


изменении объема выборки n и доверительной вероятности (1- |
). |
Ошибка |
уменьшается при увеличении n и увеличивается при уменьшении |
или, |
что все |
равно, при увеличении степени доверия (1- ). |
|
|
Поскольку надежность оценки и ее точность - понятия конкурирующие (при увеличении одной из них уменьшается другая и наоборот), то обычно фиксируют надежность, а точность увеличивают, увеличивая объем выборки. На этом основано и определение объема выборки, обеспечивающего заданную точность оценки при фиксированной ее надежности. Итак, пусть точность оценки равна Е. Тогда при
фиксированном |
можно найти объем выборки n, обеспечивающий эту точность из |
соотношения: |
|
|
|
E |
t |
|
|
|
S |
, |
|||
|
|
/2 |
|
|
|
|
|
||||
|
|
|
|
|
|
|
|||||
|
|
n |
1 |
||||||||
|
|
|
|
|
|
|
|
|
|||
откуда |
n |
|
t2 |
/2 |
S2 |
|
1 . |
|
|
||
|
|
E2 |
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
Округлив до целого, получим искомый объем выборки.
Аналогично объем выборки, обеспечивающий заданную точность при определении интервальной оценки доли, определяется из соотношения:
|
z2 |
\2 p (1 |
p) |
|
n |
|
|
|
. |
|
E2 |
|
||
|
|
|
|
|
Рассмотрим пример. Пусть в ранее рассмотренной задаче о зарплате руководство фирмы желает узнать, каков должен быть объем выборки для обеспечения определения зарплаты с точностью 25 руб. Чтобы воспользоваться выведенной формулой для
определения объема |
выборки, необходимо знать табличное значение величины t |
/ 2 . |
При фиксированном |
нужно еще знать число степеней свободы, равное n-1, а n |
надо |
определять. Что бы обойти эту неприятную ситуацию, воспользуемся тем, что объем выборки был уже достаточно большим, равный 37 (см. задачу выше) и в этом случае можно воспользоватсья нормальным распределением для определения этой величины.
Известно, что при =0,05 z / 2 =1,96. Тогда n = (1,962·1052)/252 +1=67,76. Итак,
необходимо включить в выборку 68 рабочих фирмы.
Контрольные вопросы
1.Какая оценка называется «хорошей»?
2.В чем отличие стандартного отклонения от стандартной ошибки выборки?
3.В чем отличие точечной оценки от интервальной?
4.Когда при определении доверительного интервала для средней арифметической рекомендуется использовать статистику Стьюдента?
5.Сформулируйте условия аппроксимации биномиального распределения нормальным при проверке гипотезы о доли генеральной совокупности.
6.В чем заключаются различия при вычислении доверительных интервалов для доли генеральной совокупности и для генеральной средней?
7.Надежность и точность оценки – понятия конкурирующие. Почему?
8.Как обеспечить заданную точность оценки?
ГЛАВА 3. Проверка статистических гипотез
Проверка статистических гипотез также относится к разделу статистического оценивания, но «подходит» к нему с несколько иных позиций. Если при построении

оценок сначала из генеральной совокупности реализуется случайная выборка и на ее основе (по результатам выборки) вырабатываются заключения относительно параметров генеральной совокупности, то при проверке статистических гипотез рассуждения ведутся как бы от обратного: сначала выдвигается гипотеза о значении параметра генеральной совокупности, и только после этого реализуется выборка, по результатам которой отклоняют или не
отклоняют выдвинутую гипотезу. Если по результатам выборки в предположении верности выдвинутой гипотезы происходит маловероятное событие или, наоборот, не происходит почти достоверное, то это говорит в пользу отклонения выдвинутой гипотезы.
Пусть, например, проверяется гипотеза о среднем значении генеральной совокупности. Пусть принятое (гипотетическое) значение равно н. После реализации
выборки рассчитаем выборочное значение средней ( х ). Ясно, что при увеличении
|
|
|
|
разности x μн |
вероятность того, что принятое значение правильно, |
||
уменьшается. |
|
||
Связанную с генеральной совокупностью гипотезу невозможно проверить непосредственно, поэтому проверяют гипотезу об отсутствии разности (о нулевой разности). Такую гипотезу называют нулевой и обозначают Н0. При проверке нулевой гипотезы вопрос ставится так: значимо ли отличие разности от нуля? При решении этого вопроса такую разность соотносят со стандартной ошибкой соответствующей статистики и проверяют, попало ли вычисленное значение статистики в область принятия гипотезы или нет и в зависимости от результата проверки делают соответствующий вывод.
