

Micro-Nano Technology for Genomics and Proteomics BioMEMs - Ozkan
.pdf456 |
BARKUR S. SHASTRY |
[38]M.M. Goldrick. Hum. Mutat., 18:190, 2001.
[39]I. Gut. Hum. Mutat., 17:475, 2001.
[40]M.K. Halushka, J.B. Fan, K. Bentley, L. Hsie, N.P. Shen, A. Weder, R. Cooper, R. Lipshutz, and A. Chakravarti. Nat. Genet. 22:239, 1999.
[41]J. Hoffstedt, L.L. Andersson, L. Persson, B. Isaksson, and P. Arner. Diabetologia, 45:584, 2002.
[42]K.N. Hogeveen, P. Cousin, M. Pugeat, D. Dewailly, B. Soudan, and G.L. Hammond. J. Clin. Invest., 109:973, 2002.
[43]Y. Horikawa, N. Oda, N.J. Cox, L. Xiangquan, M. Orho-Melander, M. Hara, Y. Hinokio, and T.H. Lindner. Nat. Genet., 26:163, 2000.
[44]T. Ikeda, A. Mabuchi, A. Fukuda, A. Kawakami, R. Yamada, S. Yamamoto, K. Miyoshi, N. Haga, H. Hiraoka, Y. Takatori, H. Kawaguchi, K. Nakamura, and S. Ikegawa. J. Bone Mineral Res., 17:1290, 2002.
[45]S. Jenkins and N. Gibson. Comp. Funct. Genomics, 3:57, 2002.
[46]G.C.L. Johnson, L. Esposito, B.J. Barratt, A.N. Smith, J. Heward, G. DiGenova, H. Ueda, H.J. Cordell, I.A. Eaves, F. Dudbridge, R.C.J. Twells, F. Payne, W. Hughes, S. Nutland, H. Stevens, P. Carr, E. TuomilehtoWolf, J. Tuomilehto, S.C.L. Gough, D.G. Clayton, and J.A. Todd. Nat. Genet., 29:233, 2001.
[47]B. Jordan, A. Charest, J.F. Dowd, J.P. Blumenstiel, R-F. Yeh, A. Osman, D.E. Housman, and E.S. Lander.
Proc. Natl. Acad. Sci. U.S.A., 99:2942, 2002.
[48]M. Kimura. The Neutral Theory of Molecular Evolution. Cambridge, Cambridge University Press, 1983.
[49]M.L. Koschinsky, M.B. Boffa, M.E. Nesheim, B. Zinman, A.J.G. Hanley, S.B. Harris, H. Cao, and R.A. Hegele. Clin. Genet., 60:345, 2001.
[50]V.N. Kristensen, D. Kelefiotis, T. Kristensen, and A.L. Borresen-Dale. Biotechniques, 30:318, 2001.
[51]T. Kubota, M. Horie, M. Takano, H. Yoshida, K. Takenaka, E. Watanabe, T. Tsuchiya, H. Otani, and S. Sasayama. J. Cardiovasc. Electrophysiol., 12:1223, 2001.
[52]P.-Y. Kwok. Pharmacogenomics, 1:95, 2000.
[53]P.-Y. Kwok. Ann. Rev. Genomics Hum. Genet., 2:235, 2001.
[54]E. Lai. Genome Res., 11:927, 2001.
[55]E. Lai, J. Riley, I. Purvis, and A. Roses. Genomics, 54:31, 1998.
[56]E.S. Lander and N.J. Schork. Science, 265:2037, 1994.
[57]J. Lazarou, B.H. Pomeranz, and P.N. Corey. JAMA, 279:1200, 1998.
[58]B. Lemieux. Curr. Genomics, 1:301, 2000.
[59]T.D. Levan, J.W. Bloom, T.J. Bailey, C.L. Karp, M. Halonen, F.D. Martinez, and D. Vercelli. J. Immunol., 167:5838, 2001.
[60]D.A. Liberles. Genome Biol., 2:1, 2001.
[61]Q. Liu and S.S. Sommer. PCR Methods Appl., 4:97, 1994.
[62]K.J. Livak, J. Marmaro, and J.A. Todd. Nat. Genet., 9:341, 1995.
[63]H.D. Lohrer and U. Tangen. Pathobiol., 68:283, 2000.
[64]N. Martin, D. Boomsma, and G. Machin. Nat. Genet., 17:387, 1999.
