

Micro-Nano Technology for Genomics and Proteomics BioMEMs - Ozkan
.pdf394 |
LEE ROWEN |
especially when data from other centers used a different sequencing chemistry that corrected errors or resolved ambiguities. Third, each center now had fewer clones to finish than it would otherwise have had in that redundant clones could simply be abandoned. Fourth, given that the 4-fold coverage of the draft sequence was insufficient for finishing, centers could start over with new clones, thereby avoiding the need to retrieve data and materials that were several months or years old. Fifth, the apportionment of the chromosomal regions and subsequent exchanges of data in some cases fostered a cooperative spirit among subsets of centers. (Interestingly, not all centers took advantage of the opportunity to use data from other centers because of the information technology effort involved with determining what data to ask for, changing file names to cohere with the center’s internal data-tracking conventions, mixing datasets, and the like.)
11.3.2.7. How the Chromosome Tiling Paths and Resultant Master Sequences were Constructed and Managed Although a detailed discussion of the overarching coordination involved in the reconstruction of the chromosome sequences is beyond the scope of this review, a few points can be made. Each chromosome was assigned a “chromosome coordinator” who was responsible for receiving map and sequence information from all the contributing centers and maintaining a periodically updated file of the clones in the finishing tiling path. In parallel, Greg Schuler and his team at NCBI constructed and kept track of the so-called “NT contigs,” which were non-redundant sequences pasted together from the sequences of overlapping source clones (Figure 11.7). Gaps were identified and annotated as to type. For example, a gap could be between ordered contigs in an unfinished source clone, or between source clones (with BAC end sequence data to suggest which clones might exist to span the gap), or between source clones with no information as to gap size. Additional resources such as fosmid libraries and cosmids from telomere regions [37] have been helpful for filling gaps and resolving other finishing problems. Input has also been solicited and received from collaborators interested in genomic features such as segmental duplications [37] and disease-related genes. Periodic assemblies of the genome were constructed by Jim Kent, David Haussler and their team at University of California at Santa Cruz, at NCBI, and at the European Bioinformatics Institute.
Assemblies of the finished human genome are available from:
UCSC : http://genome.ucsc.edu
NCBI: http://www.ncbi.nih.gov/mapview/map search.cgi
Ensembl: http://www.ensembl.org
In sum, coordination of the human genome project was challenging for several reasons. First, a score of centers from several countries needed to come to agreement on goals, policies, strategies and targets. Second, the centers needed to cooperate with each other and with the centralized resource providers such as NCBI and the Santa Cruz computational team. In essence, the genome project was “open source.” Third, quality assurance metrics had to be established, adhered to, and enforced. Fourth, the task was daunting in its complexity. And finally, fifth, unanticipated external factors altered the course of the project at various junctures, thereby imposing readjustments of strategies and resources.
SEQUENCING THE HUMAN GENOME |
395 |
11.4. ARE THERE LESSONS TO BE LEARNED FROM THE HUMAN GENOME PROJECT?
One could argue that the unique nature of the human genome project, the length of time it took to be done, and the various unanticipated developments that happened along the way are such that didactic generalizations of any significant import cannot be made. While this may be true, some concluding comments are nonetheless in order. First, there are some things that the leaders of the genome project did right:
Open data release policies and sharing of protocols.
Definition of standards for product quality and completeness.
Establishment of centralized resources.
Capture of the public imagination.
The decision to release unpublished sequence to the public so that others could use the data for their research has established a precedent for data sharing and an open source mentality that investigators in other areas might be encouraged to adopt. Early data release does pose two difficulties that need to be addressed. First, because career advancement in science is tied to publications, there must be a mechanism for investigators involved with large data gathering or technology development projects to receive proper credit for their contributions [40]. Second, the user groups need to be educated in the pitfalls associated with the dissemination of potentially erroneous data. For example, although the sequences of genomes being drafted now via a whole genome shotgun approach will be mostly correct, assembly errors will occur, especially in highly duplicated gene families. The sequences and analyses found in the centralized databases and posted on various web sites cannot be taken as gospel truth.
