

Практична робота №5
Тема: Принципи побудови комп'ютерних моделей з урахуванням фактора невизначеності.
Ціль роботи: Сформувати вміння й практичні навички побудови моделей, їхню реалізацію засобами Excel.
Хід роботи:
В управлінській діяльності часто виникають ситуації, за яких доводиться приймати рішення, виходячи з недостатньо чітко визначених умов і оперуючи не завжди надійною інформацією. У таких випадках виникає потреба в оцінюванні ймовірності досягнення тих чи інших результатів. Наприклад, якщо буде прийняте рішення А, то ймовірність досягнення додаткового прибутку у розмірі 10 % становитиме 95 %, а за рішення В вона зменшиться до 65 %.
Існує три основних методи, що дають змогу приймати рішення з урахуванням фактора невизначеності та підтримуються Excel: стандартні відхилення, довірчі інтервали і множинний регресійний аналіз.
Стандартне (середнє квадратичне) відхилення — ступінь відхилення усіх значень ознаки від свого середнього показника — є одним із найважливіших методів, що допомагають визначити, наскільки змінюється певна величина: чим більше стандартне відхилення, тим ширший діапазон змін значень цієї величини.
Припустимо, що слід проаналізувати ефективність діяльності торгових агентів і продавців. Варто наголосити, що для більшості підприємств цей показник є найвагомішим серед тих, що впливають на збут. Під діяльністю торгових агентів і продавців розуміється робота, що проводиться ними безпосередньо з потенційними покупцями: за прилавком магазину, під час відвідування клієнтів за місцем проживання або прийому попередніх замовлень телефоном. Якщо такі працівники зацікавлені у результатах своєї діяльності, добре знають товар, який продають, і мають відповідний комерційний хист, то їх внесок в успіх фірми можна вважати вирішальним.
Природно розпочати аналіз з визначення середньої суми комісійних, яку фірма сплачує цій категорії своїх працівників. Функція Excel, яка розраховує середні показники, має назву СРЗНАЧ. Вона підсумовує значення клітин вказаного діапазону і ділить цю суму на кількість його клітин. Проте одна ця цифра ще не дає змоги оцінити роботу торгових агентів, оскільки середня величина — це узагальнена характеристика тієї сукупності, що вивчається. Вона не показує побудови сукупності, яка є дуже суттєвою для пізнання останньої. Окремі значення можуть зосереджуватися біля середньої величини (тоді вона добре представляє всю сукупність) або значно відхилятися від неї (погано представляє сукупність). Показником надійності середньої величини є стандартне (середньоквадратичне) відхилення: близько двох третин окремих елементів сукупності знаходяться на одне стандартне відхилення нижче або вище середнього показника.
Так, якщо за середньорічного заробітку 1440 грн стандартне відхилення дорівнює 107 грн, то це означає, що заробіток двох третин торгових агентів становить (1440 107) грн, звідки випливає, що ефективність їхньої роботи практично збігається. Якщо ж заробіток двох третин торгових агентів становить, наприклад, (1440 645) грн, то це означає, що середнє значення (1440 грн) погано представляє сукупність, а отже, значна кількість торгових агентів працює по-різному і є сенс у тому, щоб з’ясувати причини такого становища.
Для підвищення наочності такого аналізу використовуються гістограми і точкові діаграми. На горизонтальній осі відкладено різні значення комісійних, на вертикальній — результати спостережень за кожною категорією комісійних (кількість попадань у різні категорії виплат, кожна з яких відрізняється від попередньої на 200 грн). Слід звернути увагу на те, що за меншого значення стандартного відхилення ці результати мають менший розподіл зліва направо, ніж за більшого.
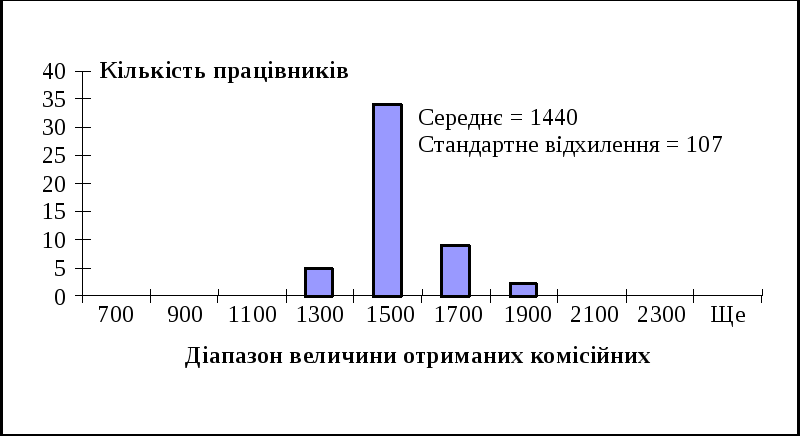
Рис 1. Гістограма для різних значень стандартного відхилення

Рис 2 Точкова діаграма за різних значень стандартного відхилення
На рис. 2 числові значення комісійних відображено на вертикальній осі, а порядковий номер спостереження — на горизонтальній. На верхній діаграмі всі значення близькі до середнього (незначне стандартне відхилення), на нижній спостерігається значне варіювання значень порівняно із середнім. Наведені діаграми показують, що знання середнього значення вибірки ще не є достатнім для прийняття рішення. Якщо ж відомі і середнє значення і стандартне відхилення, то це дає змогу досить чітко уявити, як значення згруповані біля середнього.
У Excel є дві функції для обчислення стандартного відхилення: СТАНДОТКЛОНП ) і СТАНДОТКЛОН( ).
