

-
Реализация
Выбор структуры данных для хранения графа в памяти имеет принципиальное значение при разработке эффективных алгоритмов. Рассмотрим два матричных и три списочных представления графа:
-
матрица смежности;
-
матрица инцидентности;
-
списки смежных;
-
список ребер;
-
списки вершин и ребер.
При дальнейшем изложении будем предполагать, что вершины графа обозначены символьной строкой и всего их до n, а ребер – до m. Каждому ребру и каждой вершине сопоставлен вес – целое положительное число. Если граф не является помеченным, то считается, что вес равен единице.
Матрица смежности это двумерный массив размером n*n:
type
TAdjacencyMatrix = array [1..n, 1..n] of integer;
var
Graph: TAdjacencyMatrix;
При этом

Вес вершины указывается в элементах матрицы смежности, находящихся на главной диагонали, только в том случае, если в графе отсутствуют петли. Иначе, в этих элементах указывается вес петли.
Пространственная сложность этого способа V(n)~O(n2). Этот способ очень хорош, когда нам надо часто проверять смежность или находить вес ребра по двум заданным вершинам.
Матрица инцидентности это двумерный массив размером n*m:
type
TIncidenceMatrix = array [1..n, 1..m] of integer;
var
Graph: TIncidenceMatrix;
При этом
![]()
Пространственная сложность этого способа V(n, m)~O(n*m). Матрица инцидентности лучше всего подходит для операции «перечисление ребер, инцидентных вершине x».
Списки смежных это одномерный массив размером n, содержащий для каждой вершины указатели на списки смежных с ней вершин:
type
PNode = ^Node;
Node = record {смежная вершина}
Name: string; {имя смежной вершины}
Weight: integer; {вес ребра}
Next: PNode; {следующая смежная вершина}
end;
TAdjacencyList = array [1..n] of record
NodeWeight: integer; {вес вершины}
Name: string; {имя вершины}
List: PNode; {указатель на список смежных}
end;
var
Graph: TAdjacencyList;
Пространственная сложность этого способа Vmax(n)~O(n2). Хранение списков в динамической памяти позволяет сократить объем расходуемой памяти, так как в этом случае не будет резервироваться место под n соседей для каждой вершины. Можно и сам массив представить в виде динамического списка, но это не имеет особого смысла, так как граф, обычно, является статичной (неизменяемой) структурой.
Этот способ хранения лучше всех других подходит для операции «перечисление всех вершин смежных с x».
Перечень ребер это одномерный массив размером m, содержащий список пар вершин, инцидентных с одним ребром графа:
type
TBranchList = array [1..m] of record
Node1: string; {1-я вершина, инцидентная ребру}
Node2: string; {2-я вершина, инцидентная ребру}
Weight: integer; {вес ребра}
end;
var
Graph: TBranchList;
Пространственная сложность этого способа V(m)~O(m). Этот способ хранения графа особенно удобен, если главная операция, которой чаще всего выполняется, это перечисление ребер или нахождение вершин и ребер, находящихся в отношениях инцидентности.
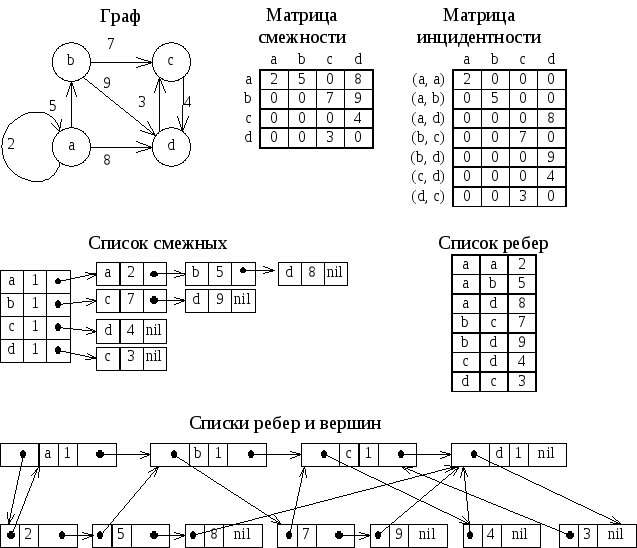
Рисунок 13. Граф и его реализации
Граф можно представить в виде списочной структуры, состоящей из списков двух типов – списка вершин и списков ребер.
type
PNode = ^TNode;
PBranch = ^TBranch;
TNode = record {вершина}
Name: string; {имя вершины}
Weight: integer; {вес вершины}
Branch: PBranch; {выходящее ребро}
Next: PNode; {следующая вершина}
end;
TBranch = record {ребро}
Node: PNode; {вершина, в которую входит}
Weight: integer; {вес ребра}
Next: PBranch; {следующее выходящее ребро}
end;
var
Graph: PBranch;
Пространственная сложность этого способа V(n, m)~O(n+m).