

Учебное пособие 800628
.pdfДля процесса моделирования выбрана тестовая выборка данных работы |
||||||||||||||||
распределенной сетевой структуры на примере локальной вычислительной сети. Выборка |
||||||||||||||||
сделана для граничных условий каждого типа данных (видео, текст). Граничные условия |
||||||||||||||||
устанавливают ограничения на наличие свободной широты канала для каждого типа данных. |
||||||||||||||||
Моделирование проведено на тестовой выборке, приближенной к каждой из выбранных |
||||||||||||||||
границ. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
от |
0,4 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
(в |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Оценка измения состояния узла |
долях) на прогнозируемом этапе текущего |
0,2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0,0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
1 |
3 |
5 |
7 |
9 |
11 |
13 |
15 |
17 |
19 |
21 |
23 |
25 |
27 |
29 |
||
-0,2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
-0,4 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
-0,6 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
-0,8 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Номер цикла работы узла |
|
|
|
|
|||||
|
|
|
|
|
|
|
Монте-Карло |
прогноз АИНС |
|
|
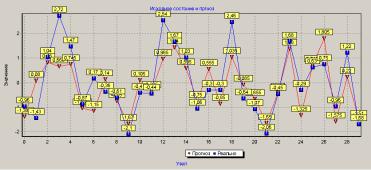
Рисунок 3 – |
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Реализации состояния узла, полученного с помощью моделирования, и прогнозом |
||||||||||||||||
|
|
|
|
|
|
(фрагмент для границы 0,2) |
|
|
|
|||||||
Если прогнозное состояние узла на графике меньше нуля, то в дальнейшей работе |
||||||||||||||||
состояние оцениваемого узла ухудшится (прогноз -0,2 означает двадцати процентное |
||||||||||||||||
ухудшение состояния узла на прогнозируемом цикле); |
|
|
|
|
|
|
||||||||||
Если - больше нуля, то состояние сохраняется такое же; |
|
|
|
|||||||||||||
Если - больше единицы, ожидается улучшение состояния узла на указанное значение |
||||||||||||||||
минус единица ( прогнозное значении 1,1, означает десяти процентное улучшение состояния |
||||||||||||||||
на прогнозируемом этапе.) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
Таблица 1 – Сравнение результатов моделирования с результатами прогнозирования |
||||||||||||||||
|
|
|
|
|
|
|
по АИНС |
|
|
|
|
|
|
|||
|
Постоянный активный поток (активная передача) |
Постоянный активный поток (активная передача) |
Высокая загруженность (аудио-видео) |
Высокая загруженность (аудио-видео) |
Транзитный поток (сервисные данные) |
Транзитный поток (сервисные данные) |
Малая загруженность (текст) |
Малая загруженность (текст) |
Незначительная загруженность |
Занятость узла (в |
|
|
|
|
|
|
|
|
|
долях) |
0,1 |
0,3 |
0,2 |
0,5 |
0,4 |
0,8 |
0,7 |
0,9 |
1 |
СОО |
0,27 |
0,85 |
1,65 |
2,02 |
2,36 |
0,61 |
0,21 |
1,30 |
1,55 |
Прогноз АИНС |
0,35 |
0,55 |
1,19 |
0,48 |
0,90 |
0,77 |
0,52 |
1,44 |
0,30 |
В таблице 1 приведено сравнение прогноза состояния узла с использованием АИНС и результатов моделирования с помощью метода Монте-Карло. Для получения представленных в таблице данных произведен расчет средне-относительной ошибки (СОО). Исходя из полученных результатов видно, что при загрузке узла полностью (0,7; 0,9; 1) и при незначительной загрузке (01; 0,2; 0,3) численное моделирование показывает наиболее близкие результаты к прогнозу АИНС. При средней загрузке результаты моделирования
41
показывает значительное расхождение с результатами прогнозирования нейронной сети. Это вызвано тем, что транзитный поток данных не однороден.
Прогноз считается удовлетворительным, если средне-относительная ошибка не превышает значение в 10 единиц. Проведенное моделирование по методу Монте-Карло показывает, что применение АИНС возможно для автоматизации прогнозирования состояния распределенной сетевой структуры.