For the human genome project, the fact that there were quality standards and indications of quality in the database entries made it easier for users to evaluate the data critically. The Consortium even went so far as to conduct “quality control exercises” which involved the exchange of data among centers, with follow-up reports of detected errors. This enabled the community to develop reality-based standards and hold each other to account.
Central resources such as the genetic linkage maps, BAC end sequence database, the fingerprint contig database, assemblies of the draft genome, collections of transcribed (cDNA) sequences, and the like helped enormously with the difficult task of constructing the tiling paths for each of the chromosomes. Moreover, granting that the influence and importance of the world wide web is all-pervasive, it must be noted that the human genome project benefitted enormously from the ease of immediate access that the web has provided.
Finally, the architects of the human genome project were able to marshall public support. At key junctures, announcements of progress were made such that even if most “people on the street” did not know what the human genome project was, they had at least heard of it. A challenge for biology now is the articulation and implementation of a new vision with equal panache. Whether current contenders such as systems biology, nanotechnology, or predictive, preventive and personalized medicine will make the grade remains to be seen.
396 |
LEE ROWEN |
Additional potentially generalizable lessons from the human genome project include the following:
For a procedure to be useful it must be usable.
A process can only be as fast as its slowest step.
Procedures must be developed and integrated in light of a goal.
Reducing the number of players will make for a more efficient endeavor.
External developments will enable/force changes in strategy.
At the time the genome project began it was not obvious which procedures would be best. Indeed, technology improvements in any one area would have ramifications for others. For example, with the compute power and assembly programs available in 1991, shotgun assembly of a 150 kb BAC would have been deemed impossible. Yet by 1997 it was easy, and by year 2000, 150 megabase-sized genomes were being assembled using a whole genome shotgun approach [34]. Another example: Because companies such as Applied Biosystems kept pushing the envelope in their electrophoresis-based sequencing protocols by developing better enzymes, dyes, polymers, and detection machines, a sequencing technology that some visionaries thought would be transient turned out to be dominant. Competing sequencing technologies were not useful because they were not adequately reduced to practice. The lesson is that persons developing technologies must ask themselves: What will this be used for? Does it integrate well with the overall process? Will it scale? Will ordinary technicians be able to implement the technology? During the genome project, significant amounts of money were spent developing tools and resources that were never used, primarily because they did not meet the needs of the genome centers.
Slow steps in a process can be addressed by finding ways to speed them up or by eliminating them altogether. One of the major appeals of a whole genome shotgun approach is a bypass of the up-front mapping of source clones, a step that proved to be painfully slow during the human genome project. Mapping is now done after the fact by tapping the data in centralized source clone resources such as BAC end sequences and fingerprint clusters. A whole genome shotgun approach also has the advantage of eliminating the need to prepare thousands of shotgun libraries from source clones. However, with whole genome shotgun, obtaining an assembly that is faithful to the genome of interest becomes the most difficult and potentially slowest step. This is true especially for genomes with little map information or with significant allelic variation among copies of the chromosomes.
When it comes to integrating the steps of a process in light of an overall objective, compartmentalization is a danger especially for a large scale effort. During the genome project, most centers, especially the large ones, had groups of people focussed only on one major activity. For example, there would be an informatics group, a sequence production group, a machine development group, a finishing group, a mapping group, etc. What was often missing was a group of people who understood every step of the process from a handson perspective and how the steps fit together. Because of compartmentalization, groups focussed on their own goals and needs, which may or may not have served the overall goal well. For example, a production group concerned only about generating sequence reads might not have paid adequate attention to data quality, because they never actually looked at or used the data. For database design reasons, a software engineer might have thought that no information such as tags for sequencing chemistry should be embedded in the file
SEQUENCING THE HUMAN GENOME |
397 |
name of a sequencing read yet finishers typically wanted such information to be viewable in their sequence editor. Mappers often needed sequence data right away so they could make probes but production teams were wedded to an inflexible pipeline and would ignore the mappers’ requests. Recalling the symphony analogy, genome centers needed conductors else the orchestra played inharmonious tunes.
