

Провести анализ этих данных, используя один из статистических ППП, на основе описательной статистики.
1. Рассчитать для всех трех переменных среднюю арифметическую, моду, медиану, стандартное отклонение, верхний и нижний квартили, асимметрию, эксцесс и коэффициент вариации.
2.На основе рассчитанных статистик провести сравнительный анализ средних оценок удовлетворенности и их стандартных отклонений по каждой из приведенных позиций.
3.Прокомментировать значения коэффициентов вариации.
4.Прокомментировать в сравнительном анализе значения квартилей.
5.Прокомментировать в сравнительном анализе значения асимметрий.
6.Прокомментировать в сравнительном анализе значения эксцессов.
7.Прокомментировать различия в средних арифметических и медианах внутри каждой из позиции и соотнести это со значениями асимметрии.
8.Построить для каждой переменной полигон, гистограмму (частот и относительных частот, накопленных частот), а также ящичковые диаграммы. Прокомментировать их вид с точки зрения анализа ответов..
9.Провести сравнительный анализ информации для каждого предприятия.
|
Пример 2. Имеются данные о средних сроках (в днях) оборота наличных денежных |
||||||||||||||||||
средств для 39 фирм: |
13,9 |
11,1 |
9,5 |
19,6 |
8,5 |
|
29,8 |
6,2 5,9 40,9 4 10,3 |
31,8 |
||||||||||
65,2 |
38,2 |
10,8 |
|
13,7 |
18,8 |
8,1 |
16,7 |
26,1 |
28,2 |
11,1 |
17,2 |
10,3 |
38,8 |
54,11 |
12,2 |
||||
18 |
37 |
14,4 |
19,7 |
10,2 |
68,1 |
6,7 |
9,5 |
10,3 |
3,8 |
|
11,65 |
16,8. |
|
|
|
|
|||
|
Проанализировать эту информацию, рассчитав для нее описательные статистики и |
||||||||||||||||||
построив гистограмму и ''ящик-с-усами''. |
|
|
|
|
|
|
|
|
|||||||||||
|
Известно, |
|
что |
распределения с |
более |
длинным правым |
хвостом |
путем |
|||||||||||
логарифмирования можно преобразовать в приближенно симметричные. Проверить это на данном примере.
Пример 3. Любой статистический ППП поставляется с набором учебных файлов. Проанализируйте, например, в ППП Statgraphics Plus в файле Cardata с помощью описательной статистики переменные “price” и “ mpg”.
ГЛАВА 2. Оценка параметров генеральной совокупности
Исследователь имеет дело, как правило, с выборкой и по выборочным данным пытается сделать выводы о свойствах генеральной совокупности. Характеристики генеральной совокупности будем называть параметрами. Параметры, как правило, нам неизвестны, и мы можем лишь приближенно оценивать их на основе выборочных данных. Тем самым мы получаем оценки параметров генеральной совокупности. Отметим, что оценка будет давать верное представление о параметре, если она получена из генеральной совокупности на основе случайной выборки. Выборка называется случайной, если для каждого элемента совокупности вероятность попасть в эту выборку известна и одинакова. Только случайная выборка может представлять генеральную совокупность, и только на ее основе можно получить “хорошие” оценки. Как известно, “хорошая” оценка должна удовлетворять следующим четырем критериям: состоятельности, несмещенности, эффективности и достаточности. Напомним два из них.
Оценка называется эффективной, если она обладает наименьшей дисперсией, и несмещенной, если ее математическое ожидание совпадает со значением параметра.
