

Автоматический газовый хроматографический анализ
..pdfРис. 58. Кривые изменения Рп.о в функции отношения сигнал/шум в зоне обнаружения при различных априорных значениях вероятности ложных обнаружений α: значения α: 1 – 5·10–4; 2 – 5·10–3; 3 – 2,5·10–2; 4 - 5·10–2
В табл. 13 приведены измеренные в максимуме пика минимальные отношения сигнал/шум qмин, при которых обнаружение по критерию (138) обеспечивает заданные величины δSон. Как следует из данных табл. 13, упрощенный алгоритм обнаружения целесообразно применять только при q ≥ 100.
Таблица 13. Минимальные значения qmin при заданных δSон и α = 10–3 в случае
обнаружения пика по критерию (138)
№ |
μ* |
qmin |
||
δSон = 0,1 % |
δSон = 0,5 % |
|||
п/п |
|
|||
1 |
1 |
1,5·104 |
1,7·103 |
|
2 |
2,5 |
1,3·103 |
3·102 |
|
3 |
∞ |
3,3·102 |
80 |
|
Сравнение с порогом может быть произведено для оценки амплитуды сигнала Aˆi , получаемой на i-й выборке, например, методом наименьших
квадратов (МНК). Значения обрабатываемого сигнала в этом случае представляются линейным уравнением:
|
yi k Ai Fk yб.сi . |
|
|
Пик считается обнаруженным, если выполняется неравенство : |
|
||
|
Ai |
Га , |
(139) |
|
|
||
A |
|
||
|
i |
|
|
где Га — некоторый порог. Оценка Ai и σAi (по-прежнему полагаем yб.с i либо равными нулю — скорректированный сигнал, либо известными) методом МНК приводит к уравнению:
151

|
|
|
m |
|
m |
|
m |
m |
|
|
|
A |
|
gk gk Fk yi k gk Fk gk yi k |
|||||||
|
i |
|
k m |
k m |
|
k m |
k m |
|
Га , |
|
|
Ai |
|
m |
|
m |
m |
|
m |
2 |
|
|
|
|
gk |
gk gk Fk2 |
gk Fk |
|||||
|
|
|
k m |
|
k m |
k m |
k m |
|
||
где gk — весовые коэффициенты, назначаемые обратно пропорционально дисперсии сигнала в k-й точке.
Принимая во внимание, что знаменатель в (139) — величина постоянная для данных условий работы алгоритма, учтем ее в величине порога. Тогда алгоритм обнаружения сведется к поиску выборки, для которой будет справедливо неравенство:
m |
m |
m |
m |
|
gk gk Fk yi k gk Fk gk yi k Г'а |
(140) |
|||
k m |
k m |
k m |
k m |
|
Сравнивая (140) с (133) при gk = 1, можно видеть, что функционалы в этих алгоритмах отличаются введением в псевдокорреляционную функцию поправки на некоторые средние значения сигнала. Это приводит к снижению чувствительности, но зато при yб.с = const позволяет не проводить предварительной коррекции базисного сигнала.
Для уменьшения влияния ширины пика на качество обнаружения веса в (140) назначаются не просто обратно пропорционально σ2ш, а с принудительным уменьшением к концам выборки.
Величина Г'а в (140) при длине выборки (2m + l) = Ent 2,6μ* найдена экспериментально: Га = 2. Это соответствует амплитуде минимального, еще обнаруживаемого пика:
Amin 1,7Га  yб.сi /μ* .
yб.сi /μ* .
6.3.2. Обнаружение пика по значениям производных сигнала.
Основным недостатком алгоритмов (137), (138) является ухудшение разрешения за счет расширения сигнала l на выходе фильтра и необходимость предварительной коррекции базисного сигнала. При использовании первой производной обнаружение нечувствительно к неизменному базисному сигналу. Критерием обнаружения является превышение первой производной сигнала υi некоторого порогового значения, например порога чувствительности дифференцирующего блока устройства обработки (селектора) s:
υi ≥ s |
(141) |
Возникающие при этом при гауссовой модели пика в отсутствие шумов погрешности можно оценить по кривым рис. 59.