Известно, что, принимая или отклоняя нулевую гипотезу, можно допустить ошибки двух видов. Ошибка первого рода состоит в том, что нулевая гипотеза отвергается, в то время как в действительности она верна. Результатом такой ошибки, например, может быть забракована годная продукция. Ошибка второго рода состоит в принятии ошибочной гипотезы (отправить потребителю бракованную продукцию). Ясно, что последствия таких ошибок разные: первый случай приводит к более осторожным, перестраховочным решениям, второй – к неоправданно рискованным действиям. Исключить обе эти ошибки одновременно нельзя, т.к. они конкурирующие: уменьшая вероятность одной из них, увеличиваем вероятность другой, поэтому, как правило, фиксируют вероятность ошибки первого рода и стремятся минимизировать вероятность ошибки второго рода (обычно путем увеличения объема выборки).
При принятии или непринятии гипотезы обычно пользуются правилом 5 %-го уровня значимости. Это правило состоит в следующем: если разность между
статистикой выборки и принятым параметром генеральной совокупности столь велика, что при правильном в действительности принятом значении параметра вероятность случайного появления такой или большей разности составляет 0,05 или меньше, то нулевая гипотеза отвергается и найденная разность рассматривается как значимая.
Следует иметь в виду, что на практике используется и 1 %-й и 10 %-й уровень значимости в зависимости от важности принимаемого решения.
3.1. Проверка гипотезы о значении средней и доли генеральной совокупности
Применение рассмотренного правила для проверки гипотезы о среднем значении генеральной совокупности приводит к следующему алгоритму:
принимается, что среднее значение совокупности равно н ;
по результатам выборки рассчитывается значение t-статистики:
|
t |
x |
|
μн S |
|
|
; |
|
|
|
|
|
|
|
x |
|
|
|
|
||
|
|
|
|
|
|
|
|
|
||
при фиксированном уровне значимости |
и числе степеней свободы |
= n–1 |
||||||||
значение t сравнивается с t /2 (найденное по таблице t-распределения); |
|
|||||||||
если |
t находится внутри интервала |
|
[-t |
/2 ; t /2], |
т.е. -t /2 |
t t /2 |
, то нулевая |
|||
гипотеза |
Н0 : = н не отклоняется, если же t < -t |
/2 |
или t > t |
/2 , то Н0 отклоняется. |
||||||
Рис. 11.Критическая область и область принятия гипотезы для t-статистики с = 10 и = 0,05
Графически это представлено на рис. 11. Область за пределами вертикальных штриховых линий (для них t= 2,23) – это критическая область. Вероятность попасть в эту область равна 0,05 (по 0,025 справа и слева от границы области принятия гипотезы). И если вычисленное значение t-статистики попало в эту область, независимо от того, справа или слева от критических пределов, то это означает, что произошло очень редкое событие, что говорит не в пользу гипотезы Н0.
До сих пор мы рассматривали так называемую двухстороннюю проверку гипотезы, когда нулевая и альтернативная гипотезы для средней арифметической, например, формулировались так: Н0: 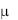 = н и Н1:
= н и Н1: 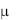
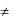 н. Причем в последнем случае нас не интересовало: фактическое значение больше или меньше принятого. Однако зачастую решение именно этого вопроса является предметом исследования. В этом случае
н. Причем в последнем случае нас не интересовало: фактическое значение больше или меньше принятого. Однако зачастую решение именно этого вопроса является предметом исследования. В этом случае
говорят |
об |
односторонней |
проверке |
гипотезы: правосторонней, |
если |
Н0 |
|
формулируется так: |
н , а |
Н1: > н и |
левосторонней, если Н0 : |
н |
и |
||
Н1 : < |
н . |
|
|
|
|
|
|
Если правосторонняя проверка, например, проводится на уровне значимости 0,05,
то критическая область будет справа от t0,05 , как это показано на рис. 12, т.е. Н0 отклоняется, если t > t0,05=1,81.