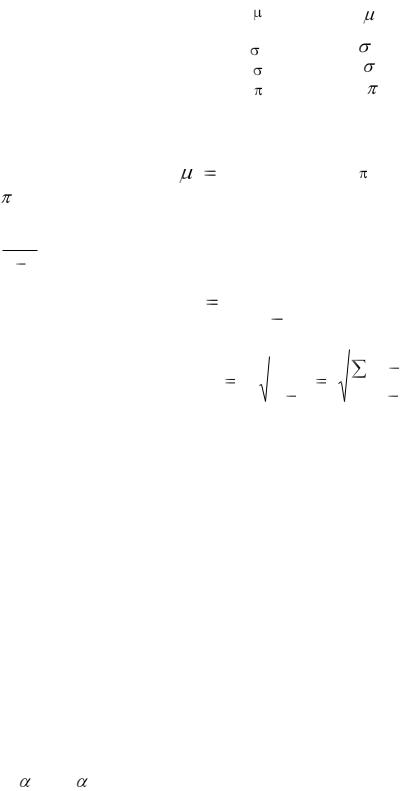
Введем обозначения, которым будем придерживаться в дальнейшем:
Характеристика |
Параметр |
Оценка |
Выборочное |
||||
|
|
|
|
значение |
|||
Средняя |
|
ˆ |
|
|
|
|
|
|
|
х |
|||||
Дисперсия |
2 |
ˆ |
2 |
|
|
2 |
|
|
S |
||||||
|
|
||||||
Станд. отклонение |
|
ˆ |
|
|
|||
|
|
S |
|||||
Доля |
|
|
ˆ |
|
|||
|
|
|
р |
||||
Оценивание некоторого отдельного параметра дает точечную оценку. Известно, что «хорошей» оценкой средней арифметической генеральной совокупности является
выборочная средняя, т. е. ˆ |
|
|
х ; аналогично для : |
||
ˆ = р. Но выборочная дисперсия дает смещенную (заниженную) оценку генеральной дисперсии. Чтобы убрать эффект смещенности, вводят поправочный коэффициент
n
n 1 , тогда несмещенной оценкой генеральной дисперсии является исправленная
выборочная дисперсия: σˆ2 |
S2 |
n |
|
и, |
соответственно, несмещенной оценкой |
|||||||||||
|
|
|
|
|||||||||||||
|
|
|
|
|||||||||||||
|
|
n |
1 |
|
|
|
|
|
|
|
|
|
|
|||
стандартного отклонения является |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
σˆ |
|
|
|
|
n |
|
|
(x |
x)2 |
|||||||
S |
|
|
|
|
|
|
|
|
|
|
|
. |
||||
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
n |
1 |
|
|
|
n |
1 |
|
|
|
|||
Следует отметить, что в литературе можно встретить обозначение S и для исправленного выборочного стандартного отклонения.
До сих пор речь шла о точечных оценках параметров генеральной совокупности. Как известно, оценка – это приближенное значение параметра генеральной совокупности. О мере точности и надежности точечной оценки судить сложно, поскольку значение оценки вычисляется на основе случайной выборки и является случайным. Единственное, что можно здесь утверждать, так это то, что в соответствии с критерием состоятельности уверенность в точности точечной оценки увеличивается по мере увеличения объема выборки.
Когда речь идет о точечной оценке, нелегко продемонстрировать влияние объема выборки на точность оценки, однако это влияние очевидно при вычислении интервальной оценки. Заметим, что, переходя от точечных оценок к интервальным, мы тем самым переходим от описательной статистики к аналитической статистике или статистике вывода.
Интервальной оценкой параметра генеральной совокупности называют интервал, который с заданной вероятностью накрывает истинное значение параметра. Интервальную оценку называют доверительным интервалом, а связанную с ним и указанную выше вероятность – доверительной вероятностью. Интервальная оценка обладает такими свойствами, как точность и надежность. Точность интервальной оценки определяется величиной интервала, а надежность – степенью доверия, равной (1- ), где - вероятность того, что доверительный интервал не содержит параметр.
Интервальное оценивание связано с понятием стандартной ошибки оцениваемого параметра, которая, в свою очередь, связана с выборочным распределением. Если, например, осуществить несколько независимых случайных выборок из одной и той же генеральной совокупности и для каждой из них рассчитать выборочную среднюю, то

полученные выборочные средние можно представить как элементы отдельной выборки и их распределение называется выборочным распределением.