Функція СТАНДОТКЛОНП() використовується для обчислення стандартного відхилення за суцільного обстеження, а СТАНДОТКЛОН( ) — для обчислення стандартного відхилення за вибіркового обстеження. Буква П (у кінці назви першої функції) є мнемонікою слова популяція (генеральна сукупність).
Крім стандартного відхилення, для характеристики відхилень значень ознаки сукупності від свого середнього значення можна користуватися дисперсією, що дорівнює 2. Якщо стандартне відхилення можна подати як відстань, то дисперсію — як площину.
В Excel для обчислення дисперсії за суцільного обстеження застосовується функція ДИСПР( ), а за вибіркового — ДИСП( ).
Довірчий інтервал — це інтервал, що дає змогу оцінити із заданою точністю невідоме значення генеральної сукупності. Таке невідоме значення називається довірчим, а його границі — довірчими границями (верхні та нижні границі). В їх межах можна мати деякий рівень упевненості щодо наявності конкретного значення ознаки генеральної сукупності.
Довірчі інтервали широко застосовуються для дослідження ринку. Припустимо, що розглядається питання про відкриття нового магазину. Важливим критерієм за вирішення цього питання може бути кількість потенційних покупців, що проходитимуть повз магазин. Щоб з’ясувати це, можна кожного дня протягом деякого періоду підраховувати кількість пішоходів. Одержані результати створять вибірку з генеральної сукупності всіх можливих днів, коли магазин працюватиме.
Далі можна підрахувати середній показник результатів таких спостережень й отримати певну цифру. Але відразу постає питання — наскільки точно ця цифра характеризує дійсну кількість людей, що проходитимуть повз магазин кожного дня?
Відповідь можна знайти з допомогою довірчого інтервалу середнього значення. Щоб визначити його в Excel, слід підключити пакет аналізу (якщо його не було підключено раніше):
-
Вибрати команду Сервіс/Надбудова.
-
У діалоговому вікні Надбудова, яке з’явиться після виконання попередньої команди, вибрати параметр Пакет аналізу.
-
Закрити діалогове вікно, клацнувши по кнопці ОК.
-
Якщо пакет аналізу підключено, довірчий інтервал можна визначити, виконавши такі дії.
-
Вибрати команду Сервіс/Аналіз даних.
-
Вибрати у списку діалогового вікна Аналіз даних інструмент аналізу Описувальна статистика.
-
Закрити список інструментів аналізу, клацнувши по кнопці ОК, що має призвести до появи діалогового вікна Описувальна статистика.
-
У поле Вхідний інтервал увести або виділити мишею той діапазон (колонку чи рядок) робочого аркуша, у який занесено результати спостережень.
-
Включити параметр Мітки у першому рядку і перевірити значення у полі Рівень надійності. Він звичайно має дорівнювати 95 %.
-
Включити перемикач Вихідний інтервал і ввести в поле, що знаходиться біля нього, адресу лівого верхнього кута області робочого аркуша, де розміщуватиметься результат аналізу (значення статистичного показника).
-
Клацнути на кнопці ОК.
Регресійний і кореляційний аналіз — дуже ефективні методи, які дають змогу аналізувати значні обсяги інформації з метою дослідження ймовірного взаємозв’язку двох чи більше змінних. У регресійному аналізі розглядається зв’язок між однією змінною, названою залежною змінною, або ознакою, і кількома іншими, названими незалежними змінними. Цей зв’язок подається з допомогою математичної моделі, тобто рівняння, яке зв’язує залежну змінну (y) з незалежними (x) з урахуванням множини відповідних припущень. Оскільки метою регресійного аналізу є виявлення впливу змінних х на значення змінної у, останню ще називають відгуком, або результативним фактором, а змінні х — факторами, що впливають на відгук. Регресійний аналіз використовується з двох причин. По-перше, тому що опис залежності між змінними допомагає встановити наявність можливого причинного зв’язку. По-друге, отримання аналітичної залежності між змінними дає змогу передбачати майбутні значення залежної змінної за значенням незалежних змінних.
За аналізу соціально-економічних процесів регресія застосовується водночас з кореляцією. З допомогою регресії визначаються аналітичні залежності між змінними, а через кореляційний аналіз — сила зв’язку між факторами та відгуком. Саме тому, що основні статистичні проблеми регресійного аналізу вирішуються аналізом кореляцій, методи регресійного та кореляційного аналізу тісно зв’язані між собою.
Excel забезпечує ефективну підтримку побудови та аналізу регресійних моделей: 15 функцій робочих аркушів, створених саме з цією метою, а також такі можливості, як побудова лінії тренда на графіках, та інструмент аналізу Регресія, з допомогою яких зручно проводити конкретні регресійні обчислення.
Найбільш наочний спосіб дослідження зв’язку між двома змінними базується на використанні точкової діаграми з лінією тренда. Крім того, Excel має набір спеціальних функцій, які за певних умов у використанні зручніші за діаграми.
Так, для обчислення значення R2 можна використати функцію КВПИРСОН.
Відрізок на осі ординат можна отримати з допомогою функції ОТРЕЗОК. Коефіцієнт нахилу лінійної регресії — за допомогою функції НАКЛОН. Щоб отримати відрізок на осі координат і коефіцієнт нахилу з допомогою однієї функції, слід виділити дві клітини, натиснути на панелі інструментів кнопку Вставка функції, у діалоговому вікні вибрати функцію ЛИНЕЙН, вказати перші два параметри (діапазон клітин, де знаходяться значення відгуку, та діапазон клітин зі значеннями незалежної змінної) і, тримаючи натиснутими клавіші Ctr і Shift, натиснути клавішу Enter.