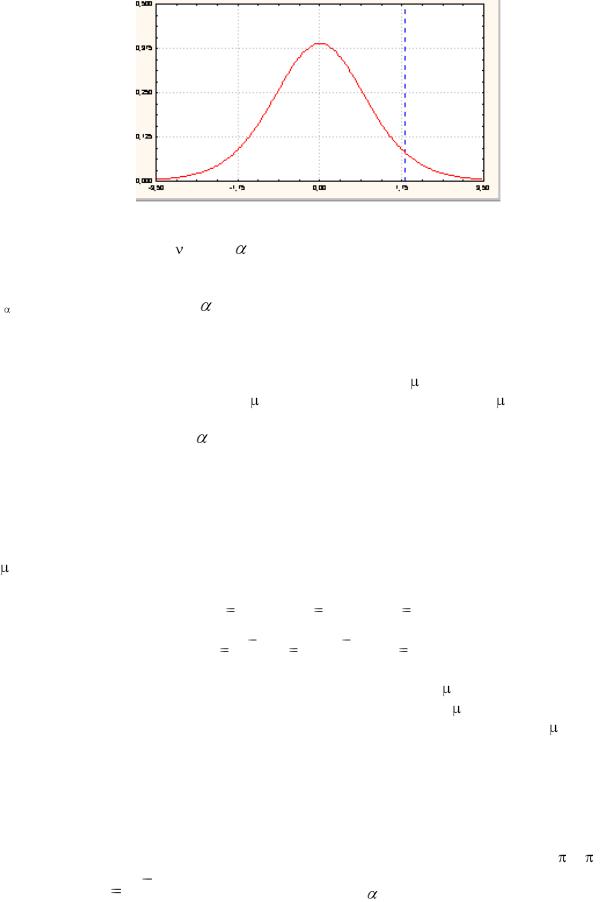
Рис. 12. Критическая область и область принятия гипотезы для t-статистики с = 10 и = 0,05 в случае правосторонней проверки
Обратите внимание, что вся критическая область в этом случае находится справа от t , а не делится пополам по /2 справа и слева от области принятия гипотезы, как это делалось в случае двухсторонней проверки гипотезы.
Аналогично для левосторонней проверки.
Следует отметить, что нулевая гипотеза при односторонней проверке гипотезы в обоих случаях может быть сформулирована как Н0 : 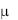 = н , но альтернативные: для правосторонней проверки Н1 :
= н , но альтернативные: для правосторонней проверки Н1 : 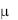 > н и для левосторонней Н1 :
> н и для левосторонней Н1 : 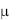 < н . На правило принятия решения это не повлияет. Отметим также, что из приведенных выше рассуждений следует, что в % случаях t-статистика попадает в критическую область, когда гипотеза верна, т.е. при проверке гипотезы уровень значимости совпадает с вероятностью ошибки первого рода.
< н . На правило принятия решения это не повлияет. Отметим также, что из приведенных выше рассуждений следует, что в % случаях t-статистика попадает в критическую область, когда гипотеза верна, т.е. при проверке гипотезы уровень значимости совпадает с вероятностью ошибки первого рода.
Как уже отмечалось, построение доверительного интервала и проверка гипотез - схожие процедуры. Покажем это на примерах. Вернемся к примеру о вычислении доверительного интервала для средней заработной платы рабочих фирмы. Проверим в условиях этого примера гипотезу о том, что средний уровень зарплаты рабочих фирмы
н = 1 050 руб. на 5 %-м уровне значимости. Имеем:
|
x |
|
|
1100; S |
|
|
|
17,1 ; |
t0,025 2,03; |
|
||||||
|
x |
|
||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
t |
x |
|
|
μн |
1100 1 |
050 |
2,92 . |
||||||||
|
|
|
|
S |
|
|
|
|
|
|
17,1 |
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
x |
|
|
|
|
|
|
||||
Получили: t = 2,92 > t0,025 |
= |
2,03. |
Итак, гипотеза Н0 : |
н = 1 050 отклоняется. |
||||||||||||
Обратите внимание, что в случае отклонения гипотезы величина |
н = 1 050 не входит в |
|||||||||||||||
доверительный интервал для среднего уровня зарплаты. Если же за величину н взять число из доверительного интервала, то гипотеза не отклонится (проверьте самостоятельно). При односторонней проверке гипотезы вопрос можно поставить так: проверить при 5 %-м уровне значимости, что средний уровень зарплаты не меньше 1 050 руб. против альтернативной – меньше 1 050 руб. Расчетное значение t-статистики и
в этом случае равно 2,52, но сравнивать его уже надо с (-t0,05)= - 1,69. Т.к. 2,52 > - 1,69, гипотеза не отклоняется.
