

Лабораторная работа № 10 Частотный анализ поэтических текстов по начальной букве
Стремительно ворвавшись в школьный курс и продолжая все глубже проникать в предметные области, информационные технологии позволяют не только по-новому взглянуть на процесс обучения, но порой дают возможность анализировать предмет, в данном случае поэзию, с новых позиций.
Рассмотрим применение информационного анализа поэтических текстов на примере произведений поэта Н.М.Рубцова.
Произведение Звезда полей поэта Николая Рубцова (1936-1971) впервые в школьной программе встречается в учебнике по литературе для 6-го класса общеобразовательных учреждений при изучении темы Родная природа в стихотворениях поэтов XX века. Здесь же для раскрытия этой темы приводятся соответствующие тексты стихотворений А. Блока (1880-1921), С. Есенина (1895-1925) и А. Ахматовой (1889-1966) [1].
Для того чтобы научить школьников шестого класса из стихотворных текстов выделять стихи о природе, в [1] предлагается найти и прочитать другие поэтические произведения о природе поэтов - классиков и современных поэтов.
В учебнике - хрестоматии для 7-го класса [2] при раскрытии темы Тихая моя родина, наряду с произведениями В. Брюсова (1873-1924), Ф. Сологуба (1863-1927), С. Есенина и Заболоцкого (1903-1958), Николай Рубцов представлен двумя стихотворениями - Тихая моя родина, Левитан (по мотивам картины «Вечерний звон»). Анализ стихотворений уже усложняется и ученикам предлагается указать литературные приемы, с помощью которых указанные авторы передают свое настроение через стихотворения о природе.
Наконец, в хрестоматии для 11-го класса тематика стихотворений Н. Рубцова расширяется, и школьники могут ознакомиться со следующими произведениями - «В минуту музыки», «Березы», «По дороге к морю», «Звезда полей», «Под ветвями больничных берез» [3].
В старших классах на уроках литературы учеников учат производить анализ произведений как исследовательское прочтение поэтического текста.
Однако изучение творчества того или иного поэта начинается ознакомлением с его биографией, так как «личное» всегда в той или иной мере отражается в произведениях автора.
Тот факт, что произведения Н. Рубцова вошли в школьные учебники по литературе в «окружении» русских поэтов - классиков, говорит о значимости его творчества.
Действительно, проанализируем текст его стихотворения «Березы»:
Я люблю, когда шумят берёзы,
Когда листья падают с берёз.
Слушаю – и набегают слёзы
На глаза, отвыкшие от слёз.
Всё очнётся в памяти невольно,
Отзовётся в сердце и в крови.
Станет как-то радостно и больно,
Будто кто-то шепчет о любви.
Только чаще побеждает проза,
Словно дунет ветер хмурых дней.
Ведь шумит такая же берёза
Над могилой матери моей.
На войне отца убила пуля,
А у нас в деревне у оград
С ветром и с дождём шумел, как улей,
Вот такой же жёлтый листопад…
Русь моя, люблю твои берёзы!
С первых лет я с ними жил и рос.
Потому и набегают слёзы
На глаза, отвыкшие от слёз.
(пос. Приютино, 1957)
Стихотворение "Берёзы" было написано в 1957 году, когда Николай Рубцов, проходя службу на флоте, находился в отпуске в селе Приютино Ленинградской области. Оно относится к ранней лирике, но, несмотря на относительную незрелость поэта, в стихах прослеживаются темы, которые впоследствии пройдут через все его произведения: тема Родины и тема его поколения.
Испытывая сильное влияние творчества Сергея Есенина с его "страной берёзового ситца", Рубцов соединяет образ России с картинами берёзовых рощ: "Я люблю, когда шумят берёзы…", "Русь моя, люблю твои берёзы!" Впоследствии образ "берёзовой Руси" мы встретим во многих произведениях поэта: "Счастье", "Северная берёза"(1957), "У знакомых берёз"(1968), "Под ветвями больничных берёз"(1970), "Ферапонтово"(1970), "Я умру, когда трещат берёзы"(1970).
Шум берёз и картина падающих осенних листьев вызывают у поэта щемящее чувство любви к своей родине и тоски по отчему дому: "слушаю – и набегают слёзы на глаза, отвыкшие от слёз".
Мать поэта умерла в самом начале войны, отец воевал на фронте, а после войны жил с другой семьёй. Известно, что поэт рос в детском доме, находившемся на родине его матери в селе Никольском, которое он и считал своей малой родиной. Поэтому мы видим по тексту стихотворения, что образ шумящих берёз "…отзовётся в сердце и крови", потому что - "с первых лет я с ними жил и рос".
Несмотря на то, что Николай Рубцов был сиротой при живом отце и с детства познал суровые стороны жизни, у поэта мы видим стремление быть, как все, не видеть в своей судьбе уникальности, а, напротив, отождествить её с судьбой многих детей военного времени: могила матери, "на войне отца убила пуля"… Таким образом, одиночество и страдания, вызванные отсутствием отчего крова, трансформируются, перерастая в болезненную любовь к Родине, её святыням, в способность находить счастье и удовлетворение в общении с природой как с близким человеком: "…когда шумят берёзы, когда листья падают с берёз… станет как-то радостно и больно, будто кто- то шепчет о любви."
Интересно, что использование такого приёма, как повторение слов: "шумит такая же берёза" и в последующем четверостишии: "шумел… такой же желтый листопад" даёт возможность поэту соединить несоединенные в жизни судьбы родителей, доведя тему сиротства до обобщения.