[65]E.R. Martin, W.K. Scott, M.A. Nance, R.L. Watts, J.P. Hubble, W.C. Koller, K. Lyons, R. Pahwa, M.B. Stern, A. Colcher, B.C. Hiner, J. Jankovic, W.G. Ondo, F.H. Allen, C.G. Goetz, G.W. Small, D. Masterman, F. Mastaglia, N.G. Laing, J.M. Stajich, R.C. Ribble, M.W. Booze, A. Rogala, M.A. Hauser, F.Y. Zhang, R.A. Gibson, L.T. Middleton, A.D. Roses, J.L. Haines, B.L. Scott, M.A. Pericak-Vance, and J.M. Vance. JAMA, 286:2245, 2001.
[66]E.R. Martin, J.R. Gilbert, E.H. Lai, J. Riley, A.R. Rogala, B.D. Slotterbeck, C.A. Sipe, J.M. Grubber, L.L. Warren, P.M. Conneally, A.M. Saunders, D.E. Schmechel, I. Purvis, M.A. Pericak-Vance, A.D. Roses, and J.M. Vance. Genomics, 63:7, 2000.
[67]M. Matsushita, H. Miyakawa, A. Tanaka, M. Hijikata, K. Kikuchi, H. Fujikawa, J. Arai, S. Sainokami, K. Hino, I. Terai, S. Mishiro, and M.E. Gershwin. J. Autoimmunity, 17:251, 2001.
[68]J.J. McCarthy and R. Hilfiker. Nat. Biotechnol., 18:505, 2000.
[69]L.C. McCarthy, D.A. Hosford, J.H. Riley, M.I. Bird, N.J. White, D.R. Hewett, S.J. Perontka, L.R. Griffiths, P.R. Boyd, R.A. Lea, S.M. Bhatti, L.K. Hosking, C.M. Hood, K.W. Jones, A.R. Handley, R. Rallan, K.F. Lewis, A.J.M. Yeo, P.M. Williams, R.C. Priest, P. Khan, C. Donnelly, S.M. Lumsden, J. O’Su’livan, C.G. See, D.H. Smart, S. Shaw-Hawkins, J. Patel, T.C. Langrish, W. Feniuk, R.G. Knowles, M. Thomas, V. Libri, D.S. Montgomery, P.K. Monaco, C.F. Xu, C. Dykes, P.P.A. Humphrey, A.D. Roses, and J.J. Purvis. Genomics, 78:135, 2001.
[70]J.L. McClay, K. Sugden, H.G. Koch, S. Higuchi, and I.W. Craig. Anal. Biochem., 301:200, 2002.
SNPs AND HAPLOTYPES |
457 |
[71]D.C. McClean, I. Spruill, S. Gevao, E.Y.S. Morrison, O.S. Bernard, G. Argyropoulos, and W.T. Garvey. Hum. Biol., 75:147, 2003.
[72]O.G. McDonald, E.Y. Krynetski, and W.E. Evans. Pharmacogenet., 12:93, 2002.
[73]C.A. Mein, B.J. Barratt, M.G. Dunn, T. Siegmund, A.N. Smith, L. Esposito, S. Nutland, H.E. Stevens, A.J. Wilson, M.S. Phillips, N. Jarvis, S. Law, M. de Arruda, and J.A. Todd. Genome Res., 10:330, 2000.
[74]U.A. Meyer and U.M. Zanger. Ann. Rev. Pharmacol. Toxicol., 37:269, 1997.
[75]M.M. Mhlanga and L. Malmberg. Methods, 25:463, 2001.
[76]T. Nakayama, M. Soma, S. Saito, J. Honye, J. Yajima, D. Rahmutula, Y. Kaneko, M. Sato, J. Uwabo, N. Aoin, K. Kosuge, M. Kunimoto, K. Kanmatsuse, and S. Kokubun. Am. Heart J., 143:797, 2002.
[77]J.C. Mullikin, S.E. Hunt, C.G. Cole, B.J. Moltimore, C.M. Rice, J. Burton, L.H. Matthews, R. Pavitt, R.W. Plumb, S.K. Sims, R.M.R. Ainscough, J. Attwood, J.M. Bailey, K. Barlow, R.M.M. Bruskiewich, P.N. Butcher, N.P. Carter, Y. Chen, C.M. Clee, P.C. Coggill, J. Davies, R.M. Davies, E. Dawson, M.D. Francis, A.A. Joy, R.G. Lambel, C.F. Langford, J. MaCarthy, V. Mall, A. Moreland, E.K. Overton-Larty, M.T. Ross, L.C. Smith, C.A. Steward, J.E. Sulston, E.J. Tinsley, K.J. Turney, D.L. Willey, G.D. Wilson,
A.A.McMurray, I. Dunham, J. Rogers, and D.R. Bentley. Nature, 407:516, 2000.