152
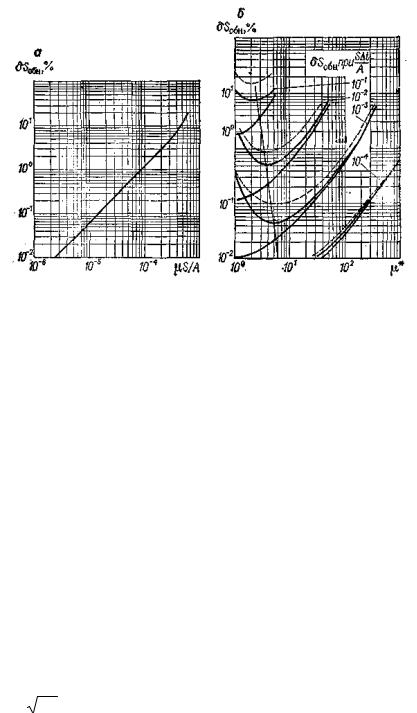
Рис. 59. Систематические погрешности δSобн при обнаружении пика по производной параметрическим селектором (а) и непараметрическим аналоговым (б, сплошные линии) и цифровым (б, пунктир) селектором
Для упрощения выкладок при нахождении оценки производной сигнала сложной формы методом максимального правдоподобия реальный пик заменяется на соответствующих участках параболами:
Fi t k y 0i bi k t ci k 2 t 2 . |
(142) |
Тогда задача сводится к оценке на основании результатов измерений хроматографического сигнала коэффициента bi при члене первой степени
параболы Fi и сравнении его с порогом. Для оценки параметра методом максимального правдоподобия необходимо приравнять нулю частную производную функции правдоподобия по параметру. Для случая белого шума имеем:
|
|
|
|
1 |
|
|
|
1 |
|
m |
2 |
|
|
|
|
|
|
|
exp |
|
|
yi k Fk |
|
||||
lnW (Y ) |
|
|
|
2 |
N |
|
|
2 |
ш k m |
|
|
||
i |
|
|
|
|
ш |
|
|
|
|
|
|
|
0, |
|
|
|
|
|
bi |
|
|
|
|
||||
bi |
|
|
|
|
|
|
|
|
|
|
|
||
где Fk определяется по (142).
Полученное уравнение будет содержать три неизвестных, возьмем производные и по параметрам y0i и ci. Система уравнений правдоподобия тогда примет вид (рассмотрим выборку с симметричными индексами):
m y j k y0i bi k t ci k 2 t2 0,
k m
m y j k y0i bi k t ci k 2 t2 k 0,
k m
153

m y j k y0i bi k t ci k 2 t2 k 2 0 .
k m
Решая эту систему относительно параметра bi и учитывая, что
|
|
|
m |
|
|
|
m |
|
|
|
|
|
|
k |
|
k 3 |
0; |
|
|||
|
|
|
k m |
|
|
|
k m |
|
|
|
|
|
|
k 2 |
m m 1 2m 1 , |
|
|||||
|
|
|
m |
|
|
|
|
|
|
|
|
|
|
k m |
|
|
|
3 |
|
|
|
|
|
|
m |
|
|
m |
m 1 6m3 9m2 |
m 1 , |
||
|
|
|
k 4 |
|
||||||
|
15 |
|||||||||
|
|
|
k m |
|
|
|
|
|
||
получим: |
|
|
|
|
|
|
|
|||
|
1 |
|
|
3 |
|
|
|
m |
|
|
bi |
|
|
|
|
|
kyi k , |
(143) |
|||
|
|
|
|
|
|
|
||||
|
t m m 1 2m 1 k m |
|
|
|||||||
что совпадает с уравнением дифференцирующего полиномиального фильтра (см. (97)). Это следовало ожидать, т.к. мы использовали при оценивании производной модель нормального некоррелированного шума и аппроксимацию пика полиномом второго порядка.