The number of centers involved in the sequencing of the human genome was sufficiently large that overall project coordination was difficult. Genomes are now being assigned to only one or a few sequencing centers, which conduces to greater efficiency. In the early stages of the human genome project, the “let a thousand flowers bloom” approach to strategy development made sense because the best answers were unclear. Innovation from several perspectives spread across numerous research laboratories was encouraged. Once the strategy matured and was used to produce large volumes of useful data, efficiency was valued over innovation, and novel strategies could not effectively compete. Moreover, had commitments to preexisting genome centers and a genuine desire for international participation in the sequencing of the genome not been an issue, it would have made sense to have done the project in a centralized rather than distributed manner once the scale-up was deemed feasible.
As for external curve balls, the disconnect between available physical maps and increasing sequencing capacity that existed circa 1997 made the intrusion of Celera almost inevitable. Even if Celera had not entered the scene, there was demand from biologists for the genome project to speed up. Given the choice between having half of the genome all finished and all of the genome half finished, biologists wanted the latter. In other words, an error-prone working draft came to be an acceptable goal because of the strong desire for access to genes. The draft turned out to be extremely useful, and it was produced at less cost than finished sequence. If this change in scope could have been anticipated, centralized resources such as the BAC end sequences and fingerprint databases might have been established earlier. But the moral here might be that comprehensive foresight is impossible. Perhaps the best that can be hoped for is the ability and willingness of individuals and organizations to adapt to changing circumstances, which the International Consortium did rather well.
A reference sequence for the human genome is now essentially finished. Although most of the participants in the genome project will fade into obscurity, their achievement will last. A foundation has been laid for further genetic studies that will improve our understanding of what makes us human. Moreover the genome project has shown that large-scale biology and technology endeavors can be done in the context of a cooperative network of laboratories and organizations that are willing to share data and resources. Although coordination of such undertakings is difficult, in the end the benefits to productivity are potentially great. This may be the most enduring lesson of the human genome project.
ACKNOWLEDGEMENTS
The author would like to thank Chad Nusbaum, Stephen Lasky, Gane Wong, Monica Dors, and Pat Ehrman for their comments on this review, Adam Felsenfeld for helpful discussion, and her many friends in the International Consortium and Celera for sharing ideas, data, and fun times during the sequencing of the human genome.
398 |
LEE ROWEN |
REFERENCES
[1]S. Aparicio, J. Chapman, E. Stupka, N. Putnam et al., Science, 297:1301–1310, 2002.
[2]BAC Resource Consortium, Nature, 409:953–958, 2001.
[3]J.A. Bailey, A.M. Yavor, L. Viggiano, D. Misceo, J.E. Horvath, N. Archidiacono, S. Schwartz, M. Rocchi, and E.E. Eichler. Am. J. Hum. Genet., 70:83–100, 2001.
[4]S. Batzoglou, D.B. Jaffe, K. Stanley, J. Butler, S. Gnerre, E. Mauceli, B. Berger, J.P. Mesirov, and E.S. Lander. Genome Res., 12:177–189, 2002.
[5]J.K. Bonfield, K. Smith, and R. Staden. Nucleic Acids Res., 23:4992–4999, 1995.
[6]E.Y. Chen, Y.C.Liao, D.H. Smith, H.A. Barrera-Saldana, R.E. Gelinas, and P.H. Seeburg. Genomics, 4:479– 497, 1989.
[7]G.M. Church and S. Kieffer-Higgins. Science, 240:185–188, 1988.
[8]L. Clarke and J. Carbon. Cell, 9:91–99, 1976.
[9]F.S. Collins, A. Patrinos, E. Jordan, A. Chakravarti, R. Gesteland, and L. Walters. Science, 282:682–689, 1998.
[10]P.L. Deininger. Anal. Biochem., 129:216–223, 1983.
[11]P. Deloukas, L.H. Matthews, J. Ashurst, J. Burton et al., Nature, 414:865–871, 2001.
[12]C. Dib, S. Faure, C. Fizames, D. Samson et al., Nature, 380:152–154, 1996.
[13]R. Drmanac, S. Drmanac, Z. Strezoska, T. Paunesku et al., Science, 260:1649–1652, 1993.
[14]I. Dunham, N. Shimizu, B.A. Roe, S. Chissoe et al., Nature, 402:489–495, 1999.