[78]M. Nakajima, Y. Fujiki, K. Noda, H. Ohtsuka, H. Ohkuni, S. Kyo, M. Inoue, Y. Kuroiwa, and T. Yokoi.
Drug Metabol. Disposit., 31:687, 2003.
[79]J.R. Nelson, Y.C. Cai, T.L. Giesler, J.W. Farchaus, S.T. Sundaram, M. Ortiz-Rivera, L.P. Hosta, P.L. Hewitt, J.A. Mamone, C. Palaniappan, and C.W. Fuller. Biotechniques, 32:S44, 2002.
[80]M. Neville, R. Selzer, B. Aizenstein, M. Maguire, K. Hogan, R. Walton, K. Welsh, B. Neri, and M. de Arruda. Biotechniques, 32:S34, 2002.
[81]D.A. Nickerson, S.L. Taylor, K.M. Weiss, A.G. Clark, R.G. Hutchinson, J. Stengard, V. Salomaa, E. Vartiainen, E. Baerwinkel, and C.F. Sing. Nat. Genet., 19:233, 1998.
[82]R. Nielsen. Genet., 154:931, 2000.
[83]R. Nielsen and M. Slatkin. Evolution, 54:44, 2000.
[84]B. Niesler, T. Flohr, M.M. Nothen, C. Fischer, M. Rietschel, E. Franzek, M. Albus, P. Propping, and G.A. Rappold. Pharmacogenet., 11:471, 2001.
[85]G.E. O’Keefe, D.L. Hybki, and R.S. Munford. J. Trauma-injury Infect. Crit. Care, 52:817, 2002.
[86]A. Oliphant, D.L. Barker, J.R. Stuelpnagel, and M.S. Chee. Biotechniques, 32:S56, 2002.
[87]M. Orita, H. Iwahana, H. Kanazawa, K. Hayashi, and T. Sekiya. Proc. Natl. Acad. Sci. U.S.A., 86:2766, 1989a.
[88]M. Orita, Y. Suzuki, T. Sekiya, and K. Hayashi. Genomics, 5:874, 1989b.
[89]H.Y. Park, T. Nabika, Y. Jang, H.M. Kwon, S.Y. Cho, and J. Masuda. Hyperten. Res., 25:389, 2002.
[90]N. Patil, A.J. Berno, D.A. Hinds, W.A. Barrett, J.M. Doshi, C.R. Hacker, C.R. Kautzer, D.H. Lee,
C.Marjoribanks, D.P. McDonough, B.T.N. Nguyen, M.C. Norris, J.B. Sheehan, N. P. Shen, D. Stern, R.P. Stokowski, D.J. Thomas, M.O. Trulson, K.R. Vyas, K.A. Frazed, S.P.A. Fodor, and D.R. Cox. Science, 294:1719, 2001.
[91]M. Pirmohamed and B.K. Park. Trends Pharmacol. Sci., 22:298, 2001.
[92]M. Pitarque, O. Von Richter, B. Oke, H. Berkkan, M. Oscarson, and M. Ingelman-Sundberg. Biochem. Biophys. Res. Comm., 284:455, 2001.
[93]R. Plomin, M. U. J. Owen, and P. McGuffin, Science 264, 1733, 1994.
[94]X.Q. Qi, S. Bakht, K.M. Devos, M.D. Gale, and A. Osbourn. Nucl. Acids Res., 29:U68, 2001.
[95]A. Rafalski. Curr. Opinion Plant. Biol., 5:94, 2002.
[96]D.E. Reich, M. Cargil, S. Bolk, J. Ireland, P.C. Sabeti, D.J. Richter, T. Lavery, R. Kouyoumjian, S.F. Farhadian, R. Ward, and E.S. Lander. Nature, 411:199, 2001.
[97]M.J. Rieder, S.L. Taylor, A.G. Clark, and D.A. Nickerson. Nat. Genet., 22:59, 1999.
[98]J.H. Riley, C.J. Allan, E. Lai, and A. Roses. Pharmacogenomics, 1:39, 2000.
[99]C.P. Rodi, B. Darnhofer-Patel, P. Stanssens, M. Zabeau, and D. Van den Boom. Biotechniques, 32:S62, 2002.
[100]A.D. Roses. Ann. Rev. Med., 47:387, 1996.
