

-
Организация
Существуют несколько способов организации данных в виде файлов:
-
последовательный файл;
-
хешированные файлы;
-
индексированные файлы;
-
B-деревья.
Первые три способа рассмотрим кратко прямо здесь, а использование B-деревьев рассмотрим далее более подробно.
При простой (и наименее эффективной) организации данных в виде последовательных файлов используются такие примитивы чтения и записи файлов, которые встречаются во многих языках программирования (например, read() и write() в языке Паскаль). В этом случае записи могут храниться в любом порядке.
Поиск записи осуществляется путем полного просмотра файла. Вставку в файл можно выполнять путем присоединения соответствующей записи в конец файла. В случае изменения записи, необходимо осуществить поиск требуемой записи, а затем в нее вносятся изменения.
При удалении записи то же необходимо найти удаляемую запись, а затем определенным вариантом удалить. Один из вариантов – сдвинуть все записи, следовавшие за удаленной записью, на одну позицию вперед (осуществляя при сдвиге перенос записей между блоками). Однако такой подход не годится, если записи являются закрепленными, поскольку указатель на i-ю запись в файле после выполнения такой операции будет указывать на (i+1)-ю запись. В этом случае необходимо определенным образом помечать уделенные записи, но не смещать оставшиеся на место удаленных (и не должны вставлять на их место новые записи). Существуют два способа помечать удаленные записи:
-
заменить значение записи на специальное значение, которое никогда не может стать значением неудаленной записи;
-
предусмотреть для каждой записи специальный бит удаления, который содержит, например, 1 в удаленных записях и 0 – в неудаленных записях.
Очевидным недостатком последовательного файла является то, что операции с такими файлами выполняются медленно. Выполнение каждой операции требует, чтобы осуществлялось чтение всего файла. Однако, существуют способы организации файлов, позволяющие обращаться к записи, считывая в основную память лишь небольшую часть файла. Такие способы предусматривают наличие у каждой записи файла так называемого ключа, то есть поля (или совокупности полей), которое уникальным образом идентифицирует каждую запись. К сожалению, при отсутствии ключей, ускорения операций добиться не удается.
Хеширование – широко распространенный метод обеспечения быстрого доступа к информации, хранящейся во внешней памяти. Основная идея этого метода подобна методу цепочек, который рассматривается в п. 3.3.2. Только здесь, вместо записей таблицы, организуется связный список блоков. Заголовок i-го содержит указатель на физический адрес (i+1)-го блока. Записи, хранящиеся в одном блоке, связывать друг с другом с помощью указателей не требуется. Сама таблица представляет собой таблицу указателей на блоки.
Такая структура оказывается вполне эффективной, если в выполняемой операции указывается значение ключа. В этом случае среднее количество обращений к блокам равно n/bk, где n – количество записей, b – количество записей в блоке, k – длина таблицы. Это в среднем в k раз меньше, чем в случае последовательного файла.
Чтобы вставить запись с ключом (запись с таким ключом отсутствует, так как значение ключа уникально), вычисляется хеш-функция по ключу, то есть определяется строка таблицы указателей, и просматривается соответствующая цепочка блоков. Для каждого блока осуществляется попытка вставки новой записи (при наличии свободного места в блоке). Если не удалось вставить ни в один блок цепочки, то у файловой системы запрашивается новый блок, который добавляется в конец цепочки и в него вставляется новая запись.
Чтобы удалить запись, также вычисляется строка таблицы указателей и находится запись в соответствующей цепочке блоков, а затем запись помечается как удаленная. Способы пометки записи здесь те же, что и в последовательных файлах. Если записи не являются закрепленными, то можно заменять удаляемую запись на последнюю запись в последнем блоке текущей цепочки. Если, в результате такой замены, последний блок стал пустым, то его можно вернуть файловой системе для повторного использования.