Читая стихотворение, мы ощущаем русскую душу поэта не только в открывающихся перед нами образах, но и благодаря тому, что поэт использует здесь песенный приём, характерный для русского фольклора – повторение одинаковых слов в начале и в конце текста стихотворения: "…набегают слёзы на глаза, отвыкшие от слёз". Этот приём будет часто применяться автором на протяжении всей его творческой жизни. Известно, что Николай Рубцов часто исполнял свои стихи под аккомпанемент гитары. Вероятно, отсюда и родился приём, который дает возможность придать произведению законченность, округлость, приближая к жанру народной песни.
В заключение можно сказать, что в небольшом, камерном произведении, написанном в самом начале творческого пути, мы видим рождение характерных черт, поэтических образов и приёмов, которые в дальнейшем проявятся со всей полнотой в творчестве незаурядного русского поэта, представителя "эпохи шестидесятых", приложившего много сил, "чтоб книгу Тютчева и Фета продолжить книгою Рубцова" ("Я переписывать не стану…").
Такой литературоведческий анализ несомненно содержит элемент субъективизма, и он также не позволяет дать необъективную сравнительную оценку этого стихотворения с произведениями других поэтов, тексты которых используются для раскрытия указанных ранее тем.
Покажем, что такие несубъективные оценки можно производить с помощью информационных измерений.
Известно, что впервые числовые оценки поэтического текста выполнялись известным русским математиком Марковым А.А. в начале ХХ столетия. Сущность этих оценок сводилась к следующему: из романа Пушкина А.С. «Евгений Онегин» составлялся список всех слов, например, на начальную букву «а», затем, исходя из этого списка, подсчитывалась вероятность появления всех букв русского алфавита на втором месте после буквы «а», далее на третьем месте и т.д. По такой же схеме анализировались списки слов на другие начальные буквы.
Вероятностный процесс появления букв алфавита в определенных позициях слова Марков А.А. назвал случайным процессом, начинающимся с некоторого начального состояния. В указанном случае начальное состояние – это список слов на начальную букву «а».
В настоящее время в теории массового обслуживания такие случайные процессы стали называться цепями Маркова.
Следует заметить, что при анализе указанного произведения Маркову удалось накопить такой фактический материал по так называемым вероятностям перехода, который и по сей день служит надежной экспериментальной проверкой различных теорий массового обслуживания.
После исследований Маркова А.А. интерес к информационным измерениям текстов естественного языка возобновился только с установлением Шенноном следующей формулы для приближенных вычислений количественной меры информации
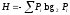 , (1)
где
через Pi
обозначена вероятность или частота
i-го события, а
суммирование производится по всем
значениям Рi.
, (1)
где
через Pi
обозначена вероятность или частота
i-го события, а
суммирование производится по всем
значениям Рi.
Величина Н измеряется в битах и ее часто называют энтропией информации. Формулу (1) стали применять при анализе кодов, используемых при передаче сообщений, составленных на каком-либо естественном языке.
Сам Шеннон не дал строгих правил вычисления частоты рi применительно к различным ситуациям. Некоторые исследователи под рi стали подразумевать частоты появления букв алфавита в текстах естественного языка, а величину Н стали трактовать как энтропию одной буквы текста. Измерения такого толка описаны, например, в [5].
В [6] описаны информационные измерения на основе формулы (1) в текстах различных естественных языков, но для вычисления частот предложены специальные схемы по угадыванию букв неизвестного текста.
Описанные информационные измерения устанавливают числовые характеристики естественного языка, которые имеют непосредственное отношение к проблеме передачи информации по различным линиям связи.
Однако в языкознании имеется направление, в рамках которого проводятся частотные измерения, выявляющие индивидуальность стиля писателя. Например, в одинаковых по объему текстах различных писателей производится частотный анализ появления слов метаязыка русского языка [7]. Так, при идентификации авторства романа «Тихий дон» в одном из Норвежских университетов частотный анализ использовался наряду с другими экспертными оценками.
Для применения формулы (1) в частотных измерениях литературных текстов необходимо ей придать иное толкование по сравнению с толкованием в теории передачи сообщений.
Действительно, для определения количественной меры детерминированной информации используется комбинаторная формула
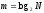 , (2)
связывающая
длину слова m с количеством
N слов этой длинны,
составленных из букв двоичного алфавита.
Американский исследователь Л.Хартли в
1928г. отождествил максимальное количество
информации Н с длиной слова m,
т. е.
, (2)
связывающая
длину слова m с количеством
N слов этой длинны,
составленных из букв двоичного алфавита.
Американский исследователь Л.Хартли в
1928г. отождествил максимальное количество
информации Н с длиной слова m,
т. е.
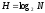 , (3)
, (3)
Предположим, что имеет место N слов как объем некоторой статистической выборки, состоящей из нескольких групп слов. Следуя [4], предположим, что в пределах каждой группы слова имеют одинаковую длину. Обозначим через ni объем каждой группы слов, тогда очевидно, что

По формуле (2) вычислим длину слова из группы n1, после будем иметь
![]() , (4)
, (4)
Теперь вычислим разность левых и правых частей в формулах (2) и (4):
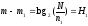 (5)
из
(5) известно, что Н1 суть длина не
идентифицированных слов.
(5)
из
(5) известно, что Н1 суть длина не
идентифицированных слов.