При проверке гипотезы относительно доли генеральной совокупности (Н0 : = н)
вычисляют Z |
p |
πн |
и сравнивают с Z /2, определяемое по таблице |
|
Sp |
||
|
|
|
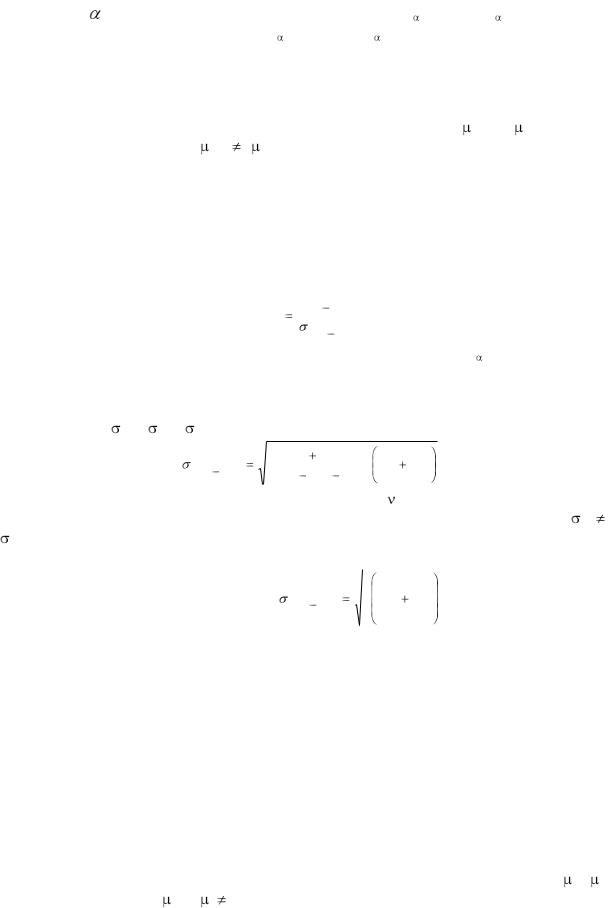
стандартизованного нормального распределения при фиксированном уровне значимости . Как и в случае с t-статистикой, если -Z /2 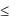 Z
Z 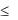 Z /2 , то нулевая гипотеза не отклоняется, если же Z < -Z /2 или Z > Z /2 , то Н0 отклоняется.
Z /2 , то нулевая гипотеза не отклоняется, если же Z < -Z /2 или Z > Z /2 , то Н0 отклоняется.
3.2. Сравнение средних и долей
Рассмотрим сначала процедуру сравнения средних двух совокупностей. При
проверке гипотезы относительно |
равенства двух средних |
1 = |
2 |
против |
|
альтернативной гипотезы |
1 |
2 необходимо различать, |
имеем ли |
мы |
дело с |
зависимыми или независимыми выборками, а в последнем случае проверять, равны или не равны дисперсии этих совокупностей. В зависимости от ответов на эти вопросы различаются и методы проверки гипотез.
Пусть осуществлены две случайные выборки из каждой совокупности
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
соответственно объема n1 и n2 |
с выборочными средними x1 и x2 и с выборочными |
||||||||||||||
стандартными отклонениями S1 |
и S2. Правило принятия решения о равенстве средних |
||||||||||||||
в этом случае аналогично ранее рассмотренному. Из соотношения |
|||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
t |
|
x1 |
x2 |
|||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
x1 |
|
x2 |
||||||||||
вычисляется t-статистика и сравнивается с критическим значением t /2.
