

Корпоративные информационные системы
..pdfтия решений. Этот вариант более предпочтителен для предприятий, производящих большое количество операций. Обработанные данные об операциях образуют файлы, которые для повышения надежности и быстроты доступа хранятся за пределами системы поддержки принятия решений.
2.Внутренние данные, например данные о движении персонала, инженерные данные и т.п., которые должны быть своевременно собраны, введены и поддержаны.
3.Данные из внешних источников. В числе необходимых внешних данных следует указать данные о конкурентах, национальной и мировой экономике. В отличие от внутренних данных внешние данные обычно приобретаются у специализирующихся на их сбореорганизаций.
4.Документы, включающих в себя записи, письма, контракты, приказы и т.п. Если содержание этих документов будет записано
впамяти и затем обработано по некоторым ключевым характеристикам (поставщикам, потребителям, датам, видам услуг и др.), то системаполучитновый мощныйисточник информации.
Присущий технологии СППР акцент на обработке неструктурированных и слабоструктурованых задач предопределяет некоторые специфические требования к этим элементам компьютерной системы. Прежде всего речь идет о необходимости выполнять значительный объем операций переструктурирования данных. Нужно предусмотреть возможность загрузки и следующей обработки данных из внешних источников; функционирование СУБД в среде СППР в отличие от обычной обработки информации в управленческих информационных системах требует более широкого набора функций. Это касается также и БД.
Вообще базу данных можно определить как совокупность элементов, организованных в соответствии с определенными правилами, которые предусматривают общие принципы описания, сохранения и манипулирования данными независимо от прикладных программ.
Связь конечных пользователей (прикладных программ) с базой данных происходит с помощью СУБД. Последняя представляет собой систему программного обеспечения, которая содержит средства обработки языками БД и обеспечивает создание БД и ее целостность, поддерживает ее в актуальном состоянии, дает возможность
41
манипулировать данными и обрабатывать обращение к БД, которые поступают от прикладных программ и (или) конечных пользователей при условиях применяемой технологии обработки информации. В состав БД, которые используются для изучения и обращение кданным, входит язык описания данных (ЯОД) и язык манипулированияданными(ЯМД).
Язык описания данных предназначенный для определения структуры БД. Описание данных заданной проблемной области может выполняться на нескольких уровнях абстрагирования, причем на каждом уровне используется свой ЯОД. Описание на любом уровне называется схемой. Чаще всего используется трехуровневая система: концептуальный, логический и физический уровни. На концептуальном уровне описываются взаимосвязи между системами данных, которые отвечают реально действующим зависимостям между факторами и параметрами проблемной среды. Структура данных на концептуальном уровне называется концептуальной схемой. На логическом уровне выбранные взаимосвязи отбиваются в структуре записей БД. На физическом уровне решаются вопрос организации размещения структуры записи на физических носителях информации.
Язык манипулирования данными обеспечивает доступ к данным и содержит средства для сохранения, поиска, обновления и стирания записей. Языки манипулирования данными, которые могут использоваться конечными пользователями в диалоговом режиме, частоназывают языками запросов.
СУБД должна обладать следующими возможностями:
♦составление комбинаций данных, получаемых из различных источников посредством использования процедур агрегирования и фильтрации;
♦быстрое прибавление или исключение того или иного источника данных;
♦построение логической структуры данных в терминах пользователя;
♦использование и манипулирование неофициальными данными для экспериментальной проверки рабочих альтернатив пользователя;
♦обеспечение полной логической независимости этой БД от других операционных БД, функционирующих в рамках фирмы.
42
БД и СУБД используются в любых компьютерных системах. Тем не менее сравнительно с обычными подходами к реализации БД для решения некоторых задач к функциям и инструментам БД
иСУБД в контексте системы поддержки принятия решений выдвигается ряд дополнительных испециализированных требований.
Для условий использования СППР существует необходимость доступа информации со значительно более широкого диапазона источников, чем это предусмотрено в обычных информационных системах. Информацию нужно получать от внешней среды
ивнутренних источников; потребность во внешних данных тем большая, чем выше уровень руководства, которое обслуживает выбранное СППР. Кроме того, обычные, ориентированные на бухгалтерский учет данные (характерные для систем обработки данных
иадминистративных информационных систем) необходимо дополнить нетрадиционными типами данных, в частности и такими, которыедосихпорвообщенебыли вфокусе компьютеризации.
Сюда входит текстовая информация, системы автоматизи-
рованного проектирования изделий и технологий, автоматизированного производства, а также другие источники и формации, необходимые для принятия решения.
