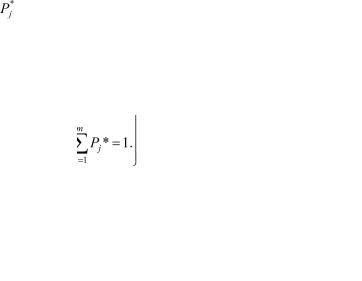ние mx, дисперсия Dx, стандартное отклонение sx, вероятность P наступления случайного события и другие параметры случайной величины.
Оценка параметра является функцией результатов испытаний, т. е. статистикой:
* = s(X1, X2, …, Xn). |
(12.1) |
Следовательно, оценка * является случайной величиной с присущим ей законом распределения и числовыми характе-
ристиками. Знание вероятностных характеристик позволяет выявить статистические свойства оценок, устанавливать их точность и на этой основе выбирать наилучшие оценки.
При интервальном оценивании определяют интервал, который с заданной вероятностью накрывает истинное значение оцениваемого параметра. Границы интервала являются функциями результатов испытаний. Поэтому в общем случае границы интервала, а следовательно, и сам интервал, будут случайными:
s (X1, X2, …, Xn) # # s0(X1, X2, …, Xn), |
(12.2) |
где s (X1, X2, …, Xn), s0(X1, X2, …, Xn) — статистики, отличные от статистики (12.1) и в каждом конкретном случае определяемые соответствующими соотношениями.
В математической статистике рассматриваемый интервал принято называть доверительным интервалом, а вероятность, с которой он накрывает истинное значение параметра, — дове-
рительной вероятностью.
Основное назначение доверительных оценок — характеризовать качество точечных оценок, определяемое их точностью и надежностью (достоверностью).
12.2.Основныетребованиякоценкам
Вид оценки каждой числовой характеристики выбирают один раз применительно к исследованию любой случайной величины. Эту выбранную оценку используют во всех случаях



 параметра
параметра  то оценку
то оценку  называют положительно
называют положительно — отрицательно смещенной.
— отрицательно смещенной.
 определяется выражением
определяется выражением
 параметра
параметра  =
= 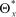 будет асимптотически эффективной, если
будет асимптотически эффективной, если  ) = 1.
) = 1.
 . Вариационный ряд, представленный в форме табл. 12. ,
. Вариационный ряд, представленный в форме табл. 12. , , по формуле в которой суммирование распространяется на значения
, по формуле в которой суммирование распространяется на значения  , меньшие
, меньшие 

 , включая его левую границу.
, включая его левую границу. [15]. При этом желательно, чтобы выполнялось условие
[15]. При этом желательно, чтобы выполнялось условие