Оценка стандартной ошибки разности средних и число степеней свободы для t- статистики здесь вычисляются по-разному, в зависимости от условий, в которых решается задача. Так, например, при условии равенства дисперсий генеральных совокупностей ( 12 = 22 = )
|
|
|
|
|
(n S 2 |
|
|
n S |
|
2 ) |
|
|
1 |
1 |
|
|
|
|
|||||||||
|
|
|
|
1 1 |
|
|
2 |
2 |
|
|
|
|
|
|
|
|
|
|
|
|
, |
|
|||||
|
x1 x2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
|
|
n |
n |
2 |
|
2 |
|
|
|
|
n |
|
|
n |
2 |
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||
|
|
|
|
1 |
|
|
|
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
||||||
а число степеней свободы определяется из выражения |
|
|
= n1 + n2 – 2. |
|
|||||||||||||||||||||||
Вычисления упрощаются при n1 = n2, но становятся более сложными при |
2 |
||||||||||||||||||||||||||
1 |
|||||||||||||||||||||||||||
22. В этом случае оценка стандартной ошибки разности средних определяется |
из |
||||||||||||||||||||||||||
выражения: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
S1 |
|
|
|
S |
2 |
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2 |
|
|
|
|
|
2 |
|
, |
|
|
|
|
|
|
|
|
x1 |
|
x2 |
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
n |
|
|
|
n |
2 |
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
|
|
а число степеней свободы определяется сложно, с использованием значений n1, n2, а также S1 и S2, и при этом t-статистика не подчиняется ни нормальному распределению, ни распределению Стьюдента. При больших объемах выборки это распределение может быть аппроксимировано нормальным, что и осуществлено в большинстве статистических ППП.
Отдельно следует рассмотреть вопрос о попарном сравнении двух выборок. Здесь речь идет о сравнении средних в случае двух зависимых выборок. Этот случай встречается, когда появляется необходимость сравнить результаты эксперимента до и после действия каких-либо условий в одних и тех же наблюдениях. Например, до и после проведения рекламной кампании или до и
после изменения условий выпуска продукции и т.д. В этом случае предполагается, что в результате как бы одного наблюдения исследователь получает два значения для одной переменной, и тогда можно рассматривать их разность и в дальнейшем проверять гипотезу о равенстве нулю таких разностей, т.е. проверяется гипотеза: 1 - 2 =0 против гипотезы: 1 - 2 0. При кажущемся сходстве этого рассмотрения с

предыдущим, они существенно различаются, т.к. здесь число степеней свободы уменьшается вдвое; оно определяется объемом одной выборки.
О проверке гипотезы равенства дисперсий речь пойдет ниже.
Гипотеза о равенстве долей двух совокупностей (Н0: 1 = 2) проверяется, как и в случае проверки гипотезы о значении доли генеральной совокупности, на основе z- статистики. В этом случае z - величина рассчитывается из соотношения
Z 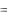 p1 p2 p1 p2
p1 p2 p1 p2
и сравнивается с табличным значением Z /2. При этом
|
2 |
2 |
|
p1(1 p1) |
|
p2(1 p2) |
|
|
p1 p2 |
s p1 |
s p2 |
|
|
|
|
|
. |
|
n |
|
n |
2 |
||||
|
|
|
1 |
|
|
|
||
Последняя формула верна, если две большие выборки независимы и взяты из двух генеральных совокупностей. Здесь как и ранее используется аппроксимация биноминального распределения нормальным.
Рассмотрим пример. Проверим гипотезу о разности средних зарплат рабочих двух
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
фирм, рассмотренных ранее. |
|
Напомним, что x1 1 100, |
x2 |
1000, n1 = 37, n2 = |
|||||||||||||||||||||||||
30, S |
|
|
17,1 и S |
|
|
|
|
|
|
|
|
20. Кроме того, было вычислено, что S |
|
|
|
|
|
26,3. |
|||||||||||
x |
|
x |
|
|
|
|
|
|
|
x |
|
x |
|
||||||||||||||||
1 |
|
|
|
2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
|
2 |
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
Имеем |
t |
|
|
x1 |
|
|
x |
2 |
|
|
100 |
3,8 . |
|
|
|
|
|
|
|
|
|||||||||
|
|
|
S |
|
|
|
|
|
|
|
26,3 |
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
x |
1 |
|
x |
2 |
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
При |
= 0,05 и = n1 |
+ n2 – 2 = 37 + 30 –2 = 65 |
t /2 = 2,0, т.к. t > t /2, то |
||||||||||||||||||||||||||
гипотеза о равенстве нулю разности средних отклоняется, т.е. средняя зарплата у рабочих этих фирм различается значимо.
Известно, что если доверительный интервал для разности средних не содержит нуль, то средние различаются значимо, в противном случае – незначимо. В нашем примере доверительный интервал для разности этих средних, найденный ранее, равен [47,4 ; 152,6]; он не содержит нуль, что подтверждает сделанный ранее вывод.