Аналогично можно составить следующие соотношения
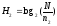 …,
…, 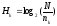 (6)
составим
среднюю статистическую сумму
(6)
составим
среднюю статистическую сумму
 ,
которую
с учетом (5)-(6) перепишем так:
,
которую
с учетом (5)-(6) перепишем так:
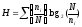 (7)
(7)
Если в каждой группе слов их число равно единице (n1=1) и число групп k равно N, то формула (7) переходит в формулу Хартли (3). В противном случае обозначим через рi частоту появления слов i-ой группы, которую определим общеизвестным способом
 (8).
(8).
Теперь после подстановки (8) в (7), получим формулу Шеннона (1).
Этот вывод формулы Шеннона впервые выполнен в [7], из которого следует, что Н есть статистическая средняя длина всех не идентифицированных слов, входящих в данную выборку N, а рi – частота, или вероятность появления этих слов.
В дальнейшем при использовании формулы (1) для расчета количественной меры информации поэтических текстов под рi будет подразумеваться частота появления слов по начальной букве русского алфавита. Процедуру такого расчета с использованием программ Microsoft Word и Microsoft Excel пакета Microsoft Office 97 продемонстрируем на примере текста стихотворения Николая Рубцова «Березы».
В
начале необходимо запустить программу
Microsoft Word,
ввести в компьютер текст стихотворения
и сохранить его с использованием
общеизвестных команд программы. Так,
для оформления текста стихотворения
по центру листа необходимо в меню
«Формат» ( )
выбрать команду «Абзац» и на вкладке
«Отступы и интервалы» установить отступ
слева 5-6 см, после чего щелкнуть мышью
на кнопке «ОК». В этом случае строка
начнется в 6-8 см от края листа. После
окончания набора строки стихотворения
нажимают клавишу «Enter».
Завершив набор стихотворения, измените
вид листа так, чтобы видеть лист целиком
на экране (меню «Вид» команда «Масштаб»,
устанавливаем переключатель «по ширине
страницы». Проверим визуально, расположено
стихотворение строго по центру или
смещено к одному из краев листа. Если
смещено, то выделяем стихотворение
(меню «Правка» команда «Выделить все»)
и изменяем отступ в нужную сторону.
)
выбрать команду «Абзац» и на вкладке
«Отступы и интервалы» установить отступ
слева 5-6 см, после чего щелкнуть мышью
на кнопке «ОК». В этом случае строка
начнется в 6-8 см от края листа. После
окончания набора строки стихотворения
нажимают клавишу «Enter».
Завершив набор стихотворения, измените
вид листа так, чтобы видеть лист целиком
на экране (меню «Вид» команда «Масштаб»,
устанавливаем переключатель «по ширине
страницы». Проверим визуально, расположено
стихотворение строго по центру или
смещено к одному из краев листа. Если
смещено, то выделяем стихотворение
(меню «Правка» команда «Выделить все»)
и изменяем отступ в нужную сторону.
Сохраняем стихотворение на диске.
1. Для дальнейшей работы с текстом необходимо заменить все пробелы символами конца строки. Для этого нужно в меню «Правка», выбрать команду «Заменить». В окне диалога «Заменить» после слова «Найти:» поставить пробел. Щелкнуть в белом поле после слов «Заменить на:». Нажать на кнопку «Больше» и затем на кнопку «Специальный». В открывшемся меню выбрать пункт «Разрыв строки». Если окно имеет вид, показанный на рис. 1, щелкнуть на кнопке «Заменить все», что позволит заменить все пробелы на символы конца абзаца.
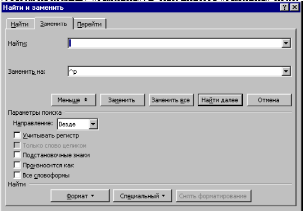
Рис.1
Текст стихотворения расположится вертикально столбиком (см. рис. 2.)
2.
Для переноса текста в программу Microsoft
Excel копируем весь текст
в буфер обмена (меню «Правка» команда
«Выделить все»), затем на команде
«Копировать» (![]() )).
Запускаем программу Microsoft
Excel. Щелкаем в ячейке А1 и
нажимаем кнопку «Вставить» (
)).
Запускаем программу Microsoft
Excel. Щелкаем в ячейке А1 и
нажимаем кнопку «Вставить» (![]() ).
Если все сделано правильно, то слова
стихотворения расположатся в столбик
в колонке А (см. рис. 3). Затем щелкнуть
на надписи Microsoft Word,
расположенной внизу экрана, после чего
в категории «Файл» выбираем команду
«Выход». На вопрос «Сохранить изменения
в файле?» ответить «Нет» (рис.4).
).
Если все сделано правильно, то слова
стихотворения расположатся в столбик
в колонке А (см. рис. 3). Затем щелкнуть
на надписи Microsoft Word,
расположенной внизу экрана, после чего
в категории «Файл» выбираем команду
«Выход». На вопрос «Сохранить изменения
в файле?» ответить «Нет» (рис.4).
Рис. 2
Рис. 3
3.
После закрытия программы Microsoft
Word возвращаемся в программу
Microsoft Excel и
производим автоматический выбор первой
буквы из всех слов текста. Для этого
необходимо щелкнуть в ячейке В1 и затем
на кнопке «Вставка функции» (![]() ).
В окошке «Вставка функции» в окошке
«Категории» выбрать «Текстовые», затем
в окошке «Функция» выбрать «ЛЕВСИМВ»
и щелкнуть на кнопке «ОК» (Рис. 5).