Одночасно з обчисленням параметрів лінійного рівняння регресії (у тому числі й множинної) функція ЛИНЕЙН може повертати додаткову регресійну статистику. До цієї статистики входять:
se1, …, sen — стандартні значення помилок для коефіцієнтів m1, …, mn;
seb — стандартне значення помилки для постійної b;
R2 — величина вірогідності апроксимацїї (коефіцієнт детермінації);
sey — стандартна помилка для оцінки у;
F — F-статистика, або F-відношення;
df — кількість ступенів вільності (N – m – 1);
SSрег — регресійна сума квадратів;
SSзал — залишкова сума квадратів.
Розглянемо технологію проведення регресійно-кореляційного аналізу з допомогою Excel на конкретному прикладі. Припустимо, що треба дослідити результати збільшення витрат на рекламу деякої продукції і зниження ціни на одиницю цієї продукції з метою збільшення обсягів продажу. Почнемо з перевірки пропозиції про збільшення витрат на рекламу. Звичайно, не можна не враховувати того, що реальний продаж додаткових обсягів продукції може навіть не виправдати витрат на рекламну кампанію. Для з’ясування цього питання слід виявити зв’язок між витратами на рекламу для кожного виду продукції і кількістю одиниць продаваної продукції. Якщо є необхідні дані для проведення регресійного аналізу, то цей зв’язок можна оцінити у кількісній формі.
Завдання 1. На рис. 3. наведено таблицю, що має дві колонки — витрати на рекламу і кількість одиниць проданої продукції. Зв’язок між цими змінними можна легко (хоча і в дещо спрощеній формі) оцінити з допомогою точкової діаграми.
Для побудови цієї діаграми слід виділити дані в діапазоні А2:В20, вибрати команду Вставка/Діаграма (або клацнути на кнопці Майстер діаграм) і ввести потрібну інформацію на кожному з чотирьох кроків побудови діаграми. Зауважимо, що на першому кроці вибирається тип діаграми, яка має назву Точкова.
Коли діаграма з’явиться у робочому аркуші, треба клацнути по ній лівою кнопкою миші і вибрати команду Діаграма/Додати лінію тренда. У діалоговому вікні Лінія тренда на вкладці Тип вибирається тип апроксимації Лінійна, а на вкладці Параметри встановлюються режими: Показувати рівняння на діаграмі та Розмістити на діаграмі величину вірогідності апроксимації (R^2).
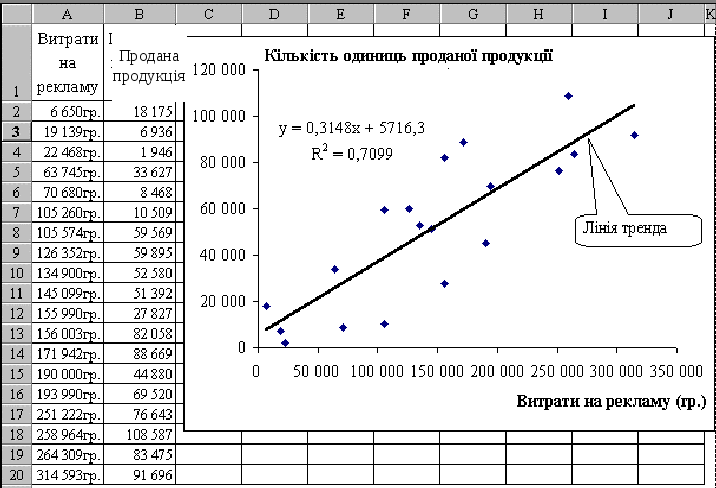
Рис. 3. Зв’язок між обсягами продажу (в одиницях продукції) і витратами на рекламу
На рис. 3. лінію тренда подано прямою, яка йде з нижнього лівого кута у правий верхній. Це говорить про те, що за збільшення витрат на рекламу пропорційно збільшуються й обсяги продажу (в одиницях продукції).
Діаграма також вміщує рівняння
у = 0,3148x + 5716,3.
Це рівняння регресії. Воно найкраще апроксимує дані, наведені у робочому аркуші, у вигляді прямої (y = mx + b). Для даного прикладу таке рівняння показує залежність між сумою грошей, витрачених на рекламу певної продукції, і обсягами продажу в одиницях цієї продукції (у — це обсяги продажу, x — витрати на рекламу в гривнях). Це не означає, що за відомих витрат на рекламу можна точно визначити обсяги продажу. Наприклад, у разі підстановки в рівняння замість х значення 171 942 грн (сума витрат на рекламу) буде отримано результат — 59843,64 одиниць продукції. У таблиці з даними значення 171 942 грн наведено як один з фактичних результатів спостереження, але цьому значенню відповідає зовсім інша величина обсягів продажу — 88 669 одиниць продукції. Отже, регресія на основі тих даних, які ми маємо, дає найбільш точну оцінку, але не абсолютно точний прогноз. Точність апроксимації з допомогою прямої залежить від ступеня розкиду даних. Чим ближче дані до прямої, тим точнішою є лінійна регресійна модель.
Розглядаючи принципи регресійного аналізу, дуже важливо зрозуміти, що регресія виражає зв’язок між змінними, а це не те саме, що причинна обумовленість, яка означає, що маніпуляції з однією змінною обов’язково приведуть до певних змін іншої.
