

Into a . О
The theoretical relation between the a priori and a posterior variance factors allows us to test statistically the validity of our hypothesis. However, this particular topic is going to be dealt with elsewhere. Let us just comment here on the results of the adjustment of the levelling network discussed in Examples 6.17 and 6.19. In computing the weight matrix P, we assumed = 1. After the adjustment we
obtained a2 = 0.00067. Thus the ratio a2/a2 equals to 1500 which is con- o о о
siderably different from 1. This suggests that the variance-covariance matrix E- was postulated too "pessimistically" and that the actual variances
Li
of the observations are much lower.
6.U.10 Conditional Adjustment
In this section we are going to deal with the adjustment of the linear model (6.68), I.E.
В L = С , (r < n), (6.102)
which represents a set of ffr" independent linear conditions between n observations L« Note that С is an r by 1 vector of constant values arising from the conditions.
For the adjustment, the above model is reformulated as:
В (L + V) - С = 0 or, as we usually write it
В V + W =0 4) j (6.103)
where:
W = В L
(6.10k)
The system of equations (6.103) is known as the condition equations, in which В is the coefficient matrix, V is the vector of discrepencies and W is the vector of constant values. We recall that "n" is the number of observations and "r" is the number of independent
conditions. It should also be noted that no unknown parameters,.i.e. vector X, appear in the condition equations. The discrepencies V are the only unknowns
We wish again to get such estimate V of V that would minimize
T o-l
the quadratic form V PV, where P = 2> is the assumed weight matrix
T
of the observations L. The formualtion of this condition, i.e. min V PV,
Is not as straightforward, as it is in the parametric case (section 6.4.6)
This is due to the fact that V in equation (6.103) can not be easily
expressed as an explicit function of В and W. However, the problem can
be solved by introducing the vector К of r unknowns, called Lagrange1s
r,l
multipliers or correlates5). We can write:
min VTPV = min [VTPV + 2KT (BV + W)] , (6.105)
VeRn VeRn
since the second term on the right hand side equals to zero. Let us denote
ф = VTPV + 2KT (BV + W) .
To minimize the above function, we differentiate with respect to V and
equate the derivatives to zero. We get:
Эф -T T
r1 = 2V P + 2K В = 0
a
T
which, when transposed, gives PV + В К = 0.
-1
T
V =
~P
В
К
(6.106)
This system of equations is known as the correlate equations.
Substituting equation (6.106) into (6.103), we eliminate V: -1 T
B(-P В К) + W = 0 ,
or
(BP""XBT) К = W . j (6.107)
This is the system of normal equations for conditional adjustment. It is usually written in the following abbreviated form:
М К = W, (6-108)
where
м = в р"*1 вт, (6.109)
The solution of the above normal equations system for К yields: к = m"*"1 ¥ = (bp""2^)"1 W. (6.110)
Once we get the correlates K, we can compute the estimated residual vector V from the correlate equations (6.106). finally the adjusted observations L are computed from
L = L + V . (6.111)
In fact, if we are not interested in the intermediate steps, the formula for the adjusted observations L can be written in terms of the original matrices в and p and the vectors L and C. We get
L = L + V
-1 T = L - P В К
= L - p""1bt(bp"1bt)""1 (BL-C) . (6.112)
It can also be written in the following form:
L = (I - T) L + HC ,
(6.113)
where: 1 is the identity matrix %
T = p"1 [вт(вр~1вт)""1 B],
н = p"1 bt(bp"x bV1
(6.11U)
Example 6.20: Let us solve example 6.l6 again, using this time the conditional method of adjustment. We have only one condition equation between the observed height differences h^, i = 1,2,3> and we thus note that the number of degrees of freedom
is the same as in example 6.l6. Denoting H - H ЬуДН, the existing condition can he written as:
Eh. = AH.