).
В окошке «Вставка функции» в окошке
«Категории» выбрать «Текстовые», затем
в окошке «Функция» выбрать «ЛЕВСИМВ»
и щелкнуть на кнопке «ОК» (Рис. 5). 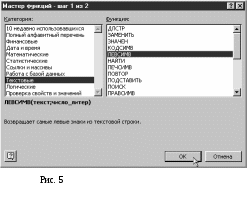
В
появившемся окошке после слова «Текст»
набрать «А1» (английский язык, без
кавычек) и щелкнуть на кнопке «ОК». В
ячейке В1 появится первая буква слова
из ячейки А1 (рис. 6).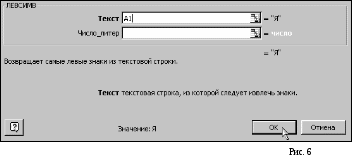
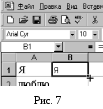
Размножить формулу из ячейки В1 вниз до конца слов в столбце А (рис.7). Проверить: если в ячейке в столбце А находится слово, то в той же строке в столбце В должна быть его первая буква. Если ячейка в столбце В пуста или в ней другой символ, необходимо щелкнуть на ячейке в столбце А и в строке формул стереть все символы слева от слова (на рис. 8 показаны правильные и неправильные (В4) результаты действий).
4.
Теперь для подсчета числа слов,
начинающихся на ту или иную букву,
необходимо организовать подсчет
количества конкретных букв в столбце
В.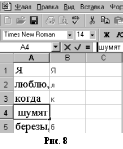
С этой целью в ячейках D1:Н30 формируем таблицу.
В
строке 1 оформляем заголовок таблицы,
введя в ячейку D1 текст №
п/п, в ячейку Е1 - Буква,
в ячейку F1 - Кол-во,
в ячейку G1 - Рi,
в ячейку Н1 - Pi*Log(Pi;2),
причем индекс делается так: набираются
оба символа, затем в строке формул
выделяется только символ, который
необходимо сделать индексом (рис. 9),
входим в меню «Формат», выбираем «Формат
ячейки» и ставим галочку (щелкнув мышкой
в квадратике рядом с надписью) «нижний
индекс». Нажимаем «ОК» (рис. 10).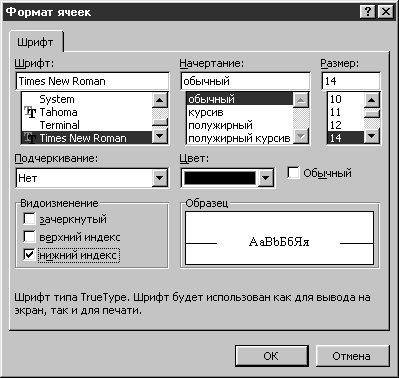
Рис. 10

Далее
заполняем колонку № п/п. Для этого в
ячейку D2
вводим 1, в ячейку D2
– 2, затем выделяем ячейки D2:D3
и размножаем вниз до цифры 28 (рис. 11).
Затем заполняем колонку «Буква» русскими буквами в порядке их традиционного расположения в алфавите. Сделать это можно так же, как и первую колонку (только для Office 97, в остальных версиях необходимо набрать алфавит вручную).
|
№ п/п |
Буква |
Кол-во |
Рi |
Pi*Lon2(Pi) |
|
1 |
а |
1 |
0,009434 |
0,063471 |
|
2 |
б |
6 |
0,056604 |
0,234507 |
|
3 |
в |
10 |
0,09434 |
0,32132 |
|
4 |
г |
2 |
0,018868 |
0,108074 |
|
5 |
д |
4 |
0,037736 |
0,178412 |
|
6 |
е |
0 |
0 |
0 |
|
7 |
ж |
4 |
0,037736 |
0,178412 |
|
8 |
з |
0 |
0 |
0 |
|
9 |
и |
6 |
0,056604 |
0,234507 |
|
10 |
к |
6 |
0,056604 |
0,234507 |
|
11 |
л |
6 |
0,056604 |
0,234507 |
|
12 |
м |
4 |
0,037736 |
0,178412 |
|
13 |
н |
9 |
0,084906 |
0,302094 |
|
14 |
о |
9 |
0,084906 |
0,302094 |
|
15 |
п |
7 |
0,066038 |
0,258905 |
|
16 |
р |
3 |
0,028302 |
0,145555 |
|
17 |
с |
13 |
0,122642 |
0,371295 |
|
18 |
т |
4 |
0,037736 |
0,178412 |
|
19 |
у |
4 |
0,037736 |
0,178412 |
|
20 |
ф |
0 |
0 |
0 |
|
21 |
х |
1 |
0,009434 |
0,063471 |
|
22 |
ц |
0 |
0 |
0 |
|
23 |
ч |
1 |
0,009434 |
0,063471 |
|
24 |
ш |
4 |
0,037736 |
0,178412 |
|
25 |
щ |
0 |
0 |
0 |
|
26 |
э |
0 |
0 |
0 |
|
27 |
ю |
0 |
0 |
0 |
|
28 |
я |
2 |
0,018868 |
0,108074 |
|
|
N= |
106 |
H= |
4,116325 |
Таблица 1
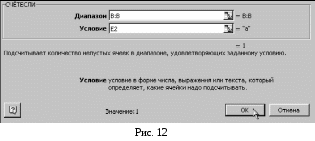
Следующая колонка «Количество». В ячейку F2 вставим формулу «СЧЕТЕСЛИ» из категории «Статистические». Диапазон указывается «В:В» (английский регистр), условие «Е2» (рис. 12), затем размножается формула до конца таблицы.