Пик считается обнаруженным, если выполняется критерий (аналогичный (141)):
ˆi bi Гп γп , |
(144) |
где γп — некоторый коэффициент.
Как и в случае обнаружения методом проверки гипотез (см. (132)), порог Гп включает в себя априорную информацию о хроматографическом сигнале. Величина συ в (144) рассчитывается по значениям ˆi в зонах
отсутствия пиков или по оценке шума σш. Для случая белого шума имеем (см. (101));
|
ш |
3 |
, |
|
t |
|
m m 1 2m 1 |
||
при симметричной индексации в выборке и
|
ш |
12 |
|
t |
|
N N 2 1 |
|
|
|
||
при несимметричной индексации (обработка в реальном времени). Вероятность обнаружения пика на q-й выборке Рпо q определяется
аналогично (134).
С целью упрощения реализации, что особенно важно в простых устройствах обработки, не имеющих развитой памяти (к ним относится большинство интеграторов), принимают в (143) т = 1. В этом случае оценка производной сводится к сравнению двух соседних значений сигнала. Критерий обнаружения (141) здесь примет вид
yi |
|
yi yi 1 |
s |
(145) |
|
t |
|||||
t |
|
|
|
Ошибки при обнаружении по (145) сильно зависят от величины шума и интервала квантования t (рис. 59). Рассмотрение графиков рис. 59, б
154
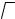
показывает, что минимум δSобн достигается примерно при одних и тех же μ = 3…5 (при Тс = 6μ это соответствует 20 — 30 опросов на пик).
Значительно повысить отношение сигнал/шум на выходе дифференцирующего фильтра можно, используя согласованный полиномиальный фильтр или фильтр с весовой функцией, соответствующей производной ожидаемого сигнала. Для достижения согласования необходимо корректировать в течение анализа ширину фильтра. Это можно сделать, воспользовавшись линейной зависимостью μ от t0. Поскольку эта зависимость линейна лишь приближенно, нет необходимости соблюдать строгую пропорциональность. Так изменение весов через 10 % изменения ширины пиков не дало существенных потерь в обнаружении, но значительно снизило объем вычислений. Используя адаптивный алгоритм и оценивая ширину пиков при помощи линейной регрессии, также можно оптимизировать ширину фильтра и добиться согласования при работе в реальном времени.
Наличие возможного дрейфа базисного сигнала приводит к необходимости коррекции получаемых оценок производной сигнала. При этом для измерения скорости дрейфа необходимо использовать фильтры с большими постоянными времени по сравнению с фильтрами, оценивающими производную сигнала для целей обнаружения (см. подразд. 6.2). Это является существенным недостатком алгоритмов (144).
Для того чтобы устранить влияние линейного дрейфа базисного сигнала, можно воспользоваться для обнаружения пика второй производной сигнала, вычисляя ее, например, с помощью полиномиального фильтра или модернизированного фильтра с весовой функцией (103). Согласованный фильтр позволяет эффективно сгладить вторую производную, что важно, т.к. она очень чувствительна к шуму. Однако, как указывалось в подразд. 6.1, такой фильтр значительно расширяет пики: при φопт =  5 разрешение ухудшается в (1 + φ2)0,5 раз. Поэтому, приходится выбирать φ < φопт, например φ = 1,4.
5 разрешение ухудшается в (1 + φ2)0,5 раз. Поэтому, приходится выбирать φ < φопт, например φ = 1,4.
Пик считается обнаруженным, если
|
|
* |
|
|
|
|
|
||
|
y" t γпп ш |
|
|
|
|
y" t 0 |
|
|
. |
|
|
|||
|
|
|
|
|
|
|
|
|
|
Здесь γпп — некоторый порог (γпп неразделенным, если:
(146)
= 2 … 5). Пик считается
а) во второй производной сигнала есть положительный минимум (больший γпп σ*ш ) между двумя отрицательными;
б) в отрицательной области y»(t) есть два минимума.