[101]M.V. Rudorfer, E.A. Lane, W.H. Chang, M. Zhang, and W.Z. Potter. Br. J. Clin. Pharmacol., 17:433, 1984.
[102]R.K. Saiki, P.S. Walsh, C.H. Levenson, and H.A. Erlich. Proc. Natl. Acad. Sci. U.S.A., 86:6230, 1989.
[103]B.A. Salisbury, M. Pungliya, J.Y. Choi, R.H. Jiang, X.J. Sun, and J.C. Stephens. Mutat. Res. Fundamentals Mol. Mech. Mutagenesis, 526:53, 2003.
[104]R.S. Schifreen, D.R. Storts, and A.M. Buller. Biotechniques, 32:S14, 2002.
458 |
BARKUR S. SHASTRY |
[105]N.J. Schorx, D. Fallin, and S. Lanchbury. Clin. Genet., 58:250, 2000.
[106]F. Sesti, G.W. Abbott, J. Wei, K.T. Murray, S. Saksena, P.J. Schwartz, S.G. Priori, D.M. Roden, A.L. George, and S.A.N. Goldstein. Proc. Natl. Acad. Sci. U.S.A., 97:10613, 2000.
[107]B.S. Shastry. J. Hum. Genet., 47:561, 2002.
[108]B.S. Shastry. Int. J. Mol. Med., 11:379, 2003.
[109]V.C. Sheffield. Proc. Natl. Acad. Sci. U.S.A., 86:232, 1989.
[110]M.M. Shi. Clin. Chem., 47:164, 2001.
[111]M.J. Sobrido, B.L. Miller, N. Havlioglu, V. Zhukareva, Z.H. Jiang, Z.S. Nasreddine, V.M.Y. Lee, T.W. Chow, K.C. Wilhelmsen, J.L. Cummings, J.Y. Wu, and D.H. Geschwind. Arch. Neurol., 60:698, 2003.
[112]M. Spiecker, H. Darius, T. Hankeln, M. Soufi, H. Friedl, J.R. Schaefer, E.R. Schmidt, D.C. Zeldin, and J.K. Liao. Circulation, 104(supl):314, 2001.
[113]A. Stevens, D. Ray, A. Alansari, A. Hajeer, W. Thomson, R. Donn, W.E.R. Ollier, J. Worthington, and J.R.E. Davis. Arthritis Rheumatism, 44:2358, 2001.
[114]S. Subramanian and S. Kumar. Genome Res., 13:838, 2003.
[115]J. Sugatani, K. Yamakawa, K. Yoshinari, T. Machida, H. Takagi, M. Mori, S. Kakizaki, T. Sueyashi, M. Negishi, and M. Miwa. Biochem. Biophys. Res. Comm., 292:492, 2002.
[116]A.C. Syvanen. Hum. Mutat., 13:1, 1999.
[117]P. Taillon-Miller, I. Bauer-Sardina, N.L. Saccone, J. Putzel, M. Laitnen, A. Cao, J. Kere, and G. Pilia. Nat. Genet., 25:324, 2000.
[118]F.K. Tan, N. Wang, M. Kuwana, R. Chakraborty, C.A. Bona, D.M. Milewicz, and F.C. Arnett. Arthritis Rheumatism, 44:893, 2001.
[119]S. Taygi, D.P. Bratu, and F.R. Kramer. Nat. Biotechnol., 16:49, 1998.
[120]F.J. Tsai, H.C. Wu, H.Y. Che, H.F. Lu, C.D. Hsu, and W.C. Chen. Urologia Int., 70:278, 2003.
[121]N. Unno, T. Nakamura, H. Mitsuoka, T. Saito, K. Miki, K. Ishimaru, J. Sugatani, M. Miwa, and S. Nakamura. Surgery, 132:66, 2002.
[122]J. Voorberg, J. Roelse, R. Koopman, H. Buller, F. Berends, J.W. Tencate, K. Mertens, and J.A. Vanmourik. Lancet, 343:1535, 1994.
[123]U. Wandegren, R. Kaiser, J. Sanders, and L. Hood. Science, 241:1077, 1988.
[124]L.Z. Wang, T. Habuchi, T. Takahashi, K. Mitsumori, T. Kamoto, Y. Kakehi, H. Kakinuma, K. Sato, A. Nakamura, O. Ogawa, and T. Kato. Carcinogenesis, 23:257, 2002.
[125]R. Waterland and C. Garza. Am. J. Clin. Nutr., 69:179, 1999.