[15]B. Ewing and P. Green. Genome Res., 8:186–194, 1998.
[16]D. Gordon, C. Abajian, and P. Green. Genome Res., 8:195–202, 1998.
[17]D. Gordon, C. Desmarais, and P. Green. Genome Res., 11:614–625, 2001.
[18]N. Hattori, A. Fujiyama, T.D. Taylor, H. Watanabe et al., Nature, 405:311–319, 2000.
[19]R. Heilig, R. Eckenberg, J.L. Petit, N. Fonknechten et al., Nature, 421:601–607, 2003.
[20]X. Huang and A. Madan. Genome Res., 9:868–877, 1999.
[21]T.J. Hudson, L.D. Stein, S.S. Gerety, J. Ma et al., Science, 270:1945–1954, 1995.
[22]International Human Genome Mapping Consortium, Nature, 409:934–941, 2001.
[23]International Human Genome Sequencing Consortium, Nature, 409:860–921, 2001.
[24]P.A. Ioannou, C.T. Amemiya, J. Garnes, P.M. Kroisel, H. Shizuya, C. Chen, M.A. Batzer, and P.J. de Jong. Nat. Genet., 6:84–89, 1994.
[25]B.F. Koop, L. Rowan, W.Q. Chen, P. Deshpande, H. Lee, and L. Hood. Biotechniques, 14: 442–447, 1993.
[26]G.G. Mahairas, J.C. Wallace, K. Smith, S. Swartzell, T. Holzman, A. Keller, R. Shaker, J. Furlong, J. Young, S. Zhao, M.D. Adams, and L. Hood. Proc. Natl. Acad. Sci. U.S.A., 96:9739–9744, 1999.
[27]M.A. Marra, T.A. Kucaba, N.L. Dietrich, E.D. Green, B. Brownstein, R.K. Wilson, K.M. McDonald, L.W. Hillier, J.D. McPherson, and R.H. Waterston. Genome Res., 7:1072–1084, 1997.
[28]V.A. McKusick. Genomics, 5:385–387, 1989.
[29]M.J. Miller and J.L. Powell. J. Comput. Biol., 1:257–269, 1994.
[30]Mouse Genome Sequencing Consortium, Nature, 420:520–562, 2002.
[31]J.C. Mullikin and Z. Ning. Genome Res., 13:81–90, 2003.
[32]K.K. Murray. J. Mass Spectrom., 31:1203–1215, 1996.
[33]E.W. Myers, G.G. Sutton, H.O. Smith, M.D. Adams, and J.C. Venter. Proc. Natl. Acad. Sci., 99:4145–4146, 2002.
[34]E.W. Myers, G.G, Sutton, A.L.Dulcher, I.M. Dew et al., Science, 287:2196–2204, 2000.
[35]M.V. Olson. Science, 270:394–396, 1995.
[36]K. Osoegawa, A.G. Mammoser, C. Wu, E. Frengen, C. Zeng, J.J. Catanese, and P.J. deJong. Genome Res., 11:483–496, 2001.
[37]H. Riethman, A. Ambrosini, C. Castaneda, J. Finklestein, X.L. Hu, U. Mudunuri, S. Paul, and J. Wei. Genome Res., 14:18–28, 2004.
[38]L. Rowen, G. Mahairas, and L. Hood. Science, 278:605–607, 1997.
[39]L. Rowen, S.R. Lasky, and L. Hood. Methods in Microbiology, 28:155–192, 1999.
[40]L. Rowen, G.K. Wong, R.P. Lane, and L. Hood. Science, 289:1881, 2000.
[41]B.B. Rosenblum, L.G. Lee, S.L. Spurgeon, S.H. Khan, S.M. Menchen, C.R. Heiner, and S.-M. Chen. Nucleic Acids Res. 25: 4500–4504, 1997.
SEQUENCING THE HUMAN GENOME |
399 |
[42]F. Sanger, S. Nicklen, and A.R. Coulson. Proc. Natl. Acad. Sci. U.S.A., 74:5463–5467, 1977.