Модификацией алгоритма обнаружения пика по второй производной является обнаружение по превышению порога функционалом Qi, построенным на базе второй производной модели сигнала F»k:
155

|
m |
|
|
|
Qi |
F"k yi k |
Гпп . |
(147) |
|
k m |
||||
m |
||||
|
|
|
||
|
F"k 2 yi k |
|
|
|
|
k m |
|
|
Порог Гпп для обеспечения высокой чувствительности обнаружения принимают равным 2, но при этом необходимо дополнительно проверить, не произошло ли ложное обнаружение (например, по ширине зоны постоянства знака Qi в районе его максимума). Если принять Гпп ≥ 5, то дополнительной проверки обычно не требуется. Максимум отношения Qi/σQi. зависит от отношения уб.с/А (А —амплитуда пика) и соотношения ширины модели и пика φ. При уб.с/А = 0,01…1 значение φopt = 4,5…2,5 и стремится к 2,3 при дальнейшем увеличении уб.с/А (для хроматографии малореальный случай). Это дает для Аmin оценку:
A 0,92Г |
пп |
y |
б.с. |
/μ* |
min |
|
|
Однако «хвосты» Q ухудшают разрешение и маскируют малые пики. Поэтому приходится брать φ < φopt. Если принять φ = 1, то Аmin возрастает в 1,5 раза.
6.3.3. Сравнительный анализ алгоритмов обнаружения
Качество алгоритмов обнаружения было исследовано методом математического моделирования. При этом основное внимание было уделено наиболее перспективным алгоритмам (133) и (144) при оценке bi по (143). Моделирующая программа состояла из трех частей: модели сигнала, модели собственно алгоритма обнаружения и блока статистической обработки результатов, связанных организующей программой.
При использовании алгоритма (133) обнаружение пика возможно вплоть до отношений сигнал/шум q = 4 (для μ* = 8, Гп = 3σl, N = 2т + 1 =5), однако при потерях площади δSобн ≈ 8,7 %. Увеличение длины выборки вдвое (μ * = 4, N = 5) уменьшает δSобн до 7 %. Обнаружение по алгоритму (144) при тех же условиях дает, как и следовало ожидать, худшие результаты: в первом случае
— δSобн = 11 % при q = 8, во втором — тоже δSобн = 11 %, но уже при q = 4. Вероятность пропуска пика при использовании алгоритма (144) (µ* = 8,
Гп = 3σl, N |
= 5) при |
уменьшении q |
резко возрастает: |
Рпр|q=20 = 0,0; |
Рпр|q=8 =8 = 0,3; |
Рпр|q=4 = |
0,85. Критерий |
(133) при тех же |
условиях обес- |
печивает практически полное обнаружение. Вероятность ложных обнаружений при действии помех не зависит от q, но несколько выше ожидаемой. Если при отсутствии помех Рл.о = 0, то при вероятности их появления Рп = 0,3 значение Рл.о может достигнуть 60 % при прочих равных параметрах (µ* = 4, N = 5, q = 4).
Уменьшение длины выборки (окна фильтра) ухудшает характеристики обнаружения за счет уменьшения энергии сигнала, попадающего в окно, и
156

ухудшения сглаживания получаемых оценок (рис. 60). При постоянном N уменьшение длины выборки вдвое (с N t = 2,5µ до N t = 1,25µ) вызывает увеличение δSобн по алгоритмам (133) и (144) с 1 до 4 % и 1,2 до 11 % соответственно (q = 8) и резкое возрастание Рл.о при наличии помех (с Рл.о = 0,05 до Рл.о = 0,65). Еще более влияет на параметры обнаружения изменение длины выборки за счет изменения ее объема. Так, при q = 8, µ* = 4 и N = 9 значение δSобн = 0,2 %, при N = 5 оно возрастает до 1 % и при N = 3 до 7,8 % (алгоритм (133), т.е. меняется значительно сильнее N t. Алгоритм (144) дает аналогичные результаты: δSобн| N=9= 0,1 % и δSобн| N=5= 12,7 %. Уменьшение N резко увеличивает пропуски пиков.