Якщо в дане рівняння регресії підставити значення 400 000 грн, то отримаємо, що приблизний обсяг продажу в одиницях продукції дорівнюватиме 531636. Це зовсім не означає, що, витративши на рекламу 400000 грн, підприємство продасть 531 636 одиниць цієї продукції (хоча, звичайно, цього і не можна виключати). Є велика кількість факторів, крім витрат на рекламу, які впливають на зміни в обсягах продажу, і ці фактори (наприклад, продажна ціна одиниці продукції) у цьому рівнянні регресії ніяк не відображені. Навіть якщо зв’язок між змінними має причинний характер, треба ще знати напрям цієї причинності. Цілком вірогідно, що відділ маркетингу збільшував витрати на рекламу продукції після того, як збільшувались обсяги продажу. У цьому разі ми можемо бути впевненими лише у впливі обсягів продажу на розміри витрат на рекламу, а не навпаки.
Коефіцієнт регресії m є мірою нахилу лінії тренда: чим він більший, тим крутіша лінія тренда. У даному разі — це число 0,3148. Воно інтерпретується так: «Якщо між обсягами продажу та витратами на рекламу є зв’язок, то, за попередніми оцінками, за збільшення витрат на рекламу на 10 000 грн буде продано додатково приблизно 3148 одиниць продукції».
Незмінна b — це відрізок на осі ординат. Вона вказує, в якому місці лінія тренда перетинає вісь у (вертикальну вісь). У даному разі — це число 5716,3. Воно інтерпретується так: «Якщо між обсягами продажу та витратами на рекламу є зв’язок і якщо не виділятимуться гроші на проведення реклами, то, за попередніми оцінками, буде продано приблизно 5716 одиниць продукції».
Значення коефіцієнта детермінації на діаграмі дорівнює 0,7099. Це означає, що приблизно 71 % міри мінливості обсягу продажу одиниць продукції зв’язано з мірою мінливості витрат на рекламу.
На рис. 4 у діапазоні A2:C20 знаходяться дані спостережень про обсяги продажу (уф), які включають, крім витрат на рекламу (х1), ціни (х2), за якими продавалися рекламовані товари.
|
|
A |
B |
C |
|
|
1 |
Витрати на рекламу (x1), грн |
Ціна (x2), грн |
Продана продукція (yф), од. |
|
|
2 |
6 650 |
147,2 |
7 175 |
|
|
3 |
19 139 |
158,5 |
5 836 |
|
|
4 |
22 468 |
161,5 |
9 946 |
|
|
5 |
63 745 |
103,2 |
23 627 |
|
|
6 |
70 680 |
191,9 |
8 468 |
|
|
7 |
105 60 |
134,9 |
20 509 |
|
|
8 |
105 574 |
107,8 |
49 569 |
|
|
9 |
126 352 |
155,8 |
35 895 |
|
|
10 |
134 900 |
117,8 |
52 580 |
|
|
11 |
145 099 |
100,7 |
65 392 |
|
|
12 |
155 990 |
172,9 |
27 827 |
|
|
13 |
156 003 |
95,6 |
72 058 |
|
|
14 |
171 942 |
98,8 |
80 669 |
|
|
15 |
190 000 |
105,5 |
44 880 |
|
|
16 |
193 990 |
99,9 |
69 520 |
|
|
17 |
251 222 |
76,8 |
98 643 |
|
|
18 |
258 964 |
95,2 |
75 587 |
|
|
19 |
264 309 |
119,7 |
83 475 |
|
|
20 |
314 593 |
125,5 |
91 696 |
|
Рис. 4. Дані про обсяги продажу, витрати на рекламу та ціни на товари
Моделі парної кореляції між обсягами продажу цих товарів і їх цінами наведено на рис. 3. При виборі лінійної моделі маємо регресійне рівняння у = –744,5х + 141432 з коефіцієнтом детермінації 0,5763. Слід звернути увагу на те, що коефіцієнт регресії від’ємний, а лінія тренда йде з верхнього лівого у нижній правий кут діаграми. Тобто маємо звичайну залежність обсягів продажу від ціни продукції: чим вища ціна, тим менша кількість продукції продається.
Найпростіший спосіб визначити в Excel залежність результатної ознаки від декількох факторів — використати інструмент Регресія, який повертає всю потрібну інформацію, згруповану у декілька таблиць.
Для отримання цієї інформації слід активізувати робочий аркуш з даними і виконати такі дії: Виконати команду Сервіс/Аналіз даних. У діалоговому вікні Аналіз даних зі списку Інструменти аналізу вибрати інструмент Регресія і натиснути кнопку ОК. Після появи діалогового вікна Регресія потрібно:
-
у текстовому полі Вхідний інтервал Y встановити діапазон С2:С20 (увести з клавіатури або виділити мишею ці клітини у робочому аркуші);
-
у текстовому полі Вхідний інтервал X встановити діапазон А2:А20;
-
у поле Рівень надійності ввести число 95 (якщо воно там не стоїть);
-
перемикач Параметр виведення встановити в положення Новий робочий аркуш;
-
клацнути по кнопці ОК.
Результати (рис. 5), отримані з допомогою інструмента Регресія, містять всю потрібну інформацію. Так, у клітині В5 знаходиться значення параметра R2, а в В4 — значення множинного R, яке являє собою квадратний корінь з дисперсії (R2). Це значення (0,9085) є коефіцієнтом кореляції і виражає кореляцію між кількістю проданої продукції і отриманою комбінацією незалежних змінних. Воно означає, що приблизно 91 % міри мінливості кількості продажу продукції зв’язано з мірою мінливості ціни, за якою продається ця продукція, і розмірами витрат на її рекламу.
