

Кол. методы МБА 2012 / 1. Статистика / Книга по стат. методам / Книга
.pdfВ математической статистике и теории вероятностей установ-
лено, что сумма независимых случайных величин, каждая из кото-
рых может иметь любой закон распределения, распределена по нормальному закону. Причем, чем больше число слагаемых, тем ближе к нормальному закону распределена их сумма. Кроме того, он является предельным законом, к которому приближаются другие законы распределения при выполнении определенных условий. В экономике, где на экономический результат оказывает влияние огромное число самых разнообразных факторов, этот закон играет исключительно важную роль.
Нормальный закон распределения характеризуется функцией плотности вероятности вида
f (x) = |
|
1 |
e− |
( x−μ)2 |
|
|
|
σ |
2σ 2 |
|
|
(П1.4) |
|||
|
2π |
|
|
|
|
|
|
Как следует из (П1.4) он полностью определяется двумя па- |
|||||||
раметрами – μ и σ , где μ – математическое ожидание, σ – стан- |
|||||||
дартное отклонение. |
|
|
|
|
|
|
|
Кривая функции плотности вероятности случайной величины, |
|||||||
распределенной по нормальному закону, показана на рис. П1.11. |
|||||||
f(x) |
|
|
|
|
1 |
− |
( x −μ)2 |
|
|
|
|
|
2σ2 |
||
|
|
|
f (x) = |
σ 2π |
e |
|
|
|
|
|
|
|
|
|
X |
3σ |
|
μ |
|
|
3σ |
|
|
Рис. П1.11. |
|
|
|
|
|||
|
|
|
|
|
|
|
211 |



Рис. П1.14.
Если для нормально распределенной случайной величины известны значения μ, σ или их оценки, вычисленные на основе имею-
щейся статистики – X , S (в этом случае полагают μ ≈ X , σ ≈ S ), то
с помощью стандартных функций Excel можно вычислить вероятности того, что случайная величина окажется в том или ином диапазоне значений.
Для вычисления в Excel нужной вероятности в какой либо из ячеек рабочего листа Excel необходимо записать правые части одной из следующих формул:
y Вероятность того, что значения случайной величины X примут значения, меньшие, чем a (рис. П1.15):
P ( X < a) = НОРМРАСП ( a; μ; σ; ИСТИНА) |
f(x) |
P (X < a) |
x |
a |
Рис. П1.15. |
214


f(x) |
|
P(X < b) = Pзад. |
|
b = ? |
x |
Рис. П1.18. |
|
А именно: требуется найти такое граничное (критическое) |
|
значение b, которое с заданной вероятностью Pзад. = γ |
не будет пре- |
вышено. Критическое значение b называют квантилем уровня γ . |
|
Для решения такой задачи в Excel предусмотрена специальная |
|
функция НОРМОБР(…) . Вызов функции: Вставка ¾ Функция ¾ |
|
Категория «Статистические» ¾ НОРМОБР(…) – рис. П1.19, |
|
П1.20. |
|
Рис. П1.19.
216
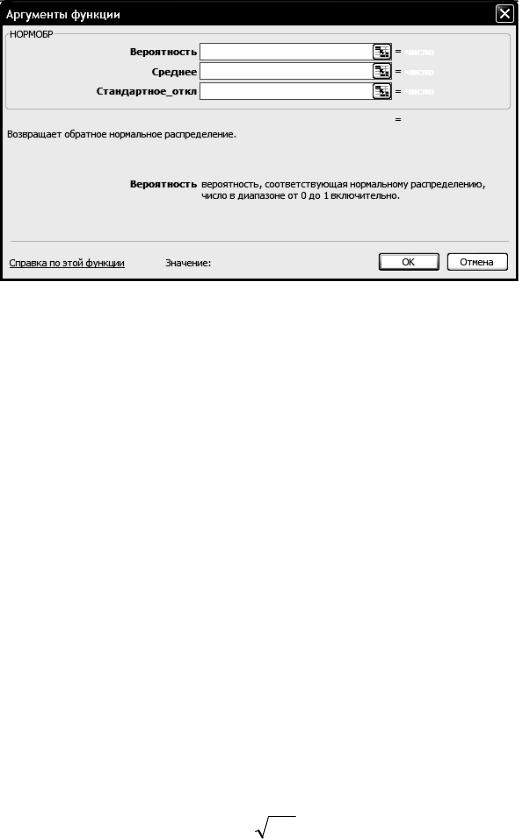
Рис. П1.20.
Для нахождения такого критического значения b в Exel в одной из ячеек рабочего листа необходимо записать правую часть формулы b = НОРМОБР ( Pзад.; μ; σ )
П1.3.5. Логарифмически нормальное распределение
В ряде экономических задач, связанных с изучением распределения доходов, заработных плат, сроков эксплуатации, долговечности устройств и некоторых других, встречаются распределения, получившее название логарифмически нормальных.
Непрерывная случайная величина X имеет логарифмически нормальное распределение, если ее натуральный логарифм ln(X ) подчинен нормальному закону распределения ln(X ) ~ N(a; σ) .
Функция плотности вероятности случайной величины X, имеющей логарифмически нормально распределение имеет вид
f (x) = |
1 |
|
e |
− |
(ln x−ln a)2 |
|
|
2σ 2 |
. |
||||
σ x |
2π |
|
|
|||
|
|
|
|
|
Числовые характеристики распределения:
yМатематическое ожидание μx = a eσ 2  2 .
2 .
yДисперсия σx2 = a2 eσ2 (eσ2 −1) .
217


Рис. П1.23.
Для вычисления в Excel нужной вероятности в какой либо из ячеек рабочего листа Excel необходимо записать правые части одной из следующих формул:
y Вероятность того, что значения случайной величины X примут значения, меньшие, чем a:
P( x < a) = ЛОГНОРМРАСП ( a; μx ; σx ) .
y Вероятность того, что значения случайной величины X примут значения, большие, чем b:
P( x > b) = 1 – ЛОГНОРМРАСП ( b; μx ; σx )
y Вероятность того, что значения случайной величины X будут находиться в диапазоне от a до b:
P(a < x < b) = ЛОГНОРМРАСП ( b; μx ; σx ) –
– ЛОГНОРМРАСП ( a; μx ; σx ) .
219

