

Скобцовы Моделирование и тестирование
.pdfявления состязаний сигналов, что существенно осложняет моделирование таких устройств.
Адекватность моделирования зависит, в основном, от используемой модели ДУ, моделей логических элементов и сигналов, способа учёта временных соотношений между сигналами. Обычно повышение степени адекватности связано со снижением быстродействия и увеличением необходимого объёма памяти. Самыми быстрыми являются алгоритмы двоичного моделирования в алфавите {0,1} без учёта задержек, где реальный порядок срабатывания элементов не принимается во внимание.
Учёт задержек элементов снижает быстродействие. Анализ переходных процессов требует увеличения значности алфавита.
2.3Модели сигналов
Впроцессе моделирования входные, выходные и внутренние переменные логических элементов схемы принимают значения из алфавита моделирования, используемого в данной системе моделирования.
Моделью сигнала называют соответствие между символами алфавита и реальными физическими сигналами.
Простейшим является двоичный алфавит В2 = {0,1}, в котором, как
правило, 0 соответствует низкому уровню сигнала, а 1 – высокому.
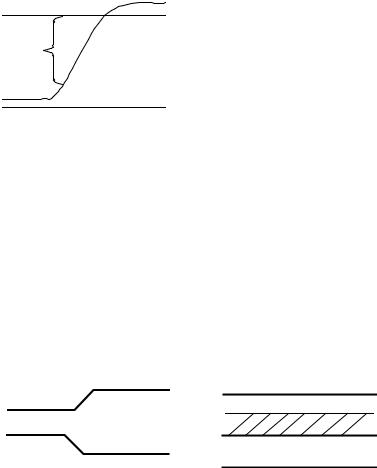
Для учета неоднозначности поведения ДУ часто используют
троичный алфавит Е3 = {0,1,u} (рис.2.4), где символ u обозначает
неизвестное или неопределенное значение сигнала (0 или 1, но
неизвестно, что именно). Символ u обычно используется для моделирования неопределённых, в том числе и начальных, состояний элементов памяти и неопределенностей, обусловленных явлением состязания сигналов, возникающих при переходных процессах, вызванных сменой входных воздействий.
41
1
u
0
Рис.2.4 Троичный алфавит
Кроме троичного применяется пятизначный алфавит Е5 = {0,1,Е,Н,u}, представленный на рис.2.5, где 0 – низкий уровень сигнала; 1–
высокий; Е – гладкий переход из 0 в 1 (передний фронт); Н – гладкий переход из 1 в 0 (задний фронт); u – неопределённое значение сигнала.
1 |
|
|
|
E |
1 |
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
H |
u |
|
|
|
|
||
0 |
|
|
|
0 |
|
|
|
||||
|
|
Рис.2.5 Пятизначный алфавит Е5
Для некоторых технологий (например, КМОП) моделирование даже определенных сигналов в статике требует введения дополнительных символов. Так иногда используют алфавит В4 ={0,1, ,z} , где символ z
соответствует состоянию высокого импеданса для схем с отключающимся выходом, а – конфликту на шине [1]. В настоящее время существует множество многозначных алфавитов, которые применяются в логическом моделировании и генерации тестов. Большая часть из них включается в универсальную систему многозначных алфавитов, которая представлена в разделе 3.
42
2.4 Модели логических элементов в двоичном алфавите
Моделирование ДУ в конечном счете сводится к моделированию функций отдельных логических элементов, которые используются программой супервизором. Моделирование одного комбинационного логического элемента есть вычисление значений его выходных переменных по заданным входным значениям. Для элемента с памятью необходимо вычислить значения его выходов и переменных следующего состояния по заданным входным значениям и текущему состоянию. Метод вычисления зависит от многих факторов, таких как тип элемента, алфавит моделирования системы, способ хранения входных значений и т.п.
2.4.1 Таблицы истинности
Сначала рассмотрим модели логических элементов в двоичном алфавите. Простейшей моделью логического элемента комбинационного базиса в двоичном алфавите является табличная модель, реализующая его таблицу истинности, рассмотренная в разделе 1.2.1 . Пусть значения булевой функции хранятся в одномерном битовом массиве V[i]. При вычислении значения выхода с помощью таблицы истинности необходимо выполнить следующие действия:
1)сформировать из двоичных значений входов одно двоичное слово;
2)перевести это двоичное слово в целое число – i;
3)определить значение выхода z=y[i].
