

-
Кодовые деревья
Рассмотрим реализацию алгоритма Хаффмана с использованием кодовых деревьев. Кодовое дерево – это бинарное дерево, у которого:
-
листья помечены символами, для которых разрабатывается кодировка;
-
узлы (в том числе корень) помечены суммой вероятностей появления всех символов, соответствующих листьям поддерева, корнем которого является соответствующий узел.
Существует два подхода к построению кодового дерева: от корня к листьям и от листьев к корню. Рассмотрим первый подход в виде процедуры Паскаля. Входными параметрами этой процедуры являются массив используемых символов, отсортированный в порядке убывания вероятности появления символов (в начале идут символы с максимальными вероятностями, а в конце – с минимальными), а также указатель на создаваемое кодовое дерево, описание которого идентично описанию бинарного дерева в виде списков (см. п. 2.3.4.4), за исключением того, что поле Data здесь принимает символьный тип.
procedure CreateCodeTable(UseSimbol: TUseSimbol;
var CodeTree: PTree);
{Процедура создания кодового дерева по методу Хаффмана}
var
Current: PTree;
SimbolCount: integer;
begin
{Создаем корень кодового дерева}
new(CodeTree);
Current := CodeTree;
Current^.Left := nil; Current^.Right := nil;
SimbolCount := 1;
{Создаем остальные вершины}
while SimbolCount <= n-1 do begin
{Создаем лист с символом в виде левого потомка}
new(Current^.Left);
Current^.Left^.Data := UseSimbol[SimbolCount];
Current^.Left^.Left := nil; Current^.Left^.Right := nil;
{Создаем следующий узел в виде правого потомка}
new(Current^.Right);
Current := Current^.Right;
Current^.Left := nil; Current^.Right := nil;
SimbolCount := SimbolCount + 1;
end;
{Последний узел превращаем в лист с символом}
Current^.Data := UseSimbol[SimbolCount];
end;
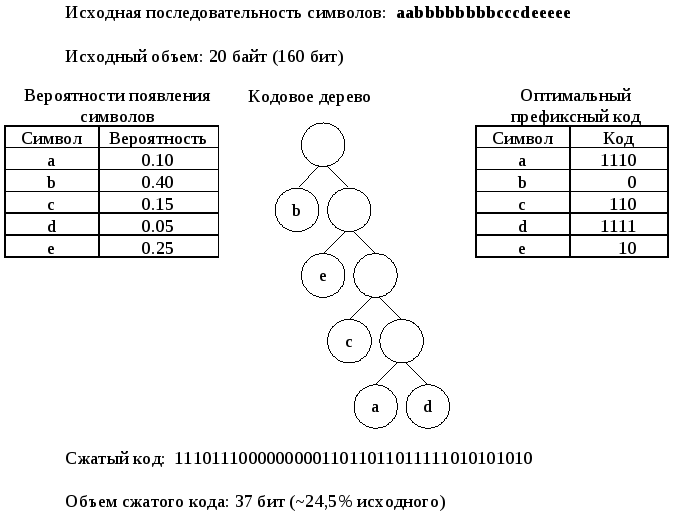
Рисунок 39. Создание оптимальных префиксных кодов
Созданное кодовое дерево может быть использовано для кодирования и декодирования текста. Как осуществляется кодирование уже говорилось выше. Теперь рассмотрим процесс декодирования. Алгоритм распаковки кода можно сформулировать следующим образом.
procedure DecodeHuffman(CodeTree: PTree; var ResultStr: string);
{Процедура декодирования по методу Хаффмана из некоторой битовой}
{последовательности в результирующую строку ResultStr}
var
Current: PTree; {Указатель в дереве}
CurrentBit, {Значение текущего бита кода}
CurrentSimbol: integer; {Индекс распаковываемого символа}
FlagOfEnd: boolean; {Флаг конца битовой послед-ти}
begin
{Начальная инициализация}
FlagOfEnd := false; CurrentSimbol := 1; Current := CodeTree;
{Пока не закончилась битовая последовательность}
while not FlagOfEnd do begin
{Пока не пришли в лист дерева}
while (Current^.Left <> nil) and
(Current^.Right <> nil) and
not FlagOfEnd do begin
{Читаем значение очередного бита}
CurrentBit := ReadBynary(FlagOfEnd);
{Бит – 0, то идем налево, бит – 1, то направо}
if CurrentBit = 0 then Current := Current^.Left
else Current := Current^.Right;
end;
{Пришли в лист и формируем очередной символ}
ResultStr[CurrentSimbol] := Current^.Data;
CurrentSimbol := CurrentSimbol + 1;
Current := CodeTree;
end;
end;
В приведенном алгоритме используется функция ReadBinary, которая читает битовую последовательность и возвращает целое значение 0, если текущий бит равен 0 и возвращает 1, если бит равен 1. Кроме того, она формирует флаг конца битовой последовательности: он принимает значение true, если последовательность исчерпана.
Для осуществления распаковки необходимо иметь кодовое дерево, которое приходится хранить вместе со сжатыми данными. Это приводит к некоторому незначительному увеличению объема сжатых данных. Используются самые различные форматы, в которых хранят это дерево. Здесь следует отметить, что узлы кодового дерева являются пустыми. Иногда хранят не само дерево, а исходные данные для его формирования, то есть сведения о вероятностях появления символов (или их количествах). При этом процесс декодирования предваряется построением нового кодового дерева, которое будет таким же, как и при кодировании.