Заслуживает также внимания особенность процесса поиска и увеличения данных в СППР в отличие от более общего процесса сбора данных из источников. Природа СППР требует, чтобы процесс поиска (и СУБД, которая руководит этим процессом) был достаточно гибким, лишь бы быстро обслуживать дополнения и изменения в соответствии с непредвиденными запросами, которые поступают от пользователей. Для процесса «Поиска и увеличения» данных в современных СППР широко применяются программные (интеллектуальные) агенты, а также ХД.
Схема формирования и использования ХД в СППР изображена на рис. 1.2. Данные берутся из разнообразных источников оперативных данных. После их перемещения отбираются данные для гарантирования того, что они имеют смысл, непрерывны и точны. Потом данные загружаются в реляционные таблицы, способные поддерживать разнообразные виды анализа и запросов, и оптимизируется для тех таблиц, которые, как можно ожидать, чаще всего будут использоваться. И, в конце концов, данные сохраняются для дальнейшего использованияв СППР.
43
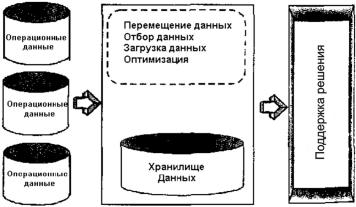
Рис. 1.2. Схема формирования и использования хранилища данных в системах поддержки принятия решений
В системах поддержки принятия решений предполагается средство, с помощью которого пользователь может налаживать базу данных согласно со своими личными требованиями. Учитывая это, существуют процедуры и команды гибкого переструктурирования схем и схемного подмножества СУБД. Заметим, что современные программные средства для управления данными и СУБД характеризуются относительной гибкостью и простотой использования в границах коллектива пользователей. Тем не менее упомянутые средства нельзя приспособить к конкретному пользователю или к решению конкретной задачи с желательной гибкостью и довольно маленькими затратами.
На рис. 1.3 изображена схема подсистемы данных СППР, где указаны перечисленные условия и механизмы адаптации концепций БД и СУБД к проблемам поддержки решений. Для реализации этой идеи в распоряжении разработчика или пользователя СППР есть ряд альтернативных моделей данных и инструментов, в частности классические иерархические, сетевые и реляционные модели, а также семантические модели данных. Реляционные модели данных положены в основу большинства современных СУБД.
44
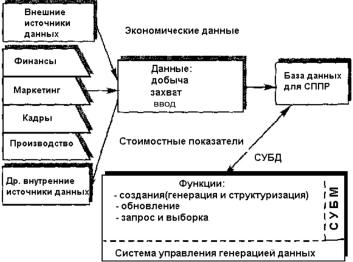
Рис. 1.3. Подсистема данных системы поддержки принятия решений
1.8.2.Оперативная аналитическая обработка данных
В основе концепции OLAP лежит принцип многомерного представления данных. Аббревиатура OLAP была впервые введена Коддом (E.F. Kodd), известным ученым в области реляционных БД, создателем широко распространенной реляционной модели. В своей работе (1993), инициированной компанией
Arbor Software (сегодня это Hyperion Solutions), «Providing OLAP to User Analysis: AN IT MAN-DATE» (обеспечение OLAP (оперативной аналитической обработки), для пользователейаналитиков, он определил:
1) основной недостаток реляционной модели как невоз-
можность «объединять, просматривать и анализировать данные с точки зрения множественности измерений, то есть самым понятным для корпоративных аналитиков способом». По Кодду, многомерное концептуальное представление (multidimensional conceptual view) представляет собой множественную перспективу, состоящую из нескольких независимых измерений, вдоль которых
45
могут быть проанализированы определенные совокупности данных. Одновременный анализ по нескольким измерениям определяется как многомерный анализ.
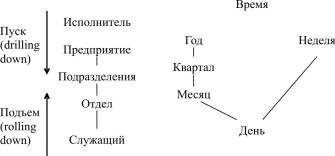
Каждое измерение включает направления консолидации данных, состоящие из серии последовательных уровней обобщения, где каждый вышестоящий уровень соответствует большей степени агрегации данных по соответствующему измерению. Так, измерение Исполнитель может определяться направлением консолидации, состоящим из уровней обобщения «предприятие – подразделение – отдел – служащий». Измерение Время может даже включать два направления консолидации – « год – квартал – месяц – день» и «неделя – день», поскольку счет времени по месяцам и по неделям несовместим. В этом случае становится возможным произвольный выбор желаемого уровня детализации информации по каждому из измерений. Операция спуска (drilling down) соответствует движению от высших ступеней консолидации к низшим; напротив, операция подъема (rolling up) означает движение от низших уровней к высшим (рис. 1.4);
Рис. 1.4. Измерения и направления консолидации данных
2) общие требования к системам OLAP, расширяющим функциональность реляционных СУБД и включающим многомерный анализ как одну из своих характеристик.