Рассмотрим для примера таблицу истинности вентиля И с тремя входами, представленную в табл.2.1.
При этом в памяти компьютера хранятся только значения функции
(столбец Y для нашего примера). Вычисление значения выхода элемента по данным значениям входов сводится к получению индекса и выборке с его помощью нужного значения. Пусть для определенности в нашем примере входные значения x1=1, x2=0 , x3=1 дают индекс i=1012=510 массива Y;
43
таким образом, получаем Y[5]=0. Несмотря на свою простоту, это очень
эффективный и быстрый метод вычисления. Но, очевидно, при увеличении числа входов он требует больших затрат памяти.
Таблица 2.1
a |
b |
c |
Y |
|
|
|
|
0 |
0 |
0 |
0 |
|
|
|
|
0 |
0 |
1 |
0 |
|
|
|
|
0 |
1 |
0 |
0 |
|
|
|
|
0 |
1 |
1 |
0 |
|
|
|
|
1 |
0 |
0 |
0 |
|
|
|
|
1 |
0 |
1 |
0 |
|
|
|
|
1 |
1 |
0 |
0 |
|
|
|
|
1 |
1 |
1 |
1 |
|
|
|
|
2.4.2 Таблицы zoom
При использовании таблиц истинности в моделировании необходимо сначала определить тип соответствующего логического элемента. Поэтому определение типа элемента и собственно вычисление выходного значения выполняются в два этапа. Эти два шага можно объединить в один следующим образом. Пусть t является номером типа элемента и S - максимальный размер таблицы истинности (для всех типов).
Тогда можно построить таблицу zoom размера t S , в которой хранятся t
таблиц истинности, которые начинаются с позиции 0, S,…, (t-1)S. Для вычисления значения выхода элемента с использованием такой таблицы необходимо упаковать тип элемента и значения его входов в одно слово,
которое определяет индекс в таблице zoom, как это показано на рис.2.6.
44

Применение zoom таблиц позволяет значительно ускорить процесс вычислений, поскольку заменяет последовательность вычислений одним шагом выборки необходимого значения.
Тип i-1
Тип |
Значение |
Индекс |
Тип 1 |
S |
Тип 0 |
|
Рис.2.6 Zoom таблица
2.4.3 Программные функциональные модели
Очень распространенным методом построения моделей является составление программы с помощью логических операторов языка высокого уровня (например, C) или ассемблера непосредственно по логическому выражению булевой функции или логической схеме,
построенному с помощью операций конъюнкции, дизъюнкции и отрицания (иногда и ). В отличие от предыдущих табличных методов, в
которых модель элемента представлена фактически структурой данных, а
сама программа вычисления значения выхода является универсальной,
здесь модель элемента представляется непосредственно программой (и она уникальна для каждого типа элемента). Часто программная модель компилируется на основе структурной модели автоматически. Рассмотрим этот метод на примере схемы, представленной на рис.2.7.
С использованием языка программирования С эта схема моделируется следующим образом:
E=A&B;
45

F=!(C&D);
Y=E F;
A |
& |
Е |
|
|
|
|
|
B |
|
|
|
|
|
|
|
|
|
|
|
1 Y
C |
& |
F |
|
D
Рис.2.7 Пример схемы
Эта программа компилируется в машинный код и далее используется при моделировании путем вызова соответствующей функции.
С использованием ассемблера модель этой схемы (представляющей логический элемент) имеет следующий вид, представленный на рис.2.8.
LDA A |
/* загрузка сумматора А */ |
||
AND B |
/* вычисление A&B*/ |
||
STA E |
/* запоминание E*/ |
||
LDA C |
/* загрузка сумматора C */ |
||
AND D |
/* вычисление C&D*/ |
||
INV |
/* инвертирование C&D */ |
||
|
/* вычисление E |
|
*/ |
OR E |
C & D |
||
STA Y |
/* запоминание выхода Y */ |
||
Рис.2.8 Модель схемы на ассемблере
2.4.4 Алгоритмические функциональные модели
При этом подходе функционирование элемента задается с помощью некоторого алгоритма. Например, для вентиля И y=x1&x2&x3 это можно
46
сделать следующим образом:
если x1= 0, то y = 0;
если x2= 0, то y = 0;
если x3= 0, то y = 0;
иначе y = 1.