В
ячейку Е30 вводится «N=»,
а в ячейку F30 вставляется
формула суммы всех букв. Для этого
щелкается на этой ячейке и затем по
кнопке «Автосумма» (![]() )
и нажимается клавиша «Enter»,
на клавиатуре.
)
и нажимается клавиша «Enter»,
на клавиатуре.
В ячейку G2 вводим =F2/F$30, а затем размножаем до конца таблицы. В результате этого в столбце G получим значение pi.
В ячейку Н2 вводим =ЕСЛИ(G2=0;0;-G2*Log(G2;2)), а затем размножаем до конца таблицы. В ячейку G30 вводим Н=.
В ячейку Н30 вставляется формула автосуммы.
Затем таблица обрамляется. В результате получается Таблица 1 в которой энтропия информации Н оказывается равной 4,116325
5.
Строим график дискретной функции pi
= pi(х), где х – номер буквы в таблице
1. Для этого сначала переносим необходимые
столбцы таблицы на Лист 2. Выделяем
диапазон D1:Е29, копируем
его на Лист 2 в ячейку А1, затем возвращаемся
на Лист 1 и копируем диапазон G1:G29,
затем, щелкнув на ячейке С1, открываем
меню «Правка» и выбираем пункт «Специальная
вставка». В открывшемся окне щелкаем
на слове «значения» (рис. 13) и нажимаем
кнопку «ОК».
Теперь
щелкаем на кнопке «Мастер диаграмм»
(![]() ).
Появится окно Мастер диаграмм. Выбираем
Гистограмму обычную (рис. 14) и щелкаем
на кнопке «Далее».
).
Появится окно Мастер диаграмм. Выбираем
Гистограмму обычную (рис. 14) и щелкаем
на кнопке «Далее».
В шаге 2 на вкладке ничего не изменяем, поэтому сразу нажимаем на кнопку «Далее». В шаге 3 щелкаем на вкладке «Легенда» и снимаем галочку в квадрате рядом с надписью «Добавить легенду», на вкладке «Подписи данных» щелкаем на пункте «категория» и нажимаем кнопку «Далее». В шаге 4 щелкаем на надписи «на отдельном» и нажимаем кнопку «Готово».
Затем
добавляем нумерацию букв. Для этого
щелкаем на кнопке «Рисование» (![]() )
(если она не утоплена). Внизу экрана
появляется панель рисования. Выбираем
инструмент «надпись» (
)
(если она не утоплена). Внизу экрана
появляется панель рисования. Выбираем
инструмент «надпись» (![]() )
и растягиваем рамку над буквами диаграммы,
не отпуская левую клавишу мыши. Теперь
с клавиатуры набираем порядковые номера
столбцов (необходимое расстояние между
цифрами обеспечиваем пробелами). Что
бы буквы не просвечивались сквозь цифры
заливаем рамку белым цветом (кнопка
«Заливка» (
)
и растягиваем рамку над буквами диаграммы,
не отпуская левую клавишу мыши. Теперь
с клавиатуры набираем порядковые номера
столбцов (необходимое расстояние между
цифрами обеспечиваем пробелами). Что
бы буквы не просвечивались сквозь цифры
заливаем рамку белым цветом (кнопка
«Заливка» ( )
на панели «Рисование». Теперь раздвинем
столбцы так, чтобы они касались друг
друга. Для этого делаем двойной щелчок
на любом из столбцов. В открывшемся окне
«Формат элемента данных», на вкладке
«Параметры» уменьшаем ширину зазора
до 0 и нажимаем кнопку «Ок». Получилась
диаграмма, изображенная на рис. 15.
)
на панели «Рисование». Теперь раздвинем
столбцы так, чтобы они касались друг
друга. Для этого делаем двойной щелчок
на любом из столбцов. В открывшемся окне
«Формат элемента данных», на вкладке
«Параметры» уменьшаем ширину зазора
до 0 и нажимаем кнопку «Ок». Получилась
диаграмма, изображенная на рис. 15.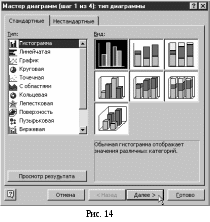
Рис. 15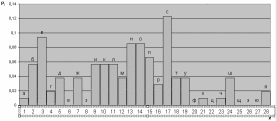
6. Перестроение диаграммы на рис. 15 в порядке возрастания частоты появления букв.Сначала необходимо скопировать таблицу и вставить ее рядом с уже имеющейся (выделяем диапазон В1:С29, копируем и щелкнув в ячейку D1 вставляем). Скопированную таблицу необходимо пересортировать в порядке возрастания частоты появления букв. Для этого необходимо выделить диапазон Е1:Н29 и открыть меню «Данные», выбрать пункт «Сортировка». В открывшемся окне «Сортировка диапазона» щелкаем на треугольнике выпадающего меню «Сортировать по» и выбираем там по «Кол-во», «Затем по» выбираем «Буква» и щелкаем мышью на «ОК» (рис. 16). В результате получится таблица 2.