46

1.8.3. Требования к средствам оперативной аналитической обработки
Кодд сформулировал концепцию комплексного многомерного анализа данных, накопленных в хранилище, в виде 12 основных правил, которым должны удовлетворять OLAP-системы, как продукты, предоставляющие возможность выполнения оперативной аналитической обработки (табл. 1.1).
Набор этих требований, послуживших фактическим определением OLAP, следует рассматривать как рекомендательный, аконкретные продукты оценивать по степени приближения к идеальнополному соответствию всем требованиям.
Таблица 1 . 1
Правила оценки программных продуктов класса OLAP
1 |
Многомерное |
Концептуальное представление модели данных |
|
|
концептуальное |
впродукте OLAP должно быть многомерным по |
|
|
представление |
своей природе, то есть позволять аналитикам вы- |
|
|
данных |
полнять интуитивные операции «анализа |
вдоль |
|
(Multi-Dimensional |
ипоперек» («slice and dice»), вращения |
(rotate) |
|
Conceptual View) |
иразмещения(pivot) направленийконсолидации |
|
2 |
Прозрачность |
Пользователь не должен знать о том, какие кон- |
|
|
(Transparency) |
кретные средства используются для хранения |
|
|
|
и обработки данных, как данные организованы |
|
|
|
и откуда берутся |
|
3 |
Доступность |
Аналитик должен иметь возможность выполнять |
|
|
(Accessibility) |
анализ в рамках общей концептуальной схемы, но |
|
|
|
при этом данные могут оставаться под управлени- |
|
|
|
ем оставшихся от старого наследства СУБД, буду- |
|
|
|
чи при этом привязанными к общей аналитической |
|
|
|
модели. То есть инструментарий OLAP должен |
|
|
|
накладывать свою логическую схему на физиче- |
|
|
|
ские массивы данных, выполняя все преобразова- |
|
|
|
ния, требующиеся для обеспечения единого, согла- |
|
|
|
сованного и целостного взгляда пользователя на |
|
|
|
информацию |
|
4 |
Устойчивая |
С увеличением числа измерений и размеров базы |
|
|
производитель- |
данных аналитики не должны столкнуться с каким |
|
|
ность(Consistent |
бы то ни было уменьшением производительности. |
|
|
Reporting |
Устойчивая производительность необходима для |
|
|
Performance) |
поддержания простоты использования и свободы |
|
|
|
от усложнений, которые требуются для доведения |
|
|
|
OLAP доконечногопользователя |
|
47

|
|
Продолжение табл. 1 . 1 |
|
|
|
5 |
Клиент-серверная |
Большая часть данных, требующих оперативной |
|
архитектура |
аналитической обработки, хранится в мэйнфрей- |
|
(Client-Server |
мовых системах, а извлекается с персональных |
|
Architecture) |
компьютеров. Поэтому одним из требований явля- |
|
|
ется способность продуктов OLAP работать в сре- |
|
|
де клиент-сервер. Главной идеей здесь является то, |
|
|
что серверный компонент инструмента OLAP |
|
|
должен быть достаточно интеллектуальным и об- |
|
|
ладать способностью строить общую концептуаль- |
|
|
ную схему на основе обобщения и консолидации |
|
|
различных логических и физических схем корпо- |
|
|
ративных баз данных для обеспечения эффекта |
|
|
прозрачности |
6 |
Равноправие |
Все измерения данных должны быть равноправны. |
|
измерений |
Дополнительные характеристики могут быть пре- |
|
(Generic |
доставлены отдельным измерениям, но поскольку |
|
Dimensionality) |
все они симметричны, данная дополнительная |
|
|
функциональность может быть предоставлена лю- |
|
|
бому измерению. Базовая структура данных, фор- |
|
|
мулы и форматы отчетов не должны опираться на |
|
|
какое-тоодноизмерение |
7 |
Динамическая |
Инструмент OLAP должен обеспечивать опти- |
|
обработкаразре- |
мальную обработку разреженных матриц. Ско- |
|
женныхматриц |
ростьдоступадолжнасохранятьсявнезависимости |
|
(Dynamic Sparse |
от расположения ячеек данных и быть постоянной |
|
Matrix Handling) |
величиной для моделей, имеющих разное число |
|
|
измеренийиразличнуюразреженностьданных |
8 |
Поддержка |
Зачастую несколько аналитиков имеют необходи- |
|
многопользова- |
мость работать одновременно с одной аналитиче- |
|
тельскогорежима |
ской моделью или создавать различные модели на |
|
(Multi-User |
основе одних корпоративных данных. Инструмент |
|
Support) |
OLAP должен предоставлять им конкурентный |
|
|
доступ, обеспечивать целостность и защиту дан- |
|
|
ных |
9 |
Неограниченная |
Вычисления и манипуляция данными по любому |
|
поддержка кросс- |
числу измерений не должны запрещать или огра- |
|
мерныхопераций |
ничивать любые отношения между ячейками дан- |
|
(Unrestricted |
ных. Преобразования, требующие произвольного |