Этот метод широко используется на функциональном уровне ЯРП поскольку позволяет, например, описать систему команд микропроцессора.
При построении моделей логических элементов применяются также альтернативные графы (двоичные диаграммы) и т.п.
2.5 Модели логических элементов в многозначных алфавитах
При построении многозначных моделей элементов используются те же подходы, что и в случае двоичного алфавита. Рассмотрим сначала
моделирование логических элементов |
в троичном алфавите |
E3. |
Для |
примера возьмем 2-входовой вентиль И |
y=x1&x2. Входы и выход этого |
||
элемента принимают значения из троичного алфавита E3={0,1,u}. |
Пусть |
||
входы имеют значения x1=0, x2=u. |
Чему равно значение выхода y в |
||
алфавите E3? Поскольку символ u представляет два значения |
u={0 1} |
||
(это 0 или 1 , но неизвестно, что именно), то моделирование на одном троичном наборе можно выполнить путем моделирования на двух двоичных наборах, покрываемых троичным, и затем сравнить результаты.
Для нашего примера имеем: 1) значения первого двоичного набора x1=0, x2=0 (покрываемом троичным) дают y=0; 2) значения второго двоичного набора x1=0, x2=1 также дают y=0. Поскольку значения выхода y для двух двоичных наборов совпадают, то полагаем y=0 (где 0 – символ троичного алфавита). Для другого входного троичного набора x1=1, x2=u аналогично получаем: 1) значения первого двоичного набора x1=1, x2=0 дают y=0; 2)
значения второго двоичного набора x1=1, x2=1 дают y=1. Поскольку
47
значения y различны для двоичных наборов, покрываемых данным троичным, полагаем значение выхода y=u. Исходя из подобных соображений и физического смысла, можно построить табличные модели логических элементов в 3- и 5-значном алфавитах.
2.5.1 Табличные многозначные модели
В таблицах 2.2-2.4 представлены 5-значные модели стандартных 2-
входовых вентилей соответственно И, ИЛИ и НЕ. |
|
|
|
|
|||||||||||||
|
Таблица 2.2 |
|
|
|
Таблица 2.3 |
Таблица 2.4 |
|||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
И |
0 |
1 |
u |
|
Е |
Н |
|
ИЛИ 0 1 u Е Н |
|
|
НЕ |
|
|
|||
|
0 |
0 |
0 |
0 |
|
0 |
0 |
|
0 |
0 |
1 |
u Е Н |
|
|
0 |
1 |
|
|
1 |
0 |
1 |
u |
Е |
Н |
|
1 |
1 |
1 |
1 1 1 |
|
|
1 |
0 |
|
|
|
u |
0 |
u |
u |
u |
u |
|
u u 1 u u u |
|
|
u |
u |
|
||||
|
Е |
0 |
Е |
u |
Е |
u |
|
Е Е 1 |
u Е u |
|
|
Е |
Н |
|
|||
|
Н |
0 |
Н |
u |
u |
Н |
|
Н Н 1 |
u u Н |
|
|
Н |
Е |
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
При этом левый верхний угол таблиц содержит трехзначную часть.
Справедливость этих таблиц нетрудно проверить, исходя из смысла символов соответствующего алфавита. При программной реализации обычно символы многозначного алфавита кодируются целыми числами, а
таблицы описываются в виде двумерных массивов. Так перекодированная таблица И (Табл.2.2) будет иметь следующий вид, представленный в
табл.2.5.