|
Буква |
Pi |
|
е |
0 |
|
з |
0 |
|
ф |
0 |
|
ц |
0 |
|
щ |
0 |
|
э |
0 |
|
ю |
0 |
|
а |
0,009434 |
|
х |
0,009434 |
|
ч |
0,009434 |
|
г |
0,018868 |
|
я |
0,018868 |
|
р |
0,028302 |
|
д |
0,037736 |
|
ж |
0,037736 |
|
м |
0,037736 |
|
т |
0,037736 |
|
у |
0,037736 |
|
ш |
0,037736 |
|
б |
0,056604 |
|
и |
0,056604 |
|
к |
0,056604 |
|
л |
0,056604 |
|
п |
0,066038 |
|
н |
0,084906 |
|
о |
0,084906 |
|
в |
0,09434 |
|
с |
0,122642 |
Таблица 2
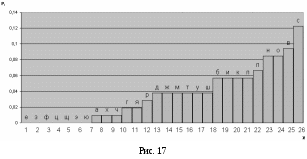
Затем строим график так же, как и первый (рис. 17).
7. Перестроение графика в вид нормальной кривой распределения.
Для
этого тот, кто хорошо владеет мышкой
может выделить все нечетные строки
сразу (удерживая Ctrl, без
номера строки) и скопировать их. Затем
щелкнуть в ячейке F1 и
нажать кнопку Вставить (![]() ).
Те же, кто плохо владеет мышью, могут
копировать и вставлять по одной строке,
начиная со строки таблицы с номером 1 в
столбик друг под другом. Затем выделить
все четные строки, скопировать их,
щелкнуть в ячейку К15 и нажать кнопку
«Вставить» открыть меню «Данные»,
выбрать пункт «Сортировка». В открывшемся
окне «Сортировка диапазона» щелкаем
на треугольнике выпадающего меню
«Сортировать по» и выбираем там по «Pi»,
ставим, щелкаем мышью на слове «по
убыванию» и щелкаем мышью на «ОК» (или
так же копировать по одной строке,
вставляя их ниже ранее скопированных
строк, начиная с последней 28 строки, и
заканчивая 2)в результате получится
Таблица 3.
).
Те же, кто плохо владеет мышью, могут
копировать и вставлять по одной строке,
начиная со строки таблицы с номером 1 в
столбик друг под другом. Затем выделить
все четные строки, скопировать их,
щелкнуть в ячейку К15 и нажать кнопку
«Вставить» открыть меню «Данные»,
выбрать пункт «Сортировка». В открывшемся
окне «Сортировка диапазона» щелкаем
на треугольнике выпадающего меню
«Сортировать по» и выбираем там по «Pi»,
ставим, щелкаем мышью на слове «по
убыванию» и щелкаем мышью на «ОК» (или
так же копировать по одной строке,
вставляя их ниже ранее скопированных
строк, начиная с последней 28 строки, и
заканчивая 2)в результате получится
Таблица 3.
|
Буква |
Pi |
|
е |
0 |
|
ф |
0 |
|
щ |
0 |
|
ю |
0 |
|
х |
0,009434 |
|
г |
0,018868 |
|
р |
0,028302 |
|
ж |
0,037736 |
|
т |
0,037736 |
|
ш |
0,037736 |
|
и |
0,056604 |
|
л |
0,056604 |
|
н |
0,084906 |
|
в |
0,09434 |
|
с |
0,122642 |
|
о |
0,084906 |
|
п |
0,066038 |
|
б |
0,056604 |
|
к |
0,056604 |
|
д |
0,037736 |
|
м |
0,037736 |
|
у |
0,037736 |
|
я |
0,018868 |
|
а |
0,009434 |
|
ч |
0,009434 |
|
з |
0 |
|
ц |
0 |
|
э |
0 |
Таблица 3
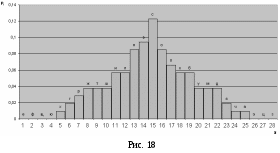
Затем строим график так же, как и первый. На рисунке 18 получившаяся гистограммы имеет вид нормальной кривой распределения.
8. Рассчитываем значения χ, .
В ячейку Н2 вводим формулу =А2*G2. Размножаем ее вниз до конца таблицы. В ячейку G30 вводим χ =. В ячейку H30 вводим формулу Автосуммы. Это и есть значение χ=14,79245.
Для нормальной кривой распределения имеют физический смысл такие характеристики, как математическое ожидание х и среднее квадратичное отклонение . Для вычисления этих величин в математической статистике имеют место следующие формулы
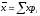 ;
; 
В ячейку I2 вводим формулу =(A2-H$33)*(A2-H$33)*G2 и размножаем ее до конца таблицы. В ячейку I30 вводим формулу Автосуммы. В ячейку I31 вводим =КОРЕНЬ(I30). В результате получим =4,366936.
Для
рассматриваемого стихотворения Рубцова
эти числа оказались равными
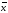 =14,79245,
σ =4,366936.
=14,79245,
σ =4,366936.
Проделанные вычисления показали, что Н и σ, рассчитанные по кривой нормального распределения, оказываются близкими числами. Этот результат впервые получен в [8].
В таблице 4 представлены результаты аналогичных расчетов над произведениями упомянутых авторов. Из этой таблицы следует, что кроме стихотворения «Видения на холме», все остальные имеют близкие значения величин энтропии информации.
Отсюда можно заключить, что отобранные стихотворения для изучения в школе имеют одинаковый качественный уровень.