|
Cross-dimensional |
определения, должны задаваться на функциональ- |
|
Operations) |
нополномформульномязыке |
48

|
|
Окончание табл. 1 . 1 |
|
|
|
10 |
Интуитивное |
Переориентация направлений консолидации, дета- |
|
манипулирование |
лизация данных в колонках и строках, агрегация и |
|
данными |
другие манипуляции, свойственные структуре |
|
(Intuitive Data |
иерархии направлений консолидации, должны |
|
Manipulation) |
выполняться в максимально удобном, естествен- |
|
|
номикомфортномпользовательскоминтерфейсе |
11 |
Гибкиймеханизм |
Должны поддерживаться различные способы ви- |
|
генерацииотчетов |
зуализации данных, то есть отчеты должны пред- |
|
(Flexible |
ставлятьсявлюбойвозможнойориентации |
|
Reporting) |
|
12 |
Неограниченное |
Настоятельно рекомендуется допущение в каждом |
|
количествоизме- |
серьезном OLAP-инструменте как минимум пятна- |
|
ренийиуровней |
дцати, а лучше двадцати, измерений в аналитиче- |
|
агрегации(Unlim- |
скоймодели. Более того, каждое из этих измерений |
|
ited Dimensions |
должно допускать практически неограниченное |
|
and Aggregation |
количество определенных пользователем уровней |
|
Levels) |
агрегацииполюбому направлениюконсолидации |
В 1995 году к ним были добавлены еще шесть (которые известны в значительно меньшей степени). Все эти правила разделены нагруппы иназваны «характеристиками» (features, особенности).
1. Основные характеристики OLAP:
♦многомерность модели данных (оригинальное правило 1). Эта особенность – сердцевина OLAP;
♦прозрачность (оригинальное правило 2);
♦доступность данных, пакетное извлечение данных (оригинальноеправило3);
♦архитектура «клиент-сервер» (оригинальное правило5);
♦многопользовательская работа(оригинальное правило 8);
♦интуитивные механизмы манипулирования данными (оригинальное правило 10);
♦пакетное извлечение против интерпретации (новое). Это правило требует, чтобы продукт в равной степени эффективно обеспечивал доступ как к собственному хранилищу данных, так и к внешним данным. К большому сожалению, лишь небольшая часть OLAP-продуктов должным образом соответствует ей,
исреди них редкие делают это легко или автоматически. Сегодня это соответствует определению гибридных OLAP, которые в самом деле становятся наиболее популярной архитектурой;
49
♦ модели анализа OLAP (новое). OLAP-продукты должны поддерживать четыре модели анализа (категориальный, толковательный, умозрительный и стереотипный), которые можно определить как формирование параметрически настраиваемых отчетов, формирование разрезов и группировок с обращением, анализом
встиле «что, если» и моделями поиска целей соответственно.
2.Специальные характеристики:
♦обработка ненормализованных данных (новое) указывает на необходимость интеграции между OLAP-машиной и ненормализованными источниками данных. Не должны допускаться изменения данных, которые обычно расцениваются как расчетные ячейки в пределах БД OLAP;
♦хранение результатов отдельно от исходных данных (новое). В действительности это больше относится к реализации, чем к сущности продукта. OLAP-приложения, работающие в режиме чтения/записи, не должны воздействовать напрямую на обрабатываемые данные и данные, модифицированные в OLAP, должны сохраняться отдельно от данных трансакций. Например, метод обратной записи данных, использованный в Microsoft OLAP Services, является лучшей реализацией этого, поскольку позволяет сохранять данные, измененные в среде OLAP, отдельно от основных данных;
♦выделение пропущенных данных (новое). Пропущенные данные (Missing Data, Missing Value) – это особый элемент данных, который сигнализирует о том, что в данной ячейке данные отсутствуют и/или не определены. Это может быть как вследствие того, что рассматриваемая комбинация элементов не имеет смысла (например, снегоходы не могут продаваться в экваториальных странах), так и того, что данные не были введены. Термин «Пропущенные данные» по своему значению близок к термину «Пустое значение данных», однако это не то же самое, что «Нулевое значение».
Вдействительности это интересно только с точки зрения компактности хранения данных, некоторые OLAP-инструменты игнорируют это правило без больших потерь в функциональности;
♦обработка отсутствующих значений (новое). Все отсутствующие значения будут игнорироваться OLAP-анализатором без учета их источника. Эта особенность связана с предыдущей и является почти неизбежным следствием того, как OLAP-машина обрабатываетвседанные.
50