Далее (см пример выше), при определении доверительного интервала для разности долей жителей двух районов, предпочитающих товары данной фирмы, мы получили интервал (-0,054; 0,154). Если проверить гипотезу о разности долей в этом случае, то получим, что доли не различаются значимо (доверительный интервал содержит нуль). Проверьте самостоятельно.
А теперь продемонстрируем реализацию рассмотренных процедур на основе ППП
Statgraphics.
Как и в любом другом статистическом ППП при проверке гипотез на основе компьютерных расчетов наравне с вычисленным значением статистики определяется так называемая р-величина (p-value). Не останавливаясь подробно на ее вычислении, отметим, что это есть вероятность попадания вычисленного значения статистики в область принятия нулевой гипотезы (по-другому ее называют расчетным значением уровня значимости). Если эта вероятность мала (меньше фиксированного уровня значимости ), то нулевая гипотеза отклоняется, в противном случае не отклоняется. Такой анализ удобен, т.к. в этом случае отпадает необходимость сравнивать вычисленное значение статистики с табличным.
Пусть имеются данные о цене на однородную продукцию двух фирм за 16 периодов времени. Проверим гипотезу о равенстве цен на продукцию этих фирм за рассмотренный период времени. Проверим ее дважды: в предположении независимости выборок и при парном сравнении, чтобы увидеть различия этих двух методов.
Приведем здесь только результаты расчетов, не приводя исходную информацию.
Рис. 13. Выбор процедуры сравнения двух выборок в ППП Satgraphics
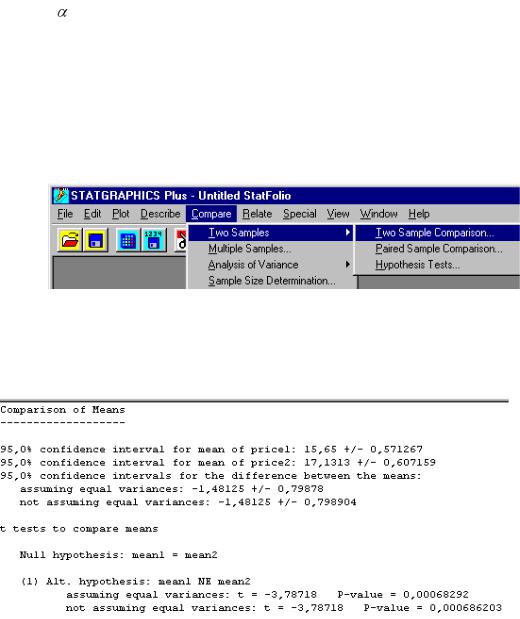
Выбрав процедуру сравнения двух выборок, как это указано на рис. 13, и проведя расчеты, получим следующий отчет о сравнении средних:
Рис. 14. Отчет процедуры сравнения средних в ППП Statgraphics
В отчете сначала указаны три 95 %-х доверительных интервала: для средних цен продукции 1-й и 2-й фирм и их разности, причем последнее – для случая равных и не равных дисперсий. Уже этой информации достаточно для принятия решения.

Так: выборочные средние для цен продукции 1-й и 2-й фирм равны: x1 1 5,65, x2 17,13, а доверительные интервалы, соответственно, равны:
15,65 0,57 и 17,13 0,61. Ясно, что они не пересекаются, следовательно, средние различаются значимо, т.е. различаются значимо цены на продукцию этих фирм. Тот же вывод можно сделать, анализируя доверительный интервал для разности средних. Как следует из отчета, доверительный интервал для разности средних равен: -1,48 0,8 (с округлением). Ясно, что он не содержит нуль, следовательно, средние различаются существенно. Еще раз этот же вывод можно сделать, проанализировав t-критерий для сравнения средних, отраженный во второй половине отчета. Там сформулирована нулевая гипотеза (H0: 1 =
2) против альтернативной гипотезы (Ha: 1 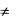 2), а также приведено расчетное значение t-статистики, равное –3,787. Р-величина для нее равна 0,0007, меньше 0,05, следовательно, средние различаются существенно.
2), а также приведено расчетное значение t-статистики, равное –3,787. Р-величина для нее равна 0,0007, меньше 0,05, следовательно, средние различаются существенно.