Рис. 60. Зависимостqmin |
j |
N t |
при различных Рл.о = α и µ* (изменение |
||||
|
|||||||
|
|
|
|
T |
|
|
|
|
|
|
δSобн.=0,1…1,0 %): |
||||
|
|
|
|
|
|
|
|
|
Кривые |
|
|
|
α |
µ* |
|
|
1 |
|
|
5·10-3 |
2,5 |
|
|
|
2 |
|
|
2,5·10-2 |
2,5 |
|
|
|
3 |
|
|
5·10-2 |
2,5 |
|
|
|
4 |
|
|
5·10-3 |
10 |
|
|
|
5 |
|
|
2,5·10-2 |
10 |
|
|
|
6 |
|
|
5·10-2 |
10 |
|
|
Превышение N t величины 4µ приводит к значительному (примерно в 1,5 раза) расширению пиков и затруднениям при реализации обработки в реальном времени, с другой стороны, снижение N t менее 1µ значительно ухудшает характеристики обнаружения.
157

Вариации N при постоянной длине выборки N t влияют на обнаружение значительно меньше за счет некоторого изменения сглаживающего эффекта. Таким образом, можно рекомендовать выбирать N t в диапазоне
1,5μ N |
3μ. |
(148) |
Увеличение вероятности появления помехи Рп сдвигает оценки времени начала пика tˆн в сторону более раннего обнаружения.
Относительно высокая чувствительность рассматриваемых алгоритмов к помехам при малых объемах выборок N ограничивает нижний предел N величинами
N >5…9 |
(149) |
Поскольку при увеличении N выше 9 сглаживающий эффект нарастает примерно пропорционально  N , а величина qвых — еще медленнее (за счет искажения пиков — см. подразд. 6.1), целесообразно ввести предварительную фильтрацию помех.
N , а величина qвых — еще медленнее (за счет искажения пиков — см. подразд. 6.1), целесообразно ввести предварительную фильтрацию помех.
Сравнение двух методов фильтрации — усреднением и медианой (105) по 3 и 5 точкам — показало, что при отсутствии помех Рп = 0 параметры обнаружения пика в случае использования усреднения несколько лучше. При возрастании вероятности появления выбросов до Рп = 0,3 фильтрация по медиане эффективнее фильтрации усреднением (табл. 14).
Таблица 14. Погрешности оценок момента начала пика tн = t0 — 3µ ха = 3; N = 9; µ* =
4; q = 8; Pп = 0,3
Алгоритм |
Оценка |
Фильтрация по g точкам (с – среднее, м – медиана) |
||||||||||
g = 1 |
g = 3с |
g = 3м |
g = 5с |
g = 5м |
||||||||
|
|
|
|
|
|
|
||||||
|
|
tˆн |
|
–0,130 |
0,144 |
0,025 |
0,275 |
0,012 |
||||
(133) |
|
|
μ |
|||||||||
|
|
|
|
|
|
|
||||||
|
|
tн |
|
0,640 |
0,552 |
0,272 |
0,334 |
0,151 |
||||
|
|
μ |
||||||||||
|
|
|
|
|
|
|
|
|
||||
|
Pл.о |
0,200 |
0,050 |
0,000 |
0,000 |
0,000 |
||||||
|
|
tˆн |
|
–0,520 |
–0,500 |
–0,200 |
–0,380 |
–0,080 |
||||
(144) |
|
|
μ |
|||||||||
|
|
|
|
|
|
|
||||||
|
|
tн |
|
0,776 |
0,730 |
0,458 |
0,502 |
0,244 |
||||
|
|
μ |
||||||||||
|
|
|
|
|
|
|
|
|
||||
|
Pл.о |
0,300 |
0,25 |
0,000 |
0,050 |
0,050 |
||||||
Влияние длины и объема выборки в районе рекомендуемых значений на оценку tˆн (tˆн измерено от центра пика t0) в зависимости от q при Рп = 0,3 и фильтрации медианой g = 5 иллюстрируется рис. 61
Наличие в канале сигнала звеньев с большими постоянными времени τ,
158

приводящими к коррелированности шума, ухудшают характеристики обнаружения (хотя и не приводят к сдвигу оценок их оптимальных параметров).