[126]M.K. Weabman, C.C. Huang, J. DeYoung, E.J. Carlson, T.R. Taylor, M. de la Cruz, S.J. Johns, D. Stryke,
M.Kawamoto, T.J. Urban, D.L. Kroetz, T.E. Ferrin, A.G. Clark, N. Risch, I. Herskowitz, and K.M. Giacomini. Proc. Natl. Acad. Sci. U.S.A., 100:5896, 2003.
[127]K.M. Weiss and J.D. Terwilliger. Nat. Genet., 26:151, 2000.
[128]X.Y. Wen, R.A. Hegele, J. Wang, D.Y. Wang, J. Cheung, M. Wilson, M. Yahyapour, Y. Bai, L.H. Zhuang,
J.Skaug, T.K. Young, P.W. Connelly, B.F. Koop, L.C. Tsui, and A.K. Stewart. Hum. Mol. Genet., 12:1131, 2003.
[129]S.J. Wiezorek and G.J. Tsongalis. Clinica Chemica Acta, 308:1, 2001.
[130]T. Yoshino, H. Takeyama, and T. Matsunaga. Electrochem., 69:1008, 2001.
[131]R. Youil, B.W. Kemper, and R.G.H. Cotton. Proc. Natl. Acad. Sci. U.S.A., 92:87, 1995.
[132]L.P. Zhavo, S.Y.S. Li, and N. Khalid. Am. J. Hum. Genet., 72:1231, 2003.
[133]Y. Zhu, M.R. Spitz, L. Lei, G.B. Mills, and X.F. Wu. Cancer Res., 61:7825, 2001.
15
Control of Biomolecular Activity by Nanoparticle Antennas
Kimberly Hamad-Schifferli
Department of Mechanical Engineering and the Division of Biological Engineering, Massachusetts Institute of Technology, 77 Massachusetts Avenue 56-341C, Cambridge, MA 02139
15.1. BACKGROUND AND MOTIVATION
Biological molecules are now being increasingly viewed as machines due to the remarkable complexity, accuracy, and efficiency of their functions. Consequently, there is a developing effort to harness the engineering of Nature by going beyond characterizing biological systems and investigating methods for direct manipulation. This effort has been furthered by the enormous progress in understanding the complex mechanisms and structures of biological systems. Largely fueled by the advances in biological and biochemical tools and also characterization techniques such as x-ray crystallography and NMR, this knowledge has reached a point where one can describe the structure and mechanisms of large and complex biological molecules in molecular detail. Consequently, direct manipulation of biomolecular activity is an attractive route for the development of new types of hybrid systems that utilize the engineering of Nature.
In order to give a sense of how others have approached this problem, four examples of harnessing biological systems are described below. It is important to note that these examples do not comprise an exhaustive list as this field is changing rapidly, and numerous new techniques are being discovered continually. Instead, it is intended to give a sense of the diverse approaches to manipulating biological machines.
15.1.1. ATP Synthase as a Molecular Motor
ATP Synthase (also called proton-translocating ATP synthase or proton pumpingATPase) is a membrane protein which is the most abundant enzyme [65]. Its function is
460 |
|
KIMBERLY HAMAD-SCHIFFERLI |
ADP + Pi |
|
|
ATP |
|
|
? |
|
|
? |
? |
F1 |
|
lipid membrane |
F0 |
FIGURE 15.1. Schematic of ATP Synthase, consisting of the F1 and F0 subunits.
to create proton gradient across a membrane using the energy gotten from converting ATP to ADP. Alternatively, it can have the opposite function and use the energy from a proton gradient to synthesize ATP from ADP. ATP Synthase outperforms artificial motors, which operate at an efficiency of 35% to 96% in electrical to mechanical energy conversion. It is also an important enzyme as ATP is universally used as fuel in living organisms. It is a large protein (500kD) and has a complex structure. It is composed of the subunits F0, which spans the membrane, and the F1 subunit which sits above the membrane (Figure 15.1). The F1 subunit is comprised of the α and β subunits which are arranged with three fold symmetry. In catalyzing these reactions, the entire F1 subunit undergoes a rotational motion. The protein acts as a molecular stepper motor with ATP as fuel, generating torques of 100pN·nm. Although there are many motor proteins that have been well studied, rotation is an unusual motion in proteins, and outside of bacterial flagellum examples of molecular rotary motors are rare. Through x-ray crystallography of the F1 subunit [1], a molecular level description of the catalysis and associated motion has been determined. Because the efficiency of this motion is remarkable with respect to artificial motors, and sophisticated knowledge of the mechanism has been studied, it is desirable to harness the conformational change which can be simply induced by introduction of ATP. In order to harness this rotational motion and exploit the enzyme as a molecular motor, the F1 subunit was engineered with histidines in key positions which act as attachment points to a surface. In addition, one of these sites serve as an attachment point for streptavidin to attach a Ni bar (150 nm by 1400 nm) so the rotational motion can be visualized by microscopy [54]. The engineered enzyme is immobilized on a surface at specific attachment sites put in by fabrication. ATP is introduced by flushing a solution over the chip, and in the presence of ATP the Ni propeller arm spins, as viewed by microscopy. This motion is performed with calculated efficiencies of 50%–80% depending on the ATP concentration, and with torques of 19–20pN·nm. However, utilizing it in its natural environment is desirable, and in the form of a fabricated device it is difficult to envision implementation in real biological systems. However, this example illustrates that knowledge of the structure and mechanism of even sophisticated enzymes coupled with rational design can result in harnessing biological machines in novel ways. Ultimately, one could create devices that exploit single biomolecules for mechanical applications.
