Структура ис на основе хд
|
Примерная структура ИАС Примерная структура ИАС, построенной на основе ХД, показана на рисунке.
В конкретных реализациях отдельные компоненты этой схемы могут отсутствовать. При такой организации ИАС ХД функционирует по следующему сценарию: по заданному регламенту в него собираются данные из различных источников – БД систем оперативной обработки. В ХД поддерживается хронология: наравне с текущими хранятся исторические данные с указанием времени, к которому они относятся. В результате необходимые доступные данные об объекте управления собираются в одном месте, приводятся к единому формату, согласовываются и, в ряде случаев, агрегируются до минимально требуемого уровня обобщения. Несмотря на то, что ХД содержат заведомо избыточную информацию, которая и так имеется в базах или файлах оперативных систем, появление концепции ХД вызвано тем, анализировать данные оперативных систем напрямую невозможно или очень затруднительно. Это объясняется:
Можно констатировать, что практически в любой организации сложилась парадоксальная ситуация: - информация вроде бы, где-то и есть, её даже слишком много, но она неструктурированна, несогласованна, разрознена, не всегда достоверна, её практически невозможно найти и получить. В результате можно говорить об отсутствие информации при ее наличии и даже избыточности.. Для того, чтобы извлекать полезную информацию из данных, они должны быть организованы способом, отличным от принятого в OLTP-системах потому что:
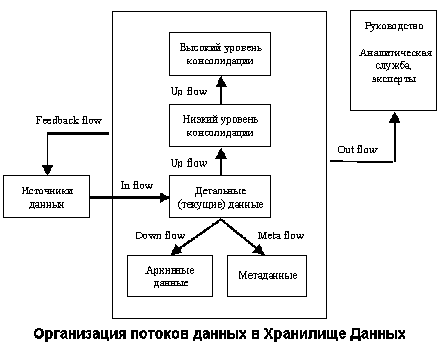
Организация потоков данных Организация потоков данных в ХД показана на рисунке
|