Рис. 61. Зависимости оценки tˆμн f (log2 q) для обнаружения по алгоритмам
(133) и (144) (пунктир) при xα = 3 Рп = 0,3, предварительной фильтрации по медиане с g = 5 и параметрах: N = 5, µ* = 2 (NΔt = 2,5 µ – кривые 1); N = 5, µ* = 4 (NΔt = 1,25 µ – кривые 2); N = 5, µ* = 8 (кривые 3); N = 9, µ* = 4 (NΔt = 2,25 µ – кривые 4); N = 3, µ* = 4 (кривые 5)
Зависимости оценок начала пика от постоянной времени τ блоков на входе устройства обработки (источник помех типа выбросов находится после этих блоков) показаны на рис. 62 для рекомендуемой области параметров и обнаружения по алгоритму (133).
Рис. 62. Зависимости оценки tˆμн f (τ) при обнаружении по алгоритму (133) и
следующих параметрах алгоритма и сигнала (фильтрация по 5 точкам медианой и усреднением (пунктир); µ* = 4):
159
Кривая |
q |
Рп |
N |
1 |
20 |
0 |
9 |
2 |
20 |
0,3 |
9 |
3 |
20 |
0 |
5 |
4 |
20 |
0,3 |
5 |
5 |
8 |
0 |
9 |
6 |
8 |
0,3 |
9 |
7 |
8 |
0 |
5 |
8 |
8 |
0,3 |
5 |
Из рис. 62 следует, что предварительная фильтрация медианой практически устраняет зависимость характеристик обнаружения от выбросов
(см. кривые 1 и 2, 3 и 4, 5 и 6, 7 и 8), хотя дисперсии σt2 при наличии помехи
н
возрастают.
Еще труднее получить качественное обнаружение при действии источника помех в канале сигнала до звеньев со значительными постоянными времени (например, в канале газа-носителя и тому подобных точках хроматографического тракта), а также при действии электрических сосредоточенных помех. В этом случае предварительная фильтрация хотя и целесообразна, но значительно менее эффективна, тип фильтра не оказывает существенного влияния на характеристики обнаружения.
Таким образом, алгоритм (133) обеспечивает по сравнению с алгоритмом (144) более точные результаты, хотя и требует коррекции базисного сигнала. Качество обнаружения определяется длиной и объемом (в несколько меньшей степени) выборки, которые целесообразно назначать, исходя из условия (148) и (149). При этом Fk находится по значениям модели сигнала в зоне выборки при ее совмещении с началом пика.
Следует помнить, что при малых выборках ухудшаются условия обнаружения, при больших — сильно расширяются сигналы на выходе фильтра, вычисляющего критерий (133); это ухудшает разрешение. Расширять выборку имеет смысл для уточнения границ пика после их предварительной оценки.
Целесообразно во всех случаях применение небольшой предварительной фильтрации по медиане, например по 5 точкам.
Все это позволяет получить с помощью алгоритма (133) качественное обнаружение (δSоб. < 0,1 … 0,5 %) вплоть до значений q = 8 при белом шуме без выбросов; q = 20 при обнаружении сигнала в белом шуме или коррелированном (τ ≤ µ) шуме с выбросами при Рп ≤ 0,3; q > 20 при наличии в сигнале еще и сосредоточенных помех.
Для увеличения надежности обнаружения можно потребовать многократного (ψ раз; ψ = 2 … 4) выполнения критерия обнаружения.
160