CONTROL OF BIOMOLECULAR ACTIVITY BY NANOPARTICLE ANTENNAS |
461 |
15.1.2. Biological Self Assembly of Complex Hybrid Structures
Biology exploits principles of self-assembly to construct complex structures out of both organic and inorganic materials with great precision. On the other hand, we have constructed artificial systems largely employing top down approaches, such as microfabrication. However, these approaches are limited in constructing complex devices and machines of nanometer size dimensions. Also, they are much less efficient than how Nature achieves complex structures, and often require severe reaction conditions or harsh or toxic reagents. Consequently, there has been a great effort towards discovering how to utilize biological systems to construct inorganic/biological systems or at least mimic the key processes. Of particular interest is self-assembly on nanoscale dimensions, which would have important ramifications for device applications.
One compelling example of biological self assembly is biomineralization, or the crystallization of inorganic structures. This is seen exemplified in natural materials such as hard shells, bone, and teeth, and also in organisms such as a diatoms and magnetotactic bacteria. Biological systems have determined routes for making novel structures that are composites of inorganic and organic material, which often exceed the mechanical properties of pure inorganic materials. If created artificially, these structures often require high temperatures and pressures, in stark contrast to their biological counterparts which are synthesized in atmospheric conditions. This unique synthesis is achieved by utilization of proteins that recognize specific crystal faces and thus control the crystallization morphology [2, 11, 12, 20]. Biological strategies for assembling materials is much more complex than the simple crystallization we can do artificially. As a result, many have studied the proteins that can recognize crystal surfaces [53]. In order to exploit the properties of these proteins, bacteriophages have been genetically engineered so that they display these peptides on their coats. This allows use of the bacteriophage to crystallize nanostructures of unusual composition such as semiconductors (ZnS, GaAs) [60] and magnetic materials (CoPt, FePt) [44]. Also, the protein coats of viruses have been recognized as unique encapsulations for nanoparticle mineralization, as they are well defined in shape and size. A natural occurring example of this is the iron storage protein ferritin, which is a spherical protein made of 24 subunits. It stores iron in the form of a 6nm ferric oxohydroxide particle in its 7nm cavity. As an artificial analogue of ferritin, the cowpea chlorotic mottle virus (CCMV) has been manipulated to mineralize nanoparticles of novel materials [21]. The shell of the CCMV consists of 180 monomer proteins assembled into an icosahedron with a cavity 18nm in diameter, making it a suitable vessel for mineralization of nanoparticles [40, 60]. By changing chemical conditions of the interior of the encapsulation, 15nm nanoparticles of paratungstate (H2W12O1042−) could be formed. The resulting self-assembled nanoparticles were highly crystalline, as evidenced by crystalline lattice fringes in TEM, and had narrow size distributions.
Many have recognized that DNA has great potential for organizing biomolecules and inorganic/organic structures on the nanometer length scale [52]. DNA has intrinsic length scales that make it a suitable candidate for this purpose—it is Ångstroms in width, and can be as long as millimeters in length [38, 46, 47]. More importantly, the chemistry of base pairing in DNA imparts specificity of hybridization, and DNA strands can find their complements in solution amongst thousands of other candidates. Advances in chemical

462 |
KIMBERLY HAMAD-SCHIFFERLI |
modification of DNA have resulted in numerous methods for linking it to small molecules, surfaces, and nanoparticles [43]. Thus, many have looked to use DNA as a means of spatially organizing nanostructures. Gold nanoparticles of two different sizes (5 nm and 10 nm) are covalently attached to DNA strands of different sequences. By dictating the sequence of the complement added to the solution, different spatial arrangements of nanoparticles can be achieved. For example, both homoand hetero-dimers can be created, as well as different arrangements of trimers. Through rational sequence design, spatially extended structures of DNA [38, 61] as well as unusual structures such as loops, hairpins, cubes, and truncated octahedra can be self-assembled [19]. Furthermore, these structures have been decorated with gold nanoparticles, and structures were ascertained through atomic force microscopy (AFM) [62] (Figure 15.2b).