[43]H. Shizuya, B. Birren, U.J. Kim, V. Mancino, T. Slepak, Y. Tachiiri, and M. Simon. Proc. Natl. Acad. Sci. U.S.A., 89:8794–8797, 1992.
[44]H. Skaletsky, T. Kuroda-Kawaguchi, P.J. Minx, H.S. Cordum et al. Nature, 423:825–837, 2003.
[45]M. Strathmann, B.A. Hamilton, C.A. Mayeda, M.I. Simon, E.M. Meyerowitz, and M.J. Palazzolo. Proc. Natl. Acad. Sci. U.S.A., 88:1247–1250, 1991.
[46]S. Tabor and C.C. Richardson. Proc. Natl. Adac. Sci. U.S.A., 92:6339–6343, 1995.
[47]J.C. Venter, H.O. Smith, and L. Hood. Nature, 381:364–366, 1996.
[48]J.C. Venter, M.D. Adams, E.W. Myers, P.W. Li et al., Science, 291:1304–1351, 2001.
[49]R.H. Waterston, E.S. Lander, and J.E. Sulston. Proc. Natl. Acad. Sci., 99:3712–3716, 2002.
[50]J.L. Weber and E.W. Myers. Genome Res., 7:401–409, 1997.
[51]S. Zhao J. Malek, G. Mahairas, L. Fu, W. Nierman, J.C. Venter, and M.D. Adams. Genomics, 63:321–332, 2000.
III
Nanoprobes for Imaging, Sensing and Therapy
12
Hairpin Nanoprobes for
Gene Detection
Philip Santangelo, Nitin Nitin, Leslie LaConte and Gang Bao
Department of Biomedical Engineering, Georgia Institute of Technology and Emory University, Atlanta, GA 30332
12.1. INTRODUCTION
First hypothesized by Crick in 1958 [1], the central of dogma of biology states that DNA begets messenger RNA, which is then translated into protein. The ability to monitor this gene expression process and measure quantitatively the expression levels of mRNA can provide tremendous insight into normal and diseased states of living cells, tissues and animals, and clues to maintaining health and curing diseases. The first demonstration of mRNA being complementary to a gene and responsible for protein translation [2] was made by Hall and Spiegelman using a nucleic acid hybridization assay in which the reconstitution of the double-stranded DNA structure occurs only between perfect, or near-perfect complementary DNA strands, leading to a method of detecting complementary nucleotide sequences. In many ways this method is the precursor to both polymerase chain reaction (PCR) and other modern hybridization assays.
The development of technologies to measure gene expression levels has been playing an essential role in biology and medicine ever since the discovery of the double helical structure of DNA [3]. These technologies including oligonucleotide synthesis [4], PCR [5], Northern hybridization (or Northern blotting) [6], expressed sequence tag (EST) [7], serial analysis of gene expression (SAGE) [8], differential display [9], and DNA microarrays [10]. These technologies, combined with the rapidly increasing availability of genomic data for numerous biological entities, present exciting possibilities for understanding human health and disease. For example, pathogenic and carcinogenic sequences are increasingly being
404 |
PHILIP SANTANGELO ET AL. |
used as clinical markers for diseased states. However, the detection and identification of foreign or mutated nucleic acids is often difficult in a clinical setting due to the low abundance of diseased cells in blood, sputum, and stool samples. Consequently, the target sequence of interest is typically amplified by PCR or nucleic acid sequence-based amplification (NASBA). These assays are usually complex and prone to false-positives that hinder their clinical applications. For example, improper primer design can result in the amplification of unintended sequences or the primers could hybridize to each other and form “primer-dimer” amplicons [11]. Therefore, homogeneous assays that utilize fluorescent intercalating agents such as SybrGreen could generate a signal in the presence and absence of the pathogenic marker [12]. Alternatively, detection techniques that require the opening of the PCR tube for analysis (i.e., sequencing, electrophoresis, etc.) could lead to sample contamination. Clearly there is a need for a molecular probe that can detect nucleic acids with high specificity and generate a measurable signal upon target recognition to allow analysis in a sealed reaction tube.