Таблица 2.5 |
|
|
|
Таблица 2.6 |
|
|
Таблица 2.7 |
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
И |
0 |
1 |
2 |
3 |
4 |
|
|
f * |
f 0 |
f 1 |
|
x* |
x0 |
x1 |
||
0 |
0 |
0 |
0 |
0 |
0 |
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
0 |
1 |
0 |
||||||
1 |
0 |
1 |
2 |
3 |
4 |
|
|
A*B* |
A0 B0 |
A1B1 |
|
|||||
|
|
|
|
|
|
|||||||||||
2 |
0 |
2 |
2 |
2 |
2 |
|
|
|
|
|
|
|
|
1 |
0 |
1 |
|
|
A* B* |
A0 B0 |
A1 B1 |
||||||||||||
3 |
0 |
3 |
2 |
3 |
2 |
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
u |
1 |
1 |
||||||
4 |
0 |
4 |
2 |
2 |
4 |
|
|
|
|
|
|
|
|
|||
|
|
|
|
1 |
|
0 |
||||||||||
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
A* |
A |
A |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
48
При этом вычисление значение выхода в многозначном алфавите по заданным значениям входов сводится к выборке нужного элемента в двумерном массиве, так как значения входов определяют индексы этого массива. Пусть, например, для вентиля И модель описана в виде двумерного массива TAND[0:4, 0:4]. При входных значениях x1=1 (соответствует символу 1 E3) и x2=2 (соответствует символу u) получаем y=TAND[1,2]=2, что соответствует неопределенному значению u. Ясно,
что с ростом числа переменных резко возрастает объем требуемой памяти и метод становится практически непригодным. Следует отметить, что эвристический подход к построению моделей логических элементов в многозначных алфавитах и табличная форма задания модели, сдерживают дальнейшую разработку многозначных моделей для сложных ДУ,
реализованных на СБИС. В третьем разделе рассмотрены более подробно вопросы построения многозначных моделей, как на вентильном, так и на функциональном уровне.
2.5.2 Компонентные многозначные модели
Данный способ построения многозначных моделей элементов основан на кодировании многозначных алфавитов и является обобщением метода построения моделей, изложенного в разделе 2.2.3 для двоичного алфавита. Рассмотрим сначала троичные компонентные модели. Так как каждая троичная переменная x* принимает три значения {0,1,u},то она может быть представлена двумя булевыми переменными, принимающими двоичные значения. Для этого используются различные способы кодирования троичного алфавита [1]. Мы, в основном, будем использовать дизъюнктивный метод кодирования троичного алфавита, представленный табл.2.7.
Здесь переменные x0 , x1 могут принимать только двоичные значения.
В современных системах моделирования, как правило, компоненты
49
хранятся в разных машинных словах. Очевидно, что при таком подходе
для моделирования логического |
элемента |
с троичной |
функцией f* |
необходимо две булевых функции |
f 0 и f 1. |
В табл.2.6 |
представлены |
троичные компонентные модели основных вентилей для дизъюнктивного метода кодирования.
Известен простой способ построения функций f 0 и f 1 для
произвольной булевой функции. Если f задана дизъюнктивной нормальной формой (ДНФ), то компонента f 1 получается из ДНФ функции f заменой
вхождений переменных xi на xi1 и |
|
i |
|
на xi0 . Аналогично компонента |
f 0 |
||||||||||||||||||||||||||||||||
x |
|
||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Например, для функции |
|||||||||
получается из ДНФ отрицания функции |
f |
. |
|||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
f 1 = a1b0 b1c1 b0c0 |
|
|||||
f = ab |
bc cb |
и |
f = cb ab c |
|
имеем |
и |
|||||||||||||||||||||||||||||||
f 0 = c1b0 a1b0c0 . |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||
|
2.5.3 Метод сканирования входов |
|
|
||||||||||||||||||||||||||||||||||
Таблица 2.8 |
|
|
|
|
|
|
|
|
|
|
Таблица2.9 |
|
|
|
|
|
|
|
|
||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
C |
|
I |
|
|
|
|
C |
|
x |
|
x |
|
c i |
|
|
||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||
И |
|
0 |
|
|
|
|
0 |
|
|
|
|
X |
|
c |
|
x |
|
c i |
|
|
|||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||
ИЛИ |
|
1 |
|
|
|
|
0 |
|
|
|
|
X |
|
x |
|
|
|
c |
|
c i |
|
|
|||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
НЕ-И |
|
0 |
|
|
|
|
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
i |
|
|
|||||
|
|
|
|
|
|
|
|
c |
|
c |
|
|
|
c |
|
c |
|
|
|||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
НЕ-ИЛИ |
|
1 |
|
|
|
|
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
В большинстве программ моделирования в качестве базовых
(элементарных) логических элементов используются простейшие вентили
И, ИЛИ, НЕ, НЕ-И, НЕ-ИЛИ. Они характеризуются, прежде всего, двумя параметрами: контролирующее значение c и инверсия i. Значение входа называется контролирующим, если оно определяет выход вентиля, равный y = c i , независимо от значений остальных входов. Табл. 2.9 и 2.8
50