования k-упорядоченного массива в 2k-упорядоченный. Сгруппируем все участки длины k в пары участков. Теперь пару упорядоченных участков сольем в один упорядоченный участок. Проделав это со всеми парами, получим 2k-упорядоченный массив:
Слияние требует вспомогательного массива B для записи результатов слияния. При слиянии сравниваем наименьшие элементы участков рассматриваемой пары, и меньший из них заносим в массив B. Повторяем описанные действия до тех пор, пока не исчерпается один из участков. После чего заносим в массив B все оставшиеся элементы другого участка. Затем переходим к следующей паре участков.
procedure MergeSort(n: integer;
var A: array[1..n] of integer);
{Процедура сортировки слиянием}
var
i, j, k, t, s, Start1, Fin1, Fin2: integer;
B: array[1..n] of integer;
begin
k := 1; {Начальное значение длины участков}
while k < n do begin {пока участок не весь массив}
t := 0; {начало 1-й пары участков}
while t+k < n do begin {пока не все участки просмотрели}
{Определяем границы рассматриваемых участков}
Start1 := t+1; Fin1 := t+k; {Начало и конец 1-го участка}
if t+2*k > n then Fin2 := n
else Fin2 := t+2*k; {Конец 2-го участка}
i := Start1; {Начальное значение индекса в 1-м участке}
j := Fin1 + 1; {Начальное значение индекса в 2-м участке}
s := 1; {Начальное значение индекса в массиве B}
{Заполняем B элементами из двух участков}
while (i <= Fin1) and (j <= Fin2) do begin
{Сравниваем попарно элементы из двух участков}
if A[i] < A[j] then begin
{Вставляем элемент из 1-го участка}
B[s] := A[i];
i := i + 1;
end else begin
{Вставляем элемент из 2-го участка}
B[s] := A[j];
j := j + 1;
end;
s := s + 1;
end;
{Добавляем в массив B оставшиеся элементы из 1-го участка}
while (i <= Fin1) do begin
B[s] := A[i];
i := i + 1; s := s + 1;
end;
{Добавляем в массив B оставшиеся элементы из 2-го участка}
while (j <= Fin2) do begin
B[s] := A[j];
j := j + 1; s := s + 1;
end;
t := Fin2; {Переходим к следующей паре участков}
end;
k := k * 2; {Удваиваем значение длины участков}
{Сохраняем полученный промежуточный результат}
for s := 1 to t do A[s] := B[s];
end;
end;
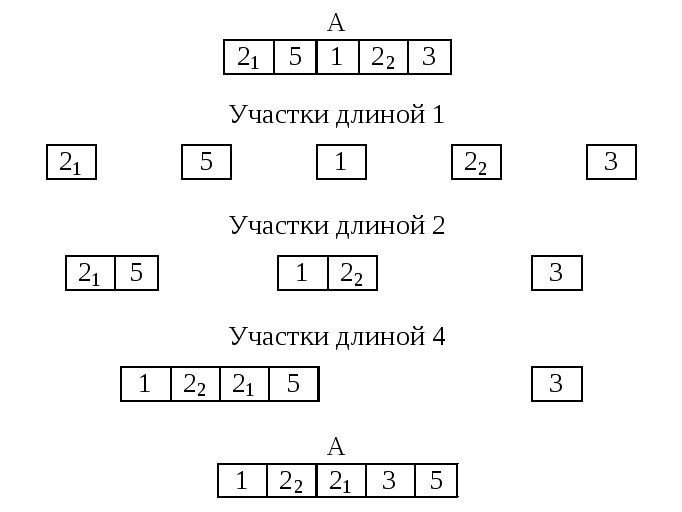
Рисунок 47. Сортировка слиянием
Сразу же бросается в глаза недостаток алгоритма – он требует дополнительную память размером порядка n (для хранения вспомогательного массива). Кроме того, он не гарантирует сохранение порядка элементов с одинаковыми значениями. Но его временная сложность всегда пропорциональна O(n*log n) (так как преобразование k-упорядоченного массива в 2k-упорядоченный требует порядка n действий и внешний цикл по k совершает порядка log n итераций).