1
After reformulation we get:
y± + v2 + v3 + (h + h2 + h3 - ЛН) = 0,
which can he easily written in the matrix form as
Б V + W = 0 1,3 3,1 1,1
where
В = [l, 1, l], V = v.
and
W = h + h2 + h^ - ДН
= E h. ~ ДН i 1
The weight' matrix of the observations is given by (see
example 6.l6):
P = diag (j-, ~~> 3,3 1 2 a3
and
P"1 = diag (d1, d2, d3). 3,3
The system of normal equations for the correlates К is given
by equation (6.108) as
.M К = W 1,1 1,1 1,1
where
M = BP""1 BT » (d1 + d2 + d3) = Edi<
The solution for К is
К = M"1 ¥ = y-p (Eh - ДН). i i i
The estimated residuals are then computed from equation (6.IO6) as:
dl 0
1 1 1
-1 T у = -P В К
d2 0
0 0
?h. - AH
)
11
Г 1 |
|
d„ |
|
1 |
?h. - 1 1 |
d |
|
2 |
? d. 1 1 |
d0 |
|
L 3 |
|
and we get:
ДН - Zh.
v. = —±± d., i = 1, 2; 3.
.d.
1 1
This is the same result as obtained in example 6.l6 when using the parametric adjustment (note that ЛН = HT - En).
J la-
in this particular problem, we notice that the adjustment
divide the misclosure, i.e. (ДН ~Е^1ь ), to the individual
observed height differences proportionally to the corresponding
lengths of levelling sections, i.e. inversely proportionally
to the individual MSE1 s. Tbe adjusted observations are given by equation (6.111) i.e.
L = L + V ,
or
This yields:
AH - Eh
h. = h. + — d, ,
1 1 ?d.
1 1
Finally, the estimates of the unknown parameters, ,i.e, X = (H^5 H^) , are computed from the known elevations BL, HT and the adjusted observations h, , as follows:
(id 1
H * H + h
1 G 1
я HG + hl +
?d.
l
l
(AH - Eh. )
i 1
and
H2 = HJ ~ h3
- Hj.h3
(AH - lh±)
The results are again identical to the ones obtained from the parametric adjustment.
Example 6.21: Let us solve example 6.17 again, but this time using the
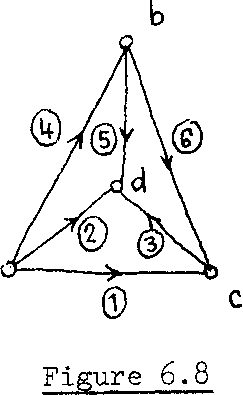
conditional adjustment. The configuration of the levelling network in question is illustrated again in Figure 6.8, for convenience.
From the above mentioned example we have: No. of observations, n = 6, No. of unknown parameters, u = 3.
Then df = 6 - 3 = 3, and we shall see that we can again formulate only 3 independent condition equations between the given observations.
By examining Figure 6.8, we see that there are к closed loops, namely: (a ~ с - d - a), (a-d-Ъ-а), (b - с - d - b) and (a - с - b - a).
This means that we can write k condition equations, one for each, closed loop. However, one can be deduced from the other 3, e.g. the last mentioned loop is the summation of the other three loops.
Let us ..for instance, choose the following three loops :
loop I=a-c-b-a>
loop 11= a-c-d-a>
loop III = a«d-b-a. These loops give the condition equations as follows
(E1 + Vl) " (^6 + V " (4 * V = °'
^1 + Vl^ + ^3 + V " ^2 + Y2^ = °> (h2 + v2) - (h5 + v5) - (h^ + v^) = 0.
Then we get
vi - vk - v6 + (51 - hk - Eg) = 0 ,
Vl - Y2 + V3 + (51 " E2 + V = °> V2 " rk ~ v5 + (й2 " \ ~ S) = ° '
The above set of condition equations can be written in the matrix notation as
В V + ¥ = 0 , 3,6 6,1 ЗА
where:
|
1 |
0 |
0 |
-1 |
0 |
-1 |
В |
1 |
-1 |
1 |
0 |
0 |
0 |
3,6 |
|
|
|
|
|
|
|
0 |
1 |
0 |
-1 |
-1 |
0 |
f = (V T2' YV V V V 1,6
and
¥ = 3,1
(h^ - h2 4 h^) ^(h2 - \ - h5)j
Substituting the observed quantities h\ , i = 1, 2, 6,
W = 3,1