Значення R2 двофакторної моделі суттєво більше, ніж відповідних однофакторних. Це свідчить про те, що остання модель набагато краще за попередні пояснює зміни результативної ознаки (обсяги продажу). Проте ще треба з’ясувати, чи не є цей результат випадковим. Припустимо, що в дійсності ніякого взаємозв’язку змінної у та змінних х немає. Величину ймовірності помилковості твердження про те, що є значний взаємозв’язок між змінними, приймемо рівною 0,05. Для ступенів вільності маємо: df1 = 2 (кількість факторів), df2 = 16 (значення клітини B13). У будь-якому статистичному довіднику можна знайти, що F-критичне (для вказаних величин) дорівнює 3,36. Спостережуване F-значення більше 79 (клітина Е12), що значно більше за F-критичне значення 3,36. Отже, припущення про відсутність взаємозв’язку залежної та незалежних змінних не підтверджується.
|
|
A |
B |
C |
D |
E |
F |
G |
|
|
|
1 |
ВЫВОД ИТОГОВ |
|
|
|
|
|
|
||
|
2 |
|
|
|
|
|
|
|
|
|
|
3 |
Регрессионная статистика |
|
|
|
|
|
|
|
|
|
4 |
Множественный R |
0,95317 |
|
|
|
|
|
|
|
|
5 |
R-квадрат |
0,90854 |
|
|
|
|
|
|
|
|
6 |
Нормированный R-квадрат |
0,8971 |
|
|
|
|
|
|
|
|
7 |
Стандартная ошибка |
9941,79 |
|
|
|
|
|
|
|
|
8 |
Наблюдения |
19 |
|
|
|
|
|
|
|
|
9 |
|
|
|
|
|
|
|
|
|
|
10 |
Дисперсионный анализ |
|
|
|
|
|
|
|
|
|
11 |
|
df |
SS |
MS |
F |
Значимость F |
|
|
|
|
12 |
Регрессия |
2 |
1,57E+10 |
7,85E+09 |
79,4666 |
4,898E-09 |
|
|
|
|
13 |
Остаток |
16 |
1,58E+09 |
98839123 |
|
|
|
|
|
|
14 |
Итого |
18 |
1,73E+10 |
|
|
|
|
|
|
|
15 |
|
|
|
|
|
|
|
|
|
|
16 |
|
Коэффициенты |
Стандартная ошибка |
t-статистика |
P-значение |
Нижние 95 % |
Верхние 95 % |
|
|
|
17 |
Y-пересечение |
61304,1 |
14182,96 |
4,355678 |
0,000490366 |
31237,591 |
69924,2 |
|
|
|
18 |
Переменная X 1 |
0,24181 |
0,031717 |
7,623928 |
1,0298E-06 |
0,1745723 |
0,33337 |
|
|
|
19 |
Переменная X 2 |
–383,28 |
87,99497 |
–4,3224 |
0,00052558 |
–569,8207 |
–52,2293 |
|
|
Рис. 5 Інформація, видана інструментом Регресія
Нормований R2, що знаходиться у клітині В6, ураховує кількість результатів спостережень і незалежних змінних. Якщо кількість спостережень відносно кількості незалежних змінних не досить велика, R2 має тенденцію відхилятися в бік підвищення. Нормований R2 забезпечує інформацією про те, яке значення могло б бути отримано в іншому наборі даних, значно більшому за аналізований. Якщо б розглядуваний приклад базувався на значно більшій кількості спостережень, то нормований R2 і фактичний R2не дуже різнилися б.
Діапазон A17:C19 містить детальну інформацію щодо членів регресії — постійної b (Y-пересечение) та коефіцієнтів регресії — та їх стандартних похибок.
У колонці t-статистика знаходяться стандартизовані (нормованi) зміннi, які представляють частку кожного члена рівняння в його стандартній похибці.
У колонці P-значення розташовано результати обчислень, які дають змогу перевірити, чи є отримані значення коефіцієнтів регресії дійсно корисними у разі оцінювання з їх допомогою кількості продажу. Ці результати уможливлюють висновок, що у даному разі за умови, що відповідний коефіцієнт реально має нульове значення, ймовірність отримати значення
|m2| = 383,28 не більша 0,0006 (або 6 шансів з 10 000),
m1 = 0,2418 приблизно 0,000001 (або 1 шанс з 1 000 000),
b = 61 304,11 не більша 0,0005 (або 5 шансів з 10 000).
А це підтверджує статистичну значущість отриманих коефіцієнтів регресії.
Останні колонки третього розділу результатів вміщують нижню і верхню границі 95-процентного рівня надійності як для постійної, так і для кожного коефіцієнта регресії. Тут треба звернути увагу на те, що жоден з трьох довірчих інтервалів не охоплює нульове значення. Це саме той результат, який і треба було очікувати, оскільки всі Р-значення, що знаходяться вище 5-процентного рівня, є значущими. Якщо б Р-значення дорівнювало 0,05 або більше, довірчий інтервал цього показника включав би нуль.
Отже, можна з 95-процентною впевненістю стверджувати, що всі показники регресії не є нульовими. З цього випливає, що незалежні змінні додають до рівняння регресії значущу інформацію і на основі даних про витрати на рекламу продукції та ціни, за якими вона продається, можна досить точно прогнозувати обсяги продажу.
Завдання 2. Аналіз рентабельності виробництва сукупності товарів. Визначення найвигіднішого асортименту — досить складна задача, для розв’язання якої у загальному випадку слід ураховувати як ринкові умови, так і технологічні можливості виробництва.