Следует так же заметить, что при наборе стихотворного текста на клавиатуре компьютера, к работе зрительных рецепторов подключается моторика пальцев рук. Таким образом, активизируются несколько видов памяти, зрительная, моторная и ассоциативная. Возникающие, благодаря такой работе, дополнительные связи в коре головного мозга способствуют лучшему запоминанию стихотворных текстов и их дальнейшему осмыслению.
Таблица 4.
|
Автор |
Название (первая строка) |
N |
H, бит |
χ |
σ |
|
Рубцов Н.М. |
Березы |
106 |
4,116325 |
14,79245 |
4,366936 |
|
|
Звезда полей |
81 |
3,847908 |
14,69136 |
3,667145 |
|
|
Тихая моя родина |
103 |
4,147141 |
14,70874 |
4,434269 |
|
|
Левитан |
48 |
3,763646 |
14,77083 |
3,536945 |
|
|
По дороге к морю |
109 |
4,231303 |
14,82569 |
4,717417 |
|
|
Видения на холме |
174 |
4,215583 |
14,74138 |
4,59345 |
|
|
Под ветвями больничных берез |
116 |
3,925454 |
14,66667 |
3,94888 |
|
|
В минуты музыки |
110 |
3,821215 |
14,76364 |
3,712209 |
|
А. Блок |
Летний вечер |
50 |
3,721077 |
14,66 |
3,332327 |
|
С. Есенин |
Мелколесье. Степь и дали |
99 |
4,23653 |
14,65657 |
4,776122 |
|
А. Ахматова |
Перед весной бывают дни такие |
41 |
3,534892 |
14,82927 |
2,912567 |
|
Б. Сологуб |
Забелелся туман за рекой |
53 |
3,838506 |
14,83019 |
3,622445 |
По описанной выше схеме произведены расчеты сорока пяти стихотворений Николая Рубцова. Результаты этих расчетов систематизированы в таблице 5.
Таблица 5
|
№ |
Названия стихотворения |
Н бит |
Число начальных букв с нулевыми частотами |
Количество слов в стихотворении |
Частоты слов на начальные буквы |
||
|
в |
н |
с |
|||||
|
1 |
Элегия |
3,6294 |
9 |
70 |
0,0714 |
0,1 |
0,1 |
|
2 |
Ось |
4,0043 |
7 |
86 |
0,0349 |
0,0349 |
0,0349 |
|
3 |
На вокзале |
3,9064 |
8 |
125 |
0,144 |
0,08 |
0,072 |
|
4 |
Весна на берегу Бии |
4,0055 |
5 |
131 |
0,1145 |
0,0763 |
0,1069 |
|
5 |
Прощальная песня |
4,0215 |
6 |
182 |
0,0714 |
0,1264 |
0,1099 |
|
6 |
В лесу |
3,1878 |
9 |
84 |
0,119 |
0,0833 |
0,1905 |
|
7 |
Ветер всхлипывал словно дитя |
3,895 |
9 |
74 |
0,0811 |
0,054 |
0,126 |
|
8 |
У церковных берез |
3,9637 |
6 |
130 |
0,0923 |
0,0692 |
0,0615 |
|
9 |
В московском кремле |
7,1349 |
10 |
148 |
0,2143 |
0,2142 |
0,5357 |
|
10 |
Поэзия |
3,4573 |
6 |
133 |
0,1061 |
0,0682 |
0,1061 |
|
11 |
Сентябрь |
3,7171 |
11 |
62 |
0,0484 |
0,1613 |
0,129 |
|
12 |
По дороге к морю |
8,2939 |
6 |
114 |
0,3333 |
0,1 |
0,2333 |
|
13 |
Стоит жара |
4,0368 |
8 |
57 |
0,0877 |
0,0526 |
0,1754 |
|
14 |
Плыть, плыть |
6,4871 |
6 |
84 |
0,1429 |
0,3214 |
0,2143 |
|
15 |
Волнуется море |
4,1101 |
8 |
69 |
0,1449 |
0,058 |
0,1014 |
|
16 |
Гость молчит и я ни слова |
3,7901 |
12 |
79 |
0,1013 |
0,0886 |
0,1138 |
|
17 |
В пустыне |
3,7915 |
10 |
77 |
0,0909 |
0,039 |
0,1299 |
|
18 |
Увлекаюсь нечаянно |
3,4473 |
14 |
50 |
0,02 |
0,04 |
0,08 |
|
19 |
В горной деревне |
4,0075 |
9 |
80 |
0,075 |
0,05 |
0,1125 |
|
20 |
Мечты |
3,7149 |
9 |
76 |
0,2027 |
0,1351 |
0,0676 |
|
21 |
Видения на холме |
4,2156 |
3 |
174 |
0,1034 |
0,0862 |
0,0632 |
|
22 |
Грани |
4,0147 |
8 |
70 |
0,0714 |
0,1286 |
0,1143 |
|
23 |
По мокрым скверам проходит осень |
3,8397 |
9 |
93 |
0,0753 |
0,0968 |
0,1505 |
|
24 |
В полях смеркалось. Близилась гроза |
3,6658 |
11 |
65 |
0,0615 |
0,0615 |
0,0462 |
|
25 |
Привет Россия |
3,9456 |
9 |
114 |
0,1053 |
0,0877 |
0,1053 |
|
26 |
В горнице |
3,8638 |
9 |
57 |
0,1053 |
0,0877 |
0,1403 |
|
27 |
Родная деревня |
4,1048 |
6 |
66 |
0,0606 |
0,0606 |
0,0455 |
|
28 |
Вологодский пейзаж |
4,1059 |
6 |
128 |
0,1094 |
0,0469 |
0,1016 |
|
29 |
Далекое |
7,1822 |
7 |
85 |
0,3214 |
0,1786 |
0,4286 |
|
30 |
На вокзале |
3,7422 |
8 |
123 |
0,1382 |
0,0732 |
0,065 |
|
31 |
Старик |
3,7852 |
9 |
101 |
0,099 |
0,0693 |
0,0396 |
|
32 |
Сапоги мои - скрип да скрип |
3,8066 |
9 |
125 |
0,064 |
0,048 |
0,072 |