Известно, что если исходная совокупность имеет параметры |
и , то выборочное |
|
распределение выборочных средних при достаточно больших объемах выборки (n |
30) |
|
может быть аппроксимировано нормальным распределением, |
независимо от |
вида |
исходного распределения, с параметрами и x = / 
 n . x называется стандартной ошибкой выборки или просто стандартной ошибкой и характеризует меру вариации выборочных средних вокруг генеральной средней. Как видно из определения, стандартная ошибка уменьшается при увеличении объема выборки.
n . x называется стандартной ошибкой выборки или просто стандартной ошибкой и характеризует меру вариации выборочных средних вокруг генеральной средней. Как видно из определения, стандартная ошибка уменьшается при увеличении объема выборки.
Оценка стандартной ошибки рассчитывается по формуле
S |
|
|
|
S |
|
|
, |
(2.1) |
|
|
|
|
|
|
|||
x |
|
|
|
|
|
|||
|
|
n |
1 |
|||||
|
|
|
|
|
|
|||
если генеральная совокупность бесконечна, и по формуле
S |
|
|
|
N |
n |
|
|
|
S |
, |
(2.2) |
||
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|||
x |
N |
1 |
|
|
|
|
|
|
|||||
|
|
|
|
|
n 1 |
||||||||
|
|
|
|
|
|
|
|
|
|||||
если генеральная совокупность конечна (объема N).
Рассмотрим доверительный интервал для средней арифметической генеральной совокупности. Известно, что он симметричен относительно точечной оценки параметра и рассчитывается из соотношений:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
x |
z / 2 S |
|
|
или |
|
x t / 2 |
S |
|
|
|
|
|
|
x |
|
|
x |
|
|
|||||||
в зависимости от того, какое распределение используется при его определении: |
|
||||||||||||
нормальное или Стьюдента. |
|
|
|
|
|
|
|
|
|
||||
Здесь: |
|
|
|
|
|
|
|
|
|
|
|
|
|
z /2- значения z–статистики, справа и слева от которых находятся площади под |
|||||||||||||
кривой нормального распределения, равные |
/2 (определяются по таблице значений |
||||||||||||
стандартизованного нормального распределения при фиксированной вероятности |
); |
||||||||||||
t /2 - значения статистики Стьюдента, справа и слева от которых находятся |
|||||||||||||
площади под кривой распределения Стьюдента, равные |
/2 (определяются по таблице |
||||||||||||
значений распределения Стьюдента при фиксированной |
вероятности |
и |
чиcле |
||||||||||
степеней свободы |
= n-1); |
|
|
|
|
|
|
|
|
|
|||
sх – оценка стандартной ошибки выборки.
Отметим, что z-статистика используется при определении доверительного интервала в случае, если известно, что исследуемая совокупность имеет нормальный закон распределения и объем выборки достаточно велик, в противном случае используется статистика Стьюдента. Известно, что статистика Стьюдента может использоваться и в том случае, когда выполняются условия применимости z- статистики, поэтому в дальнейшем будем использовать t-статистику, если это не будет противоречить условиям решаемой задачи.
Во многих случаях появляется необходимость найти интервальную оценку для
разности средних двух совокупностей, т.е. для 1 - 2, по выборочным средним х1 и
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
х2 . Приведем эту оценку: |
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
x1 x2 |
t /2 |
. S |
|
|
|
, |
||
|
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
x1 |
x 2 |
|||
здесь S |
|
|
|
|
- стандартная ошибка разности средних. |
|||||||||||
x |
|
x |
|
|||||||||||||
1 |
|
|
2 |
|
|
|
|
|
|
|
|
|
|
|||
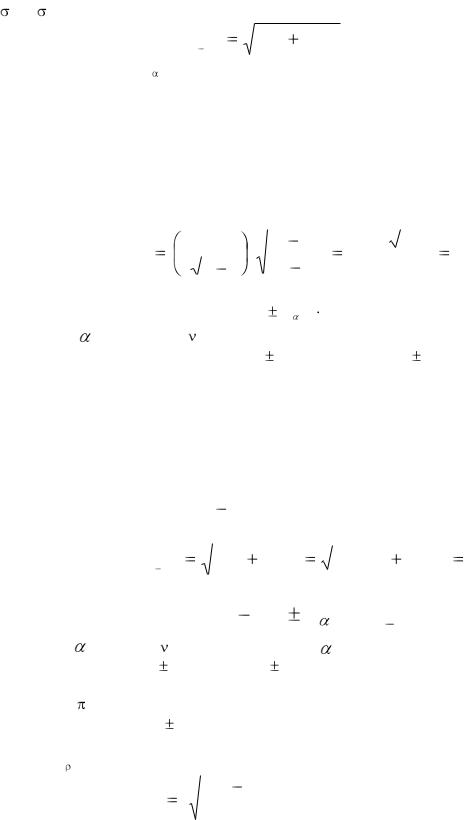
Стандартная ошибка разности средних и число степеней свободы для статистики Стьюдента определяются по-разному, в зависимости от того, равны или не равны объемы выборок и равны или нет дисперсии совокупностей. Например, приближенная формула для определения значения стандартной ошибки разности двух средних, основанная на допущениях о большом объеме двух выборок и их независимом отборе из двух генеральных совокупностей, характеризующихся одинаковой дисперсией (т.е.