Розглянемо модель підприємства, що виробляє два види продуктів — П1 і П2. Передбачається, що у разі встановлення ціни в 3,80 грн/т останній може бути проданий в будь-якій кількості. Існує контракт, за яким треба виробляти не менше як 40 тис. т/день продукту П1 за ціною 5,50 грн/т. У разі вироблення додаткової кількості продукту його можна продати за ціною 5,50 грн/т (не більше 5 тис. т/день), використати для збільшення запасів (не більше 4 тис. т/день), які з урахуванням витрат на збереження оцінюються за подальшої реалізації в 5,20 грн/т, або продати за зниженою ціною (5 грн/т) у необмеженій кількості. У разі потреби обидва продукти можна докупити: закупівельна ціна продукту П1 становить 5,75 грн/т, а продукту П2 — 4 грн/т.
Для виробництва цих продуктів підприємство може отримати два види сировини: сировину С1 — до 100 тис. т/день за ціною 3,25 грн/т і сировину С2 більш високої якості — до 30 тис. т/день за ціною 3,40 грн/т.
Загальна потужність основного процесу переробки сировини — 100 тис. т/день за витрат на переробку 0,35 грн/т. Він дає змогу одержати 0,15 т продукту П1 і 0,85 т продукту П2 з 1 т сировини виду С1. У разі використання 1 т сировини С2 вихід продукції становитиме 0,25 т продукту П1 і 0,75 т продукту П2. Продукт П1 потребує додаткового очищення, витрати на яке — 0,10 грн/т сировини.
Для переробки продукту П2 в більш цінний продукт П1 можна застосовувати агрегат (конвертор), який дає змогу з 1 т продукту П2 одержати 0,5 т продукту П1 і 0,5 т продукту, що може бути проданий як продукт П2, але який не можна повторно переробляти конвертором. Потужність конвертора — 50 тис. т сировини (продукту П2) на день за витрат на цю обробку 0,25 грн/т сировини.
Модель підприємства складається з декількох таблиць, які розміщуються на трьох робочих аркушах з назвами Асортимент, Виробництво, Витрати (рис.6-8.
Починати будувати модель слід з таблиці «Регульовані фактори (змінні)». Після цього створюються модель виробництва (на аркуші Виробництво) і калькуляція витрат (на аркуші Витрати), в яких використовуються адреси клітин з поточними значеннями планованих змінних.
За калькулювання витрат використовується метод попроцесного обліку, який акумулює виробничі витрати по однакових продуктах виробництва. Слід звернути увагу на те, що постійні витрати не враховуються, оскільки вони не залежать від асортименту продукції, що випускається. Після калькулювання витрат може бути сформована цільова функція, значення якої обчислюється в клітині Н6 аркуша Асортимент, а після побудови моделі виробничого процесу можна записати функціональні обмеження (рядки 24–27 аркуша Асортимент). Ці обмеження враховують максимально допустиме значення загальної потужності основного процесу переробки сировини і можливі величини наявної кількості (залишків) продуктів.
|
|
A |
B |
C |
D |
E |
F |
G |
H |
I |
|||||||||||||||||
|
1 |
|
АНАЛІЗ РЕНТАБЕЛЬНОСТІ ГАМИ ТОВАРІВ |
||||||||||||||||||||||||
|
2 |
|
|
|
|
|
|
|
|
|
|||||||||||||||||
|
3 |
1. Цільова функція |
|
|
|
||||||||||||||||||||||
|
4 |
|
Виручка від реалізації |
=СУММ(І16:І19) |
|||||||||||||||||||||||
|
5 |
|
Маржинальна собівартість реалізованої продукції |
=Витрати!D17 |
|||||||||||||||||||||||
|
6 |
|
Маржинальний прибуток (тис. грн) |
=Н4-Н5 |
|||||||||||||||||||||||
|
7 |
|
|
|
|
|
|
|
|
|
|||||||||||||||||
|
8 |
2. Регульовані фактори (змінні) |
|
|
|
|
|||||||||||||||||||||
|
9 |
|
Змінна |
Планована кількість ( тис. т ) |
Прямі обмеження |
Ціна |
Вартість |
||||||||||||||||||||
|
10 |
|
Мінім. кількість |
Макcим. кількість |
|||||||||||||||||||||||
|
11 |
|
Кількість переробленої сировини С1 |
0 |
0 |
100 |
3,25 |
=E11*H11 |
|||||||||||||||||||
|
12 |
|
Кількість переробленої сировини С2 |
0 |
0 |
30 |
3,40 |
=E12*H12 |
|||||||||||||||||||
|
13 |
|
Кількість докупленого продукту П1 |
0 |
0 |
без обмежень |
5,75 |
=E13*H13 |
|||||||||||||||||||
|
14 |
|
Кількість докупленого продукту П2 |
0 |
0 |
без обмежень |
4,00 |
=E14*H14 |
|||||||||||||||||||
