

Кол. методы МБА 2012 / 1. Статистика / Книга по стат. методам / Книга
.pdfРис. 3.5.
Медиана обладает рядом полезных свойств. Во-первых, ее целесообразно применять в качестве оценки среднего в тех случаях, когда выборочные данные содержат «выбросы» – значения, существенно отличающиеся от основной массы наблюдений. Во-вторых, медиана может быть определена и для данных, измеряемых в шкале рангов, упорядоченных по любому качественному или количественному признаку.
3.4. Мода
Модой (Mo) называют значение исследуемой величины, чаще всего, встречающееся в наборе данных. Потребность в использовании этого показателя может возникнуть во многих ситуациях. Например, в торговом бизнесе, где требуется выявить чаще всего покупаемые товары, в швейном производстве для оценки наиболее модных (востребованных) размеров и фасонов одежды и т.д.
В отличие от первых двух типов средних – средней арифметической и медианы, мода может быть определена и для данных
61

качественного характера – наиболее востребованные типы офисов, чаще всего покупаемые марки телевизоров или холодильников, наиболее предпочитаемые туристами классы отелей, блюда в ресторане и т.д.
Определить, чему равна мода в каком-либо наборе зафиксированных данных, проще всего на основе ряда распределения или на основе гистограммы (п.п. 2.2–2.4). Очевидно, что мода равна тому значению исследуемой величины, которому соответствует наибольшая частота в сгруппированном ряде распределения или наивысшая точка на гистограмме.
Пример 3.1. Статистика месячных продаж джинсов различных производителей в одном из магазинов города приведена в таблице 3.2.
|
|
Таблица 3.2. |
|
|
|
|
|
Торговая марка |
Продано (шт) |
Доля продаж (в %) |
|
Guess |
23 |
12% |
|
Wrangler |
46 |
23% |
|
Lee |
31 |
16% |
|
Mustang |
18 |
9% |
|
Levi`s |
43 |
22% |
|
Montana |
15 |
8% |
|
GAP |
21 |
11% |
|
Распределение объемов продаж по торговым маркам
25% |
|
|
|
23% |
22% |
|
|
|
|
|
|
|
|
|
|
||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||
20% |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||
|
|
|
|
|
|
|
16% |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
15% |
|
|
12% |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
11% |
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
10% |
|
|
|
|
|
|
|
|
|
|
|
9% |
|
|
|
|
8% |
|
|
|
|
|
|
||||||
|
|
|
|
|
|||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||
5% |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0% |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Guess |
|
|
Wrangler Lee Mustang Levi`s Montana GAP |
|
|
||||||||||||||||||||||
|
|
|
|
|
|
|
|||||||||||||||||||||||
Рис. 3.6.
Данные примера не имеют отношения к реальным объемам продажа и носят иллюстративный характер.
62

Анализ таблицы показывает, что «модами» – наиболее модными торговыми марками в прошедшем месяце оказались джинсы Wrangler и Levi`s (23% и 22% всех продаж). Графически эти выводы иллюстрирует гистограмма – рис. 3.6, построенная в Excel на основе данных табл. 3.2.
Заметим, что в данном примере выбраны две моды – два наиболее часто встречающихся значения «признака».
Во многих реальных ситуациях на «первое место» могут претендовать две или более категорий с долями, резко выделяющимися из остальных. Сколько значений выбрать в качестве моды – решает аналитик, в зависимости от целей и задач исследования.
Пример 3.2. Для оценки и прогнозирования затрат фирмы по оплате междугородней связи менеджер проанализировал счет, полученный от телефонной компании, с точки зрения времени (в минутах), ежедневно затрачиваемого сотрудниками на междугородние переговоры. Данные за 21 рабочий день приведены на рис. 3.7.
Какие полезные выводы и заключения можно сделать на основе имеющихся данных?
Решение
Используя инструменты «Описательная статистика» – рис. 3.7 и «Гистограмма» – рис. 3.8. из «Пакета анализа» Excel, а также построив гистограммы для частот – рис. 3.9 и относительных частот (долей в процентах) – рис. 3.10, выясняем следующее.
Среднее время, затрачиваемое на переговоры составляет 19 минут в день ( Y = 19 – строка «Среднее» в таблице на рис. 3.7).
В половине случаев продолжительность междугородних телефонных переговоров не превышает 20 минут в день (Me = 20 – строка «Медиана» в таблице на рис. 3.7).
Чаще всего – в 29% случаев длительность разговоров по межгороду составляет 21 минуту в день (Mo = 21 – строка таблицы «Мода» на рис. 3.7.). Другим часто встречающимся значением, которое также можно отнести к моде, является продолжительность разговоров, равная 17 минутам – 24% случаев (рис. 3.9, 3.10).
63