12 = 22) имеет вид:
S |
|
|
|
S |
|
2 |
S |
|
2 |
, |
x |
|
x |
x |
|
x |
|||||
|
|
|
|
|
|
|||||
|
1 |
2 |
|
1 |
|
|
2 |
|
|
|
а число степеней для t /2 равно n1 + n2 |
–2. |
|
|
|
|
|||||
Рассмотрим решение задачи на принятие решения, в котором оказывается полезной интервальная оценка средней генеральной совокупности. Пусть составлена случайная выборка из 37 рабочих фирмы, в которой работает 785 человек. Причем средняя месячная зарплата для рабочих, попавших в выборку, равна 1100 руб. со стандартным отклонением 105 руб.
Используя 95 % - е доверительные пределы, вычислить среднюю месячную зарплату рабочих фирмы и общие расходы фирмы на зарплату.
Стандартную ошибку для средней в этом случае вычислим по формуле (2.2):
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
S |
|
|
|
S |
|
|
|
|
|
N |
n |
|
|
|
105 |
|
748 |
17,1. |
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
x |
|
|
|
|
|
|
N |
1 |
|
|
|
6 |
|
|
28 |
|
|
|||||
|
|
|
n |
1 |
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
Доверительные пределы равны: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
x t |
/ 2 |
S |
|
. |
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
x |
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
При |
= 0,05 и |
= 36 |
|
|
|
tα/2 = 2,03 ( из таблицы t-распределения). Тогда |
|||||||||||||||||
доверительный интервал равен: |
1 100 |
|
2,03 · 17,1 = 1 100 34,7 или |
(1 065,3 ; |
|||||||||||||||||||
1 134,7) (руб.).
Умножив на численность рабочих фирмы, получим оценку общих расходов фирмы на зарплату: от 836 260,5 до 890 739,5 (руб.).
Предположим теперь, что нам необходимо оценить наиболее вероятную разницу в средней зарплате для двух фирм, если во второй фирме для выборки из 30 рабочих средняя зарплата равна 1 000 руб. при стандартной ошибке средней в 20 руб.