Еще одним распространенным способом эффективной организации файла записей является поддержание файла в отсортированном (по значению ключа) порядке. Чтобы облегчить процедуру поиска, можно создать второй файл, называемый разреженным индексом, который состоит из пар (x, b), где x – значение ключа, а b – физический адрес блока, в котором значение ключа первой записи равняется x. Этот индексный файл отсортирован по значению ключей.
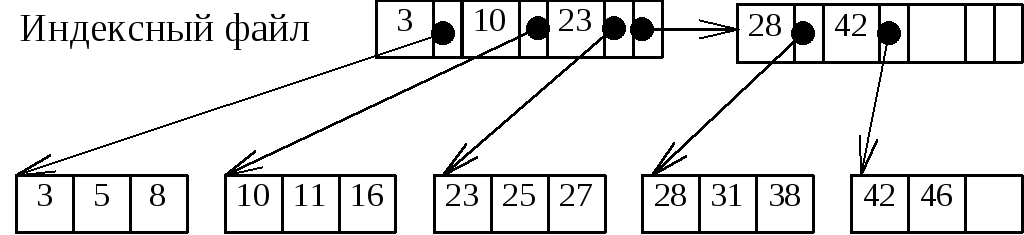
Рисунок 18. Разреженный индекс
Чтобы отыскать запись с заданным ключом x, необходимо сначала просмотреть индексный файл, отыскивая в нем пару (x, b), а затем ищется запись в блоке с физическим адресом b. Разработано несколько стратегий просмотра индексного файла. Простейшей из них является линейный поиск, более эффективным является двоичный поиск. Эти методы рассматриваются в п. 3.3.1. Для поиска записи необходимо считать один блок основного файла, и в зависимости от стратегии просмотра индексного файла просмотреть от n (при линейном поиске) до log2(n+1) (при двоичном поиске) блоков индексного файла, где n – общее количество блоков индексного файла.
Чтобы создать индексированный файл, записи сортируются по значениям их ключей, а затем распределяются по блокам в возрастающем порядке ключей. В каждый блок можно разместить столько записей, сколько в него помещается, но можно оставить место под записи, которые могут вставляться туда впоследствии (это уменьшает вероятность переполнения и, следовательно, обращение к смежным блокам.). После распределения записей по блокам, создается индексный файл. В нем также можно оставить место для новых индексов.
Чтобы вставить новую запись, с помощью индексного файла ищется соответствующий блок основного файла. Если новая запись умещается в найденный блок, то она вставляется в него в правильной последовательности. Если новая запись становится первой записью в блоке, то необходима корректировка индексного файла.
Если новая запись не умещается в найденный блок, то возможно применение нескольких стратегий. Простейшая из них заключается в том, чтобы перейти на следующий блок и узнать, можно ли последнюю запись найденного блока переместить в начало следующего. Если можно, то осуществляем перенос (освобождая место в найденном блоке), вставляем новую запись на подходящее место в найденный блок, корректируем индексный файл. Если следующий блок заполнен полностью или найденный блок является последним, то у файловой системы запрашиваем новый блок, помещаем его за найденным блоком, в новый блок вставляем новую запись и корректируем индексный файл.
Еще одним способом организации файла с использованием индексов является сохранение произвольного порядка записей в файле и создание другого файла, с помощью которого можно отыскивать требуемые записи. Этот файл называется плотным индексом. Плотный индекс состоит из пар (x, p), где p – указатель на запись с ключом x в основном файле. Эти пары отсортированы по значениям ключа. Поиск записи осуществляется подобно поиску с использованием разреженного индекса.
Если требуется вставить новую запись, отыскивается блок последний блок основного файла и туда вставляется новая запись. Если последний блок полностью заполнен, то запрашивается новый блок у файловой системы. Одновременно вставляется указатель на соответствующую запись в файле плотного индекса. Чтобы удалить запись, в ней просто устанавливается бит удаления и удаляется соответствующий указатель в плотном индексе.