Рис. 3.7.
Рис. 3.8.
64

Частота
7 |
|
|
Распределение времени на междугородние |
|
||||||||||||||||||
|
|
|
|
|
|
|
|
переговоры |
6 |
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
6 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
5 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
5 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
4 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3 |
|
|
|
2 |
|
|
|
|
|
|
|
|
2 |
|
|
2 |
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
|
|
|
1 |
1 |
|
|
|
|
|
|
|
1 |
|
||||||
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
Mo |
|
|
|
|
|
|
|
Me |
|
Mo |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
0 |
|
|
|
|
|
|
|
|
|
|
Y |
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
15 |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
|
|||||||||||||
Рис. 3.9.
Распределение времени на междугородние |
|
|
|
|||||||||||||||||||
30% |
|
|
|
|
|
|
переговоры |
|
|
29% |
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
24% |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
25% |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
20% |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
15% |
|
|
|
10% |
|
|
|
|
|
|
|
|
10% |
|
|
10% |
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
10% |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
5% |
|
|
|
|
5% |
5% |
|
|
|
|
|
|
5% |
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
5% |
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
|
|
Mo |
|
|
|
|
|
|
|
Me |
|
Mo |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
0% |
|
|
|
|
|
|
|
|
|
|
Y |
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
15 |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
|
|||||||||||||
Рис. 3.10.
При прогнозировании затрат на междугородние телефонные переговоры следует учесть, что ежедневная потребность в них составляет не менее 15, но и не более 23 минут (Y min =15 , Y max = 23) – рис. 3.7, 3.9, 3.10. В качестве ориентира для расчетов, по-видимому, наиболее целесообразно ориентироваться на значение медианы (20 минут), поскольку и слева и справа от нее расположены по 50% всех реальных значений длительности переговоров.
65

3.5. Какую из средних следует использовать?
Один из вопросов, возникающих после начальной обработки статистической информации – группировки, построения гистограмм,
вычисления средних заключается в том, чтобы определить какой из трех показателей – среднее, моду или медиану выбрать в качестве типичного значения исследуемого показателя.
Подобный выбор напрямую связан с особенностями распределения исследуемого показателя. Наиболее просто вопрос решается в тех случаях, когда распределение носит симметричный характер. Для симметричных распределений, таких, например, как распределение, показанное на рис. 3.11, все три показателя (мода, медиана и средняя) приближенно равны между собой y ≈ Me ≈ Mo .
Поэтому проблемы выбора для симметричных распределений не существует.
Симметричное распределение |
|
Mo=Me= Y |
Y |
|
Рис. 3.11
В случаях ассиметричного распределения данных, например таких, как показано на рис. 3.12 (положительная правая асимметрия), значения средних могут существенно отличаться. Средняя арифметическая в подобных распределениях будет наибольшей из всех и смещенной в сторону нескольких «выбросов», больших, чем остальные данные. Следующей по величине, в порядке убывания, обычно следует медиана, а затем мода.
66
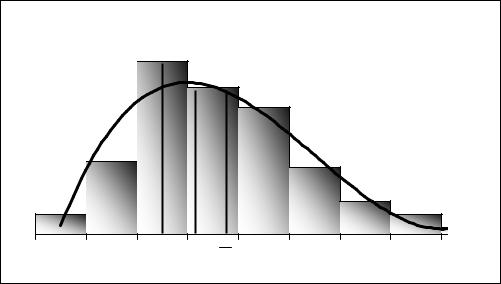
Для распределений с левой (отрицательной) асимметрией, например, таких, как распределение в примере 3.2 – рис. 3.9, 3.10, картина имеет противоположный характер – наименьшее значение имеет средняя арифметическая, затем следуют медиана и мода.
Для распределений с выраженной асимметрией наилучшей характеристикой в качестве «типичного значения» является медиана, поскольку, на нее не влияют, как на среднюю арифметическую, отдельные выбросы и она не зависит, как мода, от частоты отдельных значений.
Асимметричное распределение |
Y |
Mo Me Y |
Рис. 3.12 |
Выбор моды в качестве наиболее типичного значения чаще всего диктуется предметом анализа, когда в первую очередь необходимо оценить, например, предпочтения потребителей, наиболее «модные» и востребованные услуги, товары.
3.6. Измерение разброса данных относительно средних значений
Необходимость учета и измерения разброса данных относительно средних значений возникает во многих практических ситуациях. Чем ближе и «плотнее» концентрируются данные около средней, тем эта средняя более надежна и представительна в качестве оценки наиболее типичного значения исследуемого показателя.
67