|
15 |
|
Кількість продукту П2, що конвертується |
0 |
0 |
50 |
0,25 |
=E15*H15 |
|||||||||||||||||||
|
16 |
|
Кількість продукту П1 на складі |
0 |
0 |
4 |
5,20 |
=E16*H16 |
|||||||||||||||||||
|
17 |
|
Кількість продукту П1, проданого за макс. ціною |
|
43 |
45 |
5,50 |
=E17*H17 |
|||||||||||||||||||
|
18 |
|
Кількість продукту П1, проданого за зниж. ціною |
0 |
0 |
без обмежень |
5,00 |
=E18*H18 |
|||||||||||||||||||
|
19 |
|
Кількість проданого продукту П2 |
7 |
0 |
без обмежень |
3,80 |
=E11*H19 |
|||||||||||||||||||
|
20 |
|
|
|
|
|
|
|
|
|
|||||||||||||||||
|
21 |
|
|
|
|
|
|
|
|
|
|||||||||||||||||
|
22 |
|
3. Функціональні обмеження: |
|
|
|
|
||||||||||||||||||||
|
23 |
|
Баланс з отримання і витрачання кожного продукту: |
|
|||||||||||||||||||||||
|
24 |
|
Залишок П1 |
=Виробництво! |
> = |
0 |
|
|
|
||||||||||||||||||
|
25 |
|
Залишок П2 |
=Виробництво! |
> = |
0 |
|
|
|
||||||||||||||||||
|
26 |
|
Загальна потужність основного процесу переробки сировини: |
||||||||||||||||||||||||
|
27 |
|
Поточна потужність |
=Е11+Е12 |
< = |
100 |
|
|
|
||||||||||||||||||
Рис. 6. Частина моделі, що знаходиться на аркуші Асортимент
|
|
A |
B |
C |
D |
||||||||||
|
1 |
|
ВИРОБНИЦТВО ПРОДУКЦІЇ |
|
|
||||||||||
|
2 |
|
|
|
|
|
|
|
|||||||
|
3 |
|
1. Норми отримання продукції |
|
|
||||||||||
|
4 |
|
Об’єкт переробки |
Норма виходу продукту (т) |
|
|
|||||||||
|
5 |
|
|
П1 |
П2 |
|
|
||||||||
|
6 |
|
С1 (1 т) |
0,15 |
0,85 |
|
|
||||||||
|
7 |
|
С2 (1 т) |
0,25 |
0,75 |
|
|
||||||||
|
8 |
|
П2 (1 т) |
0,50 |
0,50 |
|
|
||||||||
|
9 |
|
|
|
|
|
|
|
|||||||
|
10 |
|
2. Максимальні виробничі потужності (тис. т) |
||||||||||||
|
11 |
|
Процес |
Максим. |
|
||||||||||
|
12 |
|
потужність |
|
|||||||||||
|
13 |
|
Переробка сировини |
100 |
|
||||||||||
|
14 |
|
Конвертація продукту П2 |
50 |
|
||||||||||
|
15 |
|
|
|
|
|
|
|
|||||||
|
16 |
|
3. Плановані обсяги виробництва (тис. т) |
|
|||||||||||
|
17 |
|
Спосіб виробництва продукту |
Кількість (тис. т) |
|||||||||||
|
18 |
|
Виробництво продукту П1 із сировини С1 і С2 |
=СУММ(G19:G20) |
|||||||||||
|
19 |
|
у тому числі: |
|
із сировини С1 …… |
=D6*Асортимент!Е11 |
|||||||||
|
20 |
|
|
|
|
із сировини С2 …… |
=D6*Асортимент!Е12 |
||||||||
|
21 |
|
Виробництво продукту П2 із сировини С1 і С2 |
=СУММ(G19:G20) |
|||||||||||
|
22 |
|
у тому числі: |
|
із сировини С1 …… |
=Е6*Асортимент!Е11 |
|||||||||
|
23 |
|
|
|
|
із сировини С2 …… |
=Е6*Асортимент!Е12 |
||||||||
|
24 |
|
Виробництво продукту П1 конвертацією П2 |
=D8*Асортимент!Е15 |
|||||||||||
|
25 |
|
Неконвертований залишок продукту П2 |
=Е8*Асортимент!Е15 |
|||||||||||
Рис. 7. Частина моделі, що знаходиться на аркуші Виробництво
|
|
A |
B |
C |
D |
E |
|||||||
|
1 |
|
ОБЛІК МАРЖИНАЛЬНОЇ СОБІВАРТОСТІ ПРОДУКЦІЇ |
||||||||||
|
2 |
|
|
|
|
|
|
||||||
|
3 |
|
1. Вартість виробничих операцій |
|
|
||||||||
|
4 |
|
Операція |
Вартість (грн) |
|||||||||
|
5 |
|
Переробка 1 т сировини |
0,35 |
|||||||||
|
6 |
|
Вартість очищення продукту П1, виробленого з 1 т сировини |
0,10 |
|||||||||
|
7 |
|
Конверторна обробка 1 т продукту П2 |
0,25 |
|||||||||
|
8 |
|
|
|
|
|
|||||||
|
9 |
|
2. Прямі змінні витрати |
|
|||||||||
|
10 |
|
Вид витрат |
Сума (тис. грн) |
|
||||||||
|
11 |
|
На сировину |
=СУММ(Асортимент!І11:І12) |
|
||||||||
|
12 |
|
Переробка сировини |
=(Асортимент!Е11+Асортимент!Е11)*F5 |
|
||||||||
|
13 |
|
Очищення продукту П 1 |
=Виробництво!G18*F6 |
|
||||||||
|
14 |
|
Конверторна обробка П2 |
=Асортимент!E15*F7 |
|
||||||||
|
15 |
|
Докупівля продукту П 1 |
=Асортимент!І13 |
|
||||||||
|
16 |
|
Докупівля продукту П 2 |
=Асортимент!І14 |
|
||||||||
|
17 |
|
Підсумок |
|
СУММ(D11:D16) |
|
|||||||
Рис. 8. Частина моделі, що знаходиться на аркуші Витрати
Наявна кількість продукту П1 (клітина Е24) обчислюється за формулою
= Виробництво!G18 + Виробництво!G24 + E13 – E16 – E17 – E18,
а наявна кількість продукту П2 (клітина Е25) за формулою
= Виробництво!G21 + E14 + Виробництво!G25 – E15 – E19.