Точечная оценка разности равна: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
x1 |
|
|
x2 = 1 100 – 1 000 = 100 (руб.). |
|||||||||||||||||
Вычислим стандартную ошибку разности средних: |
|
|
|
|||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
2 |
|
|
|
2 |
|
|
|
|
|
|
|
|
||||
|
S |
|
|
|
|
|
|
|
|
S |
|
|
S |
|
|
(17,1)2 |
(20)2 26,3. |
|||||||||||
|
x |
1 |
|
x |
2 |
|
|
x |
1 |
|
|
x |
2 |
|
|
|||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
Тогда интервальная оценка равна: |
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
x1 |
x 2 |
|
|
|
|
t /2 S |
|
|
|
. |
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
x1 |
x2 |
||||||||||||||
При |
= 0,05 и |
|
|
|
= n1 + n2 –2 = 65 |
t /2 = 2. Тогда имеем |
||||||||||||||||||||||
|
100 |
|
2 . 26,3 = 100 |
|
52,6 |
или (47,4 |
; 152,6) (руб.). |
|||||||||||||||||||||
Доверительный интервал для доли генеральной совокупности (относительной
величины) |
определяется из соотношения: |
||||||
|
p |
Zα/2 Sp , |
(2.3) |
||||
где р – |
выборочная доля, |
|
|
|
|||
S - |
оценка стандартной ошибки доли. |
||||||
|
|
|
|
|
|
|
|
Известно, что Sρ |
|
|
ρ (1 |
ρ) |
. |
||
|
|
n |
|
||||
|
|
|
|
|
|
|
|

Для определения доверительного интервала при этом используется аппроксимация биноминального распределения нормальным, поэтому использовать статистику
Стьюдента здесь нельзя. |
|
|
|
|
|
||||||
Как известно, такая аппроксимация возможна |
при достаточно больших объемах |
||||||||||
выборки (n |
50) и при выполнении условий np 5 |
и n(1 - p) 5. |
|||||||||
Аналогично определяется доверительный интервал (интервальная оценка) для |
|||||||||||
разности долей двух генеральных совокупностей ( |
1 - 2): |
||||||||||
|
|
|
p1 – p2 |
Z |
/2 |
|
. S p1–p2 , |
(2.4) |
|||
|
|
|
|
|
|
|
|
|
|
|
|
где Sp |
p |
|
|
Sp |
2 |
Sp |
|
2 |
|
- одна из формул для вычисления стандартной ошибки |
|
1 |
|
2 |
1 |
|
|
2 |
|
|
|
|
|
разности долей (в предположениях, аналогичных предыдущим).
Рассмотрим пример. Пусть фирмой при маркетинговом исследовании был организован опрос жителей одного из районов города относительно предпочтения товаров этой фирмы. Из 200 случайно отобранных жителей района 120 высказались в пользу товаров этой фирмы. Найти интервальную оценку доли жителей района, предпочитающих товары этой фирмы.
Точечная оценка доли: p = 120/200 = 0,6. Интервальную оценку вычислим по соотношению (2.3):
|
Sp |
|
0,6 (1 |
0,6) |
0,035. |
|
|
|
|
|
|
|
|
|
|||
|
200 |
|
|
|
||||
|
|
|
|
|
|
|
||
Z /2 при |
= 0,05 определим по таблице: Z0,025 = 1,96. |
Тогда имеем: |
||||||
|
0,6 1,96 · 0,035 |
или |
0,53 |
0,67. |
||||
Итак, в данном районе города товары этой фирмы предпочитают от 53 % до 67 % жителей.
Предположим, что в другом районе города в случайной выборке из 150 человек 55 % опрошенных предпочитают товары этой фирмы со стандартной ошибкой доли, равной 0,04. Тогда интервальная оценка разности долей жителей двух районов города определится из соотношения (2.4).
|
|
|
|
2 |
|
2 |
|
|
|
|
Sp |
p |
|
Sp |
Sp |
|
0,0352 |
0,042 0,053. |
|||
1 |
|
2 |
1 |
|
|
2 |
|
|
|
|
Получим: 0,6 – 0,55 |
1,96 |
0,053 |
или -0,054 |
0,154. |
||||||
Как известно, если доверительный интервал для разности двух величин содержит нуль, то эти величины различаются незначимо. Для нашего примера это означает, что в обоих исследуемых районах предпочтения для товаров этой фирмы примерно одинаковы.
2.1. Определение объема выборки, обеспечивающего заданную точность расчетов
Как уже отмечалось, интервальная оценка устанавливает прямую зависимость точности оценки от объема выборки. Запишем доверительный интервал для средней арифметической генеральной совокупности в виде:
|
|
|
|
S |
|
|
|
|
x t |
/2 |
|
|
|
. |
|||
|
|
|
|
|||||
|
|
|
|
|||||
n |
1 |
|||||||
|
|
|
|
|
||||
Выражение, прибавляемое и вычитаемое из выборочной средней, задает размах доверительного интервала и определяет, тем самым, точность интервальной оценки. При фиксированном стандартном отклонении точность оценки изменяется при