|
33 |
Памяти матери |
3,87 |
7 |
84 |
0,1309 |
0,0833 |
0,1905 |
|
34 |
В сибирской деревне |
4,0113 |
6 |
90 |
0,1111 |
0,0778 |
0,1333 |
|
35 |
Зимним вечерком |
3,9955 |
8 |
60 |
0,1 |
0,0667 |
0,05 |
|
36 |
Меж болотных стволов красовался восток огнеликий |
3,9847 |
7 |
102 |
0,186 |
0,059 |
0,098 |
|
37 |
Синенький платочек |
3,9445 |
4 |
89 |
0,1149 |
0,069 |
0,1724 |
|
38 |
Острова свои оберегаем |
3,9407 |
9 |
82 |
0,1196 |
0,0652 |
0,0761 |
|
39 |
А между прочим осень на дворе |
4,0818 |
5 |
121 |
0,1405 |
0,0577 |
0,0992 |
|
40 |
Есть пора - души моей отрада |
4,2165 |
6 |
79 |
0,0633 |
0,0886 |
0,0506 |
|
41 |
Старый конь |
3,9524 |
9 |
72 |
0,1389 |
0,0278 |
0,0694 |
|
42 |
Прекрасное небо голубое |
4,0479 |
7 |
92 |
0,0543 |
0,0326 |
0,0326 |
|
43 |
На реке Сухоне |
3,6389 |
10 |
112 |
0,1071 |
0,1607 |
0,1429 |
|
44 |
Добрый Филя |
3,9008 |
9 |
56 |
0,0357 |
0,0179 |
0,0714 |
|
45 |
Оттепель |
3,7292 |
8 |
113 |
0,0265 |
0,0177 |
0,0531 |
Анализ данных этой таблицы показывает, что количественная мера информации Н различна для каждого произведения и ее числовые значения для стихов Рубцова изменяются в довольно широких пределах. Все это означает, что числовые значения Н отражают литературные достоинства поэтических текстов.
Из таблицы 5 так же следует, что в стихах Рубцова частота появления слов на букву «в» лежит в приделах: 0,02≤р≥0,2143; соответственно на букву «н» – 0,0177≤р≥0,3214; и наконец на букву «с» –0,0349≤р≥0,5357.
Таблица 5 позволяет установить еще один из математических критериев, характеризующий индивидуальность творчества Н.Рубцова. Для этого изучим зависимость между энтропией информации Н и количеством слов в стихотворении N.
На плоскости НN построим совокупность точек, отражающих эту зависимость. Для этого в Excel набираем таблицу соответствия Н и N, заполняя столбцы А и В. Затем выделяем полученную таблицу и щелкаем на кнопке Мастер диаграмм. В открывшемся окошке выбираем точечную диаграмму и щелкаем на кнопке Далее. В шаге 3 называем ось х – Н, а ось y – N, на вкладке легенда убираем галочку Добавить легенду. В шаге 4 щелкаем мышью на слове «отдельном» и щелкаем на кнопке Готово.
Для дальнейших расчетов с использованием мастер-функции программы Excel переобозначим: y=H, x=N. Проверяем, связаны ли величины Н и N линейной зависимостью, т.е. имеет ли место функциональная зависимость. Для этого щелкаем правой клавишей мыши на одной из точек диаграммы. В открывшемся меню выбираем пункт – Добавить линию тренда. На вкладке Параметры ставим галочку около слов – Показывать уравнение на диаграмме и щелкаем на кнопке Ок. Чтобы придать диаграмме более удобный для просмотра вид делаем двойной щелчке на одной из осей диаграммы. В открывшемся окне выбираем вкладку Шкала и выставляем минимальное и максимальное значение так, чтобы данные занимали всю область построения диаграммы. Тоже самое делаем и для другой оси. В результате получится диаграмма, показанная на рис. 19.

рис. 19
Из рис. 19 становится очевидным, что между величинами Н и N нет функциональной зависимости. Степень отличия реальной связи между Н и N от линейной в математической статистики устанавливается так называемым коэффициентом корреляции r.
Возможности программы Excel позволяют вычислить эту величину. Для этого возвращаемся на лист с таблицей данных. Щелкаем в свободной ячейке и щелкаем на кнопке Мастер функций. В категории Статистические выбираем функцию КОРРЕЛ и щелкаем на кнопке Ок. в открывшемся окошке в графе Массив1 вводим - A2:A46, в графе Массив2 вводим - B2:B46 и нажимаем кнопку Ок. Получившееся в ячейке число и есть коэффициент корреляции.
Оказалось, что для произведений Н.Рубцова коэффициент корреляции r оказался равным 0,175974. полученное таким образом значение r и есть еще один критерий индивидуальности творчества данного поэта.