Завдання 3. Завдання полягає в побудові моделі для пророкування обсягу реалізації одного із продуктів фірми. Обсяг реалізації - це залежна змінна Y. У якості незалежних, пояснюючих змінних обраний: час – Х1 витрати на рекламу Х2, ціна товару Х3, середня ціна конкурентів Х4, індекс споживчих витрат Х5. Статистичні дані по всім змінним наведені в табл. У цьому прикладі п = 16, т = 5.
|
Y |
X1 |
Х2 |
Х3 |
Х4 |
X5 |
|
Обсяг реалізації |
Час |
Реклама |
Ціна |
Ціна конкурента |
Індекс споживчих витрат |
|
126 |
|
4 |
15 |
17 |
100 |
|
137 |
1 |
4.8 |
14.8 |
17.3 |
98.4 |
|
148 |
2 |
3.8 |
15.2 |
16.8 |
101.2 |
|
191 |
3 |
8.7 |
15.5 |
16.2 |
103.5 |
|
274 |
4 |
8.2 |
15.5 |
16 |
104.1 |
|
370 |
5 |
9.7 |
16 |
18 |
107 |
|
432 |
6 |
14.7 |
18.1 |
20.2 |
107.4 |
|
445 |
7 |
18.7 |
13 |
15.8 |
108.5 |
|
367 |
8 |
19.8 |
15.8 |
18.2 |
108.3 |
|
367 |
9 |
10.6 |
16.9 |
16.8 |
109.2 |
|
321 |
10 |
8.6 |
16.3 |
17 |
110.1 |
|
307 |
11 |
6.5 |
16.1 |
18.3 |
110.7 |
|
331 |
12 |
12.6 |
15.4 |
16.4 |
110.3 |
|
345 |
13 |
6.5 |
15.7 |
16.2 |
111.8 |
|
364 |
14 |
5.8 |
16 |
17.7 |
112.3 |
|
384 |
15 |
5.7 |
15.1 |
16.2 |
112.9 |
1. Використання інструмента Кореляція. Для проведення кореляційного аналізу виконаєте наступні дії: 1) дані для кореляційного аналізу повинні розташовуватися в суміжних діапазонах осередків; 2) виберіть команду Сервіс =>Аналіз даних; 3) у діалоговому вікні Аналіз даних виберіть інструмент Кореляція, а потім клацніть на кнопці ОК; 4) у діалоговому вікні Кореляція в поле «Вхідний інтервал» необхідно ввести діапазон осередків, що містять вихідні дані. Якщо виділені й заголовки стовпців, то встановити прапорець «Мітки в першому рядку»; 5) виберіть параметри виводу. У даному прикладі - установите перемикач «Новий робочий аркуш»
|
|
Обсяг реалізації |
Час |
Реклама |
Ціна |
Ціна конкурента |
Індекс споживчих витрат |
|
Стовпець 1 |
Стовпець 2 |
Стовпець 3 |
Стовпець 4 |
Стовпець 5 |
Стовпець 6 |
|
|
Обсяг реалізації |
1 |
|
|
|
|
|
|
Час |
0 678 |
1 |
|
|
|
|
|
Реклама |
0 646 |
0 106 |
1 |
|
|
|
|
Ціна |
0 233 |
0 174 |
-0 003 |
1 |
|
|
|
Ціна конкурента |
0 226 |
-0 051 |
0 204 |
0 698 |
1 |
|
|
Індекс споживчих витрат |
0.816 |
0 960 |
0 273 |
0 235 |
0 030 |
1 |
Аналіз матриці коефіцієнтів парної кореляції показує, що залежна змінна, т е обсяг реалізації, має тісний зв'язок з індексом споживчих витрат ( ryx5=0.816), з витратами на рекламу (ryx2=0.646) і згодом (ryx1 =0.678). Однак фактори Х2 і Х5 тісно зв'язані між собою (rХ1Х5 = 0.96), що свідчить про наявність мультиколінеарності. Із цих двох змінних залишимо в моделі Х5 - індекс споживчих витрат. У цьому прикладі п = 16, т = 5, після виключення незначущих факторів п = 16, m = 2.
2. Застосуєте інструмента Регресія для одержання наступного результату
|
Регресійна статистика |
|
|||||||||
|
Множинний R |
0 927 |
|
||||||||
|
R- квадрат |
0 859 |
|
||||||||
|
Нормований R -квадрат |
0 837 |
|
||||||||
|
Стандартна помилка |
41 473 |
|
||||||||
|
Спостереження |
16 000 |
|
||||||||
|
Дисперсійний аналіз |
|
|||||||||
|
|
Df |
SS |
MS |
F |
|
|||||
|
Регресія |
2 |
136358 334 |
68179 167 |
39 639 |
|
|||||
|
Залишок |
13 |
22360 104 |
1720 008 |
|
|
|||||
|
Разом |
1 |
158718438 |
|
|
|
|||||
|
|
Коефіцієнти |
Стандартна помилка |
t-статистика |
|||||||
|
В-Перетинання |
-1471.3143 |
259.7660 |
-5.6640 |
|||||||
|
Реклама |
9.5684 |
2.2659 |
4.2227 |
|||||||
|
Індекс споживчих витрат |
15.7529 |
2.4669 |
6.3858 |
|||||||
У другому стовпці втримуються коефіцієнти рівняння регресії а0, a1, а2. У третьому стовпці втримуються стандартні помилки коефіцієнтів рівняння регресії, а в четвертому - t-статистика, використовувана для перевірки значимості коефіцієнтів рівняння регресії.
Рівняння регресії залежності обсягу реалізації від витрат на рекламу й індексу споживчих витрат має вигляд: У=-1471.314+ 9.568Х1 +15.753X2.