Отчет о парном сравнении выборок по этой же самой информации имеет вид (см. следующую процедуру, после выделенной на рис. 13):
Рис. 15. Отчет о парном сравнении двух выборок в ППП Satgraphics
Здесь сначала приведен доверительный интервал для разности средних (сравните с рис. 14), а затем проверяется гипотеза о равенстве нулю этой разности. Обратите внимание на то, что t-статистика здесь в два раза больше предыдущей и р-величина существенно меньше. Это явилось результатом того, что здесь рассматривается как бы одна выборка, и число степеней свободы уменьшилось вдвое. Выводы же здесь получились аналогичными предыдущим, только на более высоком уровне значимости. Последняя запись отчета гласит: ”отклонить нулевую гипотезу для = 0,05”. В завершение этого анализа отметим, что при анализе независимых выборок рассматривались два варианта: равные и не равные дисперсии совокупностей, а в парном сравнении этот вопрос не ставится, т. к. рассматривается выборка из одной совокупности.
3.3. Сравнение дисперсий двух совокупностей

Процедура сравнения дисперсий может включать в себя решение следующих трех задач: определение доверительного интервала для дисперсии генеральной совокупности, сравнение генеральной дисперсии со стандартом или проверка гипотезы о значении дисперсии генеральной совокупности и, наконец, непосредственно сравнение дисперсий двух генеральных совокупностей
Остановимся кратко на каждой из этих задач.
Определение доверительного интервала для дисперсии генеральной совокупности основывается на положении о том что если осуществлены простые случайные выборки из нормально распределенной генеральной совокупности, то выборочное распределение величин (n-1)S2/ 2 подчинено закону распределения 2 (хи-квадрат) с n-1 степенями
свободы. Поскольку распределения |
2 не симметрично, то интервал |
|||||||||||
содержащий 95 % величиы |
2 |
запишется так: |
2 |
|
2 |
2 |
||||||
|
|
0,025 |
|
0,975. |
||||||||
Заменив |
2 |
|
2 |
2 |
|
|
|
2 |
|
2 |
2 |
2 |
|
на (n-1)S / |
, получим: |
|
0,025 |
(n-1)S / |
|
0,975 |
|||||
или |
|
|
|
2 |
2 |
|
2 |
|
2 |
2 |
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
(n-1)S / |
0,975 |
|
(n-1)S / |
0,025. |
|
|
|||
Получили 95 %-й доверительный интервал для дисперсии |
||||||||||||
генеральной совокупности. |
|
|
|
|
|
|
|
|
||||
Значения |
2 |
2 |
|
|
|
|
|
|
|
2 |
||
0,025 и |
0,975 |
определяются из таблицы значений - |
||||||||||
распределения при известном числе степеней свободы.
Проверка гипотезы о значении дисперсии генеральной совокупности основывается также на положении о том, что выборочное распределение
величин (n-1)S2/ 2 подчинено закону распределения 2 (хи-квадрат) с n-1 |
|
степенями свободы. Пусть необходимо проверить гипотезу о том, |
что |
дисперсия генеральной совокупности равна H. Тогда расчетное |
|
значение статистики 2 определится из соотношения: 2 =
(n-1)S2/ H2 . А дальше остается проверить, попало или нет вычисленное
значение статистики 2 в область принятия гипотезы и в зависимости от
этого принять решение.
А теперь рассмотрим алгоритм проверки гипотезы о равенстве дисперсий двух генеральных совокупностей, тем более, что мы уже встретились с такой задачей при вычислении стандартной ошибки разности двух средних. Кроме того, задачи сравнения дисперсий часто возникают в практической деятельности, например, при сравнении качества работы двух производственных процессов: тот из них работает более устойчиво, для которого дисперсия значимо меньше и т. д.
Известно, что если взять две независимые случайные выборки размерности n1 и n2 из нормально распределенных совокупностей с равными дисперсиями, то отношение выборочных дисперсий S12 и S22 имеет распределение Фишера или F – распределение
с n1-1 числом степеней свободы числителя |
и n2-1 числом степеней свободы |
||
знаменателя. |
|
|
|
Как известно, распределение Фишера, как и распределение |
2, не симметрично, и |
||
если гипотеза о равенстве дисперсий (Н0: |
12 = |
22) проверяется на уровне значимости |
|
, то область принятия гипотезы, вообще-то, определяется неравенством : F1- /2 F |
|||
F /2. Гипотеза не принимается, если F < F1- /2 |
или F > F /2. Для удобства работы |
||
статистики договорились рассчитывать |
критерий Фишера как |
отношение большей |
|