В качестве «измерителей» степени разброса значений случайной величины относительного среднего значения – μ в теории ве-
роятностей используют дисперсию и стандартное отклонение,
обозначаемые символами D и σ. Между собой они связаны соотношением
σ =  D или σ2 = D .
D или σ2 = D .
Если дискретная случайна величина, X с конечным числом возможных значений, задана своим рядом распределения (табл.3.3), то ее дисперсия вычисляется по формуле
|
|
|
|
n |
|
|
|
D = D(Y ) = ( y1 −μ)2 p1 + ( y2 −μ)2 p2 +K+ ( yn −μ)2 pn = ∑( yi |
−μ)2 pi |
||||||
|
|
|
|
i=1 |
|
|
|
|
|
|
|
Таблица 3.3. |
|||
|
|
|
|
|
|
|
|
|
Значения Y |
y1 |
y2 |
. . . |
|
yn |
|
|
Вероятности P (Y = yi) |
P1 |
P2 |
. . . |
|
Pn |
|
Как видно из формулы, дисперсия случайной величины – это математическое ожидание для квадрата ее отклонения от среднего значения.
Для непрерывных случайных величин дисперсию вычисляют на основе функции плотности распределения (см. Приложение 1)
D = D( y) = +∞∫( y − μ)2 f ( y) dy .
−∞
Приведенные формулы вычисления дисперсии и стандартного отклонения относятся к «теоретическим» распределениям в предположении, что законы распределения случайной величины y из-
вестны и заданы либо рядом распределения, либо функцией плотности вероятности f ( y).
На основе статистических выборочных данных, например, выборки из N наблюдений y1 , y2 ,K, yN , для вычисления дисперсии генеральной совокупности – значения, приближенно равного истинному значению S 2 ≈ D , используют следующее соотношение:
68

|
N |
|
|
|
S 2 = |
∑( yi |
− y)2 |
|
|
i=1 |
|
, |
||
N −1 |
||||
|
|
|||
где y – выборочная средняя (оценка математического ожидания генеральной совокупности):
N
∑ yi
y = i =1N .
В Excel вычислить дисперсию и стандартное отклонение с помощью инструмента «Описательная статистика» из «Пакета ана-
лиза» – пункт меню Сервис ¾ Анализ данных ... ¾ Описательная статистика.
Стандартное отклонение как мера разброса (вариации) данных может использоваться, в частности, для определения диапазонов, куда попадает определенная доля возможных значений исследуемых случайных величин. Для этих целей можно использовать известное в теории вероятностей неравенство Чебышева, которое для выборочных данных можно трактовать следующим образом.
Доля значений, попадающих в интервал y ± k S , будет равно,
по крайней мере (не менее, чем 1−1/ k 2 , где k – любое число, большее единицы k >1.
Так, например, доля значений, попадающих в интервал y ± 2 S (среднее плюс/минус два стандартных отклонения) будет
не менее чем 1−1/ 4 = 0,75 , т.е. 75%.
Неравенство справедливо для любых совокупностей, независимо от особенностей (законов) их распределения.
Пример 3.3. Дневной доход 30 менеджеров среднего звена, зависящий от объема проданного ими товара колеблется от 30 до 50 условных денежных единиц (у.д.е.) – табл. 3.4. Какую полезную информацию несет этот статистический материал?
Решение
Для решения, вычислим с помощью инструмента «Описательная статистика» из «Пакета анализа» основные числовые характеристики выборки – рис. 3.13.
69
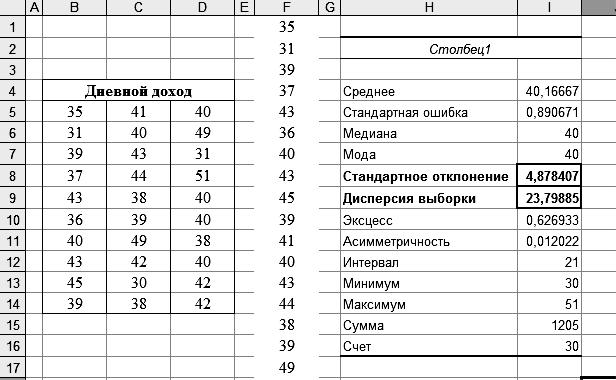
|
|
|
Таблица 3.4. |
|
|
|
|
|
|
|
|
Дневной доход |
|
|
|
35 |
41 |
40 |
|
|
31 |
40 |
49 |
|
|
39 |
43 |
31 |
|
|
37 |
44 |
51 |
|
|
43 |
38 |
40 |
|
|
36 |
39 |
40 |
|
|
40 |
49 |
38 |
|
|
43 |
42 |
40 |
|
|
45 |
30 |
42 |
|
|
39 |
38 |
42 |
|
|
|
|
|
|
|
|
|
|
|
Рис.3.13.
Как видно, средний доход менеджеров составляет ~40 у.д.е., а стандартное отклонение – S = 4,878 ≈ 5. Этими результатами можно воспользоваться, например для того, чтобы оценить – границы дохода для 75% менеджеров. Для этого используем результат, полученный на основе неравенства Чебышева. Как показано выше, не менее 75% выборочных статистических данных находятся в диапазоне y ± 2 S , следовательно, для рассматриваемого примера – не менее
75% менеджеров имеют дневной доход от 30 до 50 у.д.е. (40 ± 2 5) .
70