

-
Алгоритмы обхода графа
При решении многих задач, касающихся графов, необходимы эффективные методы систематического обхода вершин и ребер графов. К таким методам относятся:
-
поиск в глубину;
-
поиск в ширину.
Эти методы чаще всего рассматриваются на ориентированных графах, но они применимы и для неориентированных, ребра которых считаются двунаправленными.
-
Поиск в глубину
Поиск в глубину является обобщением метода обхода дерева в прямом порядке (см. п. 2.3.4.2).
Предположим, что есть ориентированный граф G, в котором первоначально все вершины помечены как непосещенные. Поиск в глубину начинается с выбора начальной вершины v графа G, и эта вершина помечается как посещенная. Затем для каждой вершины, смежной с вершиной v и которая не посещалась ранее, рекурсивно применяется поиск в глубину. Когда все вершины, которые можно достичь из вершины v, будут «удостоены» посещения, поиск заканчивается. Если некоторые вершины остались не посещенными, то выбирается одна из них и поиск повторяется. Этот процесс продолжается до тех пор, пока обходом не будут охвачены все вершины орграфа G.
Этот метод обхода вершин орграфа называется поиском в глубину, поскольку поиск непосещенных вершин идет в направлении вперед (вглубь) до тех пор, пока это возможно. Например, пусть x — последняя посещенная вершина. Для продолжения процесса выбирается какая-либо нерассмотренная дуга x y, выходящая из вершины x. Если вершина y уже посещалась, то ищется другая вершина, смежная с вершиной x. Если вершина y ранее не посещалась, то она помечается как посещенная и поиск начинается заново от вершины y. Пройдя все пути, которые начинаются в вершине y, возвращаемся в вершину x, то есть в ту вершину, из которой впервые была достигнута вершина y. Затем продолжается выбор нерассмотренных дуг, исходящих из вершины x, и так до тех пор, пока не будут исчерпаны все эти дуги.
Для представления вершин, смежных с вершиной v, можно использовать список смежных (см. п. 2.3.3.2), а для определения вершин, которые ранее посещались, — массив Visited:
Graph: TAdjacencyList;
Visited: array[1..n] of boolean;
Чтобы применить эту процедуру к графу, состоящему из n вершин, надо сначала присвоить всем элементам массива Visited значение false, затем начать поиск в глубину для каждой вершины, помеченной как false.
procedure DepthSearch(v: integer);
begin
Visited[v] := true;
for каждой вершины y, смежной с v do
if not Visited[y] then
DepthSearch(y);
end;
begin
while есть непомеченные вершины do begin
v := любая непомеченная вершина;
DepthSearch(v);
end;
end.
Поиск в глубину для полного обхода графа с n вершинами и m дугами требует общего времени порядка O(max(n, m)). Поскольку обычно m n, то получается O(m).

Рисунок 51. Поиск в глубину
-
Поиск в ширину (Волновой алгоритм)
Этот алгоритм поиска в графе также называют волновым алгоритмом из-за того, что обход графа идет по принципу распространения волны. Волна растекается равномерно во все стороны с одинаковой скоростью. На i-ом шаге будут помечены все вершины, достижимые за i ходов, если ходом считать переход из одной вершины в другую.
Метод поиска в ширину получается из программы поиска в глубину (см. п. 3.6.2.1), если заменить стек возврата на очередь. Эта простая замена модифицирует порядок обхода вершин так, что обход идет равномерно во все стороны, а не вглубь как при поиске в глубину.
Здесь используются те же структуры Graph и Visited, что были описаны в алгоритме поиска в глубину.
procedure WidthSearch(v: integer);
var
Delayed: array[1..n] of integer; {Очередь}
Count, {Хвост очереди}
Head: integer; {Голова очереди}
Current, j: integer;
begin
Count := 1; Head := 0; Delayed[Count] := v;
Visited[v] := true;
repeat
Head := Head +1; Current := Delayed[Head];
for каждой вершины y, смежной с Current do
if not Visited[y] then begin
Count := Count + 1;
Delayed[Count] := Graph[y];
Visited[y] := true;
end;
until Count = Head;
end;
begin
while есть непомеченные вершины do begin
v := любая непомеченная вершина;
WidthSearch(v);
end;
end.
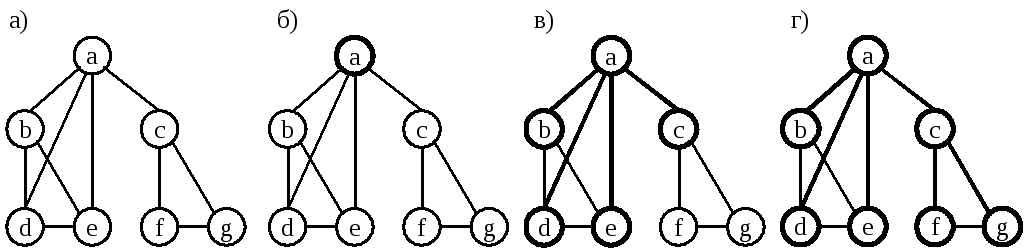
Рисунок 52. Поиск в ширину
Поиск в ширину для полного обхода графа с n вершинами и m дугами требует столько же времени, как и поиск в глубину, то есть времени порядка O(max(n, m)). Поскольку обычно m n, то получается O(m).