Over the last decade or so, there is increasing evidence to suggest that RNA molecules have a wide range of functions in living cells, from physically conveying and interpreting genetic information, to essential catalytic roles, to providing structural support for molecular machines, and to gene silencing. These functions are realized through control of both the expression level of specific RNAs, and possibly through their spatial distribution. In vitro methods that use purified DNA or RNA obtained from cell lysate can provide a relative (mostly semi-quantitative) measure of mRNA expression level within a cell population; however they cannot reveal the spatial and temporal variation of mRNA within a single cell. Methods for gene detection in intact cells such as in situ hybridization [13] is capable of providing information of RNA expression level and localization in single cells; however, it relies on removal of the excess probes to achieve specificity, and therefore cannot be used with living cells. The ability to image specific mRNAs in living cells in real time can provide essential information on mRNA synthesis, processing, transport, and localization, and on the dynamics of mRNA expression and localization in response to external stimuli; it will offer unprecedented opportunities for advancement in molecular biology, disease pathophysiology, drug discovery, and medical diagnostics.
One approach to tagging and tracking endogenous mRNA transcripts in living cells is to use fluorescently labeled oligonucleotide probes that recognize specific RNA targets via Watson-Crick base pairing. In order for these probes to truly reflect the mRNA expression in vivo, they must satisfy a number of criteria: they need to be able to distinguish signal from background, convert target recognition directly into a measurable signal, and differentiate between true and false-positive signals. Further, these probes are required to have high sensitivity for quantifying low gene expression levels and fast kinetics for tracking alterations in gene expression in real time. In addition, they must be amenable to methods that enhance the internalization of the probes into cells with high efficiency.
In this chapter we will archive the design aspects, biological issues and challenges in developing nanostructured oligonucleotide probes for living cell gene detection. Although it is not possible to review all the relevant work in this chapter, we intend to provide extensive background information and detailed discussions on major issues, aiming to facilitate the quantitative and real-time mRNA measurements, especially in live cells and tissues.
HAIRPIN NANOPROBES FOR GENE DETECTION |
405 |
A
Loop
Molacular
Beacon
|
Stem |
|
Quencher |
Dye |
|
B |
|
|
Conventional Molecular Beacon |
|
|
Quencher |
|
|
|
Probe |
Dye |
|
Target |
|
CShared-stem Molecular Beacon Quencher
Probe |
Dye |
Target
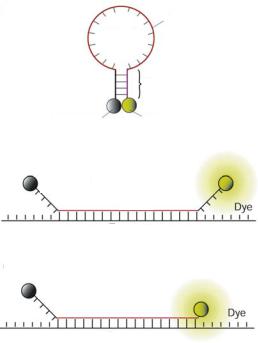
FIGURE 12.1. Illustrations of molecular beacons. (a) Molecular beacons are stem-loop hairpin oligonucleotide probes labeled with a reporter fluorophore at one end and a quencher molecule at the other end. (b) Conventional molecular beacons are designed such that the short complementary arms of the stem are independent of the target sequence. (c) Shared-stem molecular beacons are designed such that one arm of the stem participates in both stem formation and target hybridization.
12.2. NANOPROBE DESIGN ISSUES FOR HOMOGENEOUS ASSAYS
The detection and quantification of specific mRNAs require probes to have high sensitivity and specificity, especially for low abundance genes and with a small number of diseased cells in clinical samples. Further, for detecting genetic alterations such as mutations and deletions, the ability to recognize single nucleotide polymorphisms (SNPs) is essential. When designed properly, hairpin nucleic acid probes have the potential to be highly sensitive and specific. As shown in Figure 12.1, one class of such probes is known as molecular beacons, which are dual-labeled oligonucleotide probes with a fluorophore at one end and a quencher at the other end [14]. They are designed to form a stem-loop structure in the absence of a complementary target so that fluorescence of the fluorophore is quenched. Hybridization with target nucleic acid in solution or in a living cell opens the hairpin and physically separates the fluorophore from quencher, allowing a fluorescence signal to be emitted upon excitation. Thus, molecular beacons enable a homogenous assay format where background is low. The design of the hairpin structure provides an independently adjustable energy penalty for hairpin opening which improves probe specificity [15, 16]. The ability to transduce target recognition directly into a fluorescence signal with high