While structures with complexity approaching fabricated transistors have not been created yet, this is an important step towards using biology to template and spatially organize molecules and objects for applications in devices.
a
b
FIGURE 15.2. DNA self assembled structures, a) cube shape from self-assembled DNA oligonucleotides, from [19], b) DNA tiling decorated with nanoparticles, from [62].
CONTROL OF BIOMOLECULAR ACTIVITY BY NANOPARTICLE ANTENNAS |
463 |
15.1.3. DNA as a Medium For Computation
Biological systems are attractive as computational media. All organisms can be viewed as computers, as even simple organisms such as bacteria can accept inputs (i.e., toxins located nearby) and respond according to the information encoded in their DNA (i.e., the bacterium moves away). Biological systems all have superior computational efficiencies, processing power, and information storage densities over traditional computers, in addition to the ability to fully self-replicate, which so far has not been reproduced artificially. Consequently, exploiting biological for computational purposes has been pursued.
The first experimental realization of a biological system as a computer was by Adelman [3] in which the process of DNA hybridization in solution was used to solve a model mathematical problem. The traveling salesman problem ascertains the best route between multiple cities without repeating cities, and is normally intractable for traditional computers where the number of cities is large. Here, the possible mathematical solutions were represented by DNA strands of different sequences. A connection between two cities was represented by formation of a hybrid pair between those two points. All possible combinations were formed in solution, but one could filter out combinations that do not follow the constraints of the problem. If the problem was solved successfully, DNA of a certain length and sequence would remain. Adleman showed that using DNA to solve the traveling salesman problem was successful for a simplified version, but in theory it can be utilized on a larger version for which the solution is unattainable if approached by traditional computers. This approach offers new capabilities to computation, namely massively parallel computing. Because everything is in solution, large numbers of different answers can be sampled simultaneously. As a result, other formats for computation have been realized in which mathematical problems are represented by DNA tiles that form extended two dimensional structures according to whether they are a solution or not [61]. In addition, analogs of binary logic functions have been created out of DNA enzymes [56], where “1” and “0” are represented by fluorescence states of a product of the DNA enzyme. Also, simple circuit elements such as ring oscillators and bistable switches have been constructed using transcriptional machinery [23, 24].
15.1.4. Light Powered Nanomechanical Devices
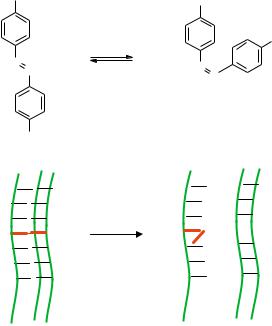
One novel way to manipulate biomolecules is by decorating them with organic molecules which isomerize upon optical excitation, allowing light to control the biomolecule. Perhaps the most well studied molecule with this property is azobenzene (Figure 15.3a) which rotates the NNC bond angle by 120◦ in isomerization. It goes from the trans form to cis under optical excitation at λ = 365 nm, and in the reverse direction with λ = 420 nm or thermal excitation. Many have viewed this molecule as a molecular bistable switch powered by light. In addition, azobenzene can be linked to specific sites on a biomolecule (R groups), enabling the use of light to induce a drastic conformational change in the biomolecule.
Along these lines, azobenzene has been used to photoactivate DNA dehybridization [5]. It can be chemically attached to a phosphate backbone and substituted as a base in DNA during solid phase synthesis. In the trans form it does not perturb formation of a hybrid between its parent strand and its complement. However, in the cis form, it perturbs
464 KIMBERLY HAMAD-SCHIFFERLI
a |
R |
|
R |
|
|
|
|
|
|
? = 420nm |
R |
|
|
|
|
|
N |
|
N |
|
N |
|
|
|
? = 365nm |
N |
|
|
|
||
|
R |
|
|
b
h?
Triplex formed |
Triplex perturbed |
FIGURE 15.3. Light powered isomerization of a molecule. a) isomerization of azobenzene moiety upon light. b) utilization of isomerization of azobenzene to perturb DNA triplex formation.
the local structure in the DNA and formation of the hybrid pair is impeded. This has been used to manipulate DNA triplex formation by light (Figure 15.3b). Azobenzene is incorporated into one site on a DNA 13mer that can form a triplex structure with two other oligos. Upon UV illumination, the azobenzene converts from trans to cis, which in its non-planar form perturbs the local structure in the DNA in such a way that base pairing between the 13mer and its complements is weakened. As a result, the triplex is destabilized, as measured by melting curves of the complex with and without illumination [5]. In addition, perturbation of hybrid formation by azobenzene has been used to control the length of DNA transcription in vitro. The azobenzene is incorporated into a 12mer blocking strand that hybridizes to a specific site on a template downstream from the primer. With the blocking strand present and the azobenzene in the trans form, DNA polymerase lacking strand displacement and also 5’ to 3’ exonuclease activity is physically blocked from reading the message, so a truncated message is transcribed. Upon UV illumination, the azobenzene isomerizes into the cis form, causing the blocking strand to dehybridize from the template and allowing the polymerase to transcribe a full-length copy [63].
Azobenzene has also been used to control the conformation of proteins [32, 36, 42]. Amino acids containing the molecule have been incorporated into proteins at specific sites during synthesis or through site directed mutagenesis, allowing phototriggering of structural changes in proteins or photo-deactivitation of protein activity. One example has used
CONTROL OF BIOMOLECULAR ACTIVITY BY NANOPARTICLE ANTENNAS |
465 |
azobenzene to control the activity of Ribonuclease S [32, 42]. RNase S mutants containing the azobenzene amino acid analog at key sites in the S-peptide portion of the protein were generated by chemical synthesis. By UV illumination, the catalysis rate (kcat) of the mutant containing the azobenzene analog can be reduced by approximately 1/2 as it switches the azobenzene from the trans to cis form. This is a working example by which light can control the activity of a protein.
Azobenzene has also been exploited as an optically powered molecular machine and being explored for use as a nanomechanical device [31]. In this case, multiple azobenzene units were incorporated into a polymer chain which was attached to an atomic force microscope cantilever. Under illumination, the azobenzene changes conformation, pulling the cantilever. The resulting average length change per molecule is 2.8nm. They then use this polymer to convert light into mechanical work in cycles, by repeatedly pulling the cantilever. The overall optical to mechanical efficiency, η, of 0.1 is obtained.
All of these examples show that knowledge of biological molecules has now reached a point where detailed, molecular-level knowledge of sophisticated and complex systems and mechanisms are attainable. This has been possible through recent advances in x-ray crystallographic techniques and various spectroscopies such as NMR, in combination with extensive mutational analysis and chemical design of inhibitors and binders. As a result, we are at a point where we can use this information and engineer Nature’s systems so that they can be manipulated to perform functions that either do not occur naturally or are much more efficient than their artificial counterpart.
15.2. NANOPARTICLES AS ANTENNAS FOR CONTROLLING BIOMOLECULES
In designing a way to control biomolecules, the technique for manipulation must be compatible in vitro and in vivo for real utility. Thus, it should be applicable in the complex and crowded three-dimensional environments in cells. In addition, this means of control should be direct, reversible, selective, and not specific to one type of biomolecule but universally applicable.
A new technique using nanoparticles as antennas for controlling the activity of biological molecules addresses many of these issues [26, 27]. It utilizes an adapation of induction heating, a technique which is employed industrially to heat metals in a rapid and non-contact manner [48, 67]. Basically, a metal part is placed in a coil to which a current is applied (Figure 15.4, left). This generates a magnetic field in the part. In order to oppose this magnetic field (Lenz’s Law), eddy currents are induced in the metal part. If the applied current is alternating, the magnetic field is changing direction, and the induced eddy currents oscillate in direction rapidly. This rapidly heats the metal part by joule heating.
In order to apply this to biological molecules for control, the metal species to be heated are nanoparticles. These nanoparticles are attached to a biological molecule in such a way that the normal functioning of the biomolecule is not affected (Figure 15.4, right). An external alternating magnetic field induced alternating eddy currents in the metal particle. The particle transfers the heat the biomolecule, inducing denaturation and thus shutting off the activity. Once the field is turned off, the biomolecule dissipates the heat into solution and refolds, resuming activity. Thus, the nanoparticle acts like a localized heat source which induces denaturation. Since the alternating magnetic field only heats the metal or magnetic