Реализация практических результатов работы модели представлены в программном комплексе, позволяющим смоделировать состояние узла на основе собранных данных о работе сетевой структуры и заданных граничных условий.
Программа предусматривает поэтапную процедуру моделирования на основе ранее выявленных на предыдущих циклах работы характеристик, где в каждой из них учитываются факторы, влияющие на работу сетевой структуры.:
-на первом этапе программа обращается к базе данных, где хранятся характеристики предыдущих циклов работы, причем выборка производится только из тех данных, которые были получены при работе сетевой структуры с определенным типом данных;
-на втором этапе рассчитываются изменяющиеся технические параметры выбранного узла, т.е. те, которые описывают его техническое состояние в соответствии с выбранным пользователем набором данных (минимально или максимально допустимые границы канала);
-на третьем этапе программа производит расчет программных факторов, влияющих на работу узла; для этого используются характеристики, взятые из базы данных, для выбранного пользователем каждого типа данных;
-на четвертом этапе программа производит окончательный расчет модели и выводит пользователю график возможных изменений состояния узла.
Рисунок 4. Пример графика прогнозируемого изменения состояния узла Программный комплекс на конечном этапе работы (представлен на рисунке 4),
отображает прогнозное состояние узла и приводит данные в сравнении с его реальным состоянием на этапе работы (если они есть в базе данных).
Библиографический список
1.Т.В. Киселева, А. В. Грачев, О способе управления распределенной сетевой структурой и оценки её работы // Моделирование и наукоемкие информационные технологии в технических и социально-экономических системах : труды "IV Всероссийской научно-практической конференции (с международным участием). В 2 ч., Ч2. - Новокузнецк, 2016. – С. 188–192.
2.А. В. Грачев, Т.В. Киселева, Моделирование состояния распределенной сетевой структуры в задачах маршрутизации // Информационно-телкоммуникационные системы и технологии (ИТСИТ-2017): материалы Всероссийской научно-практической конференции. 2017. - Кемерово, 2017. – С. 338–340.
42

УДК 616.314
АЛГОРИТМ ДИАГНОСТИКИ ОНКОЛОГИЧЕСКИХ ЗАБОЛЕВАНИЙ МОЛОЧНЫХ ЖЕЛЕЗ С ПРИМЕНЕНИЕМ АППАРАТА НЕЧЕТКИХ МНОЖЕСТВ
В.И. Гребнев, А.В. Зенович Волгоградский государственный университет
Рассматривается задача диагностики заболеваний молочных желез по данным комбинированной (радио и инфракрасной) термометрии. Разработан алгоритм диагностики заболеваний парных органов на основе нечетких множеств. Проведены вычислительные эксперименты с целью подбора параметров алгоритма. В качестве критерия эффективности алгоритма взято среднее геометрическое его специфичности (доли правильно диагностированных здоровых) и чувствительности (доли правильно диагностированных больных). При оптимальных значениях параметров эффективность алгоритма составляет 75%. Работа выполнена в рамках группового проекта, посвященного созданию экспертной системы экспресс-диагностики заболеваний молочных желез.
ALGORITHM OF DIAGNOSTICS OF ONCOLOGICAL DISEASES OF MAMMARY GLAND WITH APPLICATION OF THE FUZZY SETS APPARATUS
V.I. Grebnev , A.V. Zenovich
Volgograd State University
In this work, we consider the problem of breast diseases diagnosis according to combined (radio and infrared) thermometry. We implemented a new algorithm for diagnosis using fuzzy sets. We’ve run some computational experiments to select parameters of the algorithm. Criterion for effectiveness of an algorithm is the geometric mean of its specificity (share of correctly diagnosed healthy ones) and sensitivity (share of correctly diagnosed patients). The efficiency of our algorithm is 75% at optimal values of the parameters. The work is a part of a group project on the creation of an expert system for rapid diagnosis of breast diseases.
У женщин самым распространенным онкологическим заболеванием является рак молочных желез. Современная медицина способна успешно лечить опухоли размером 5-7мм, тогда как средний размер опухолей, выявляемых при диагностике, почти в два раза больше. Решением данной проблемы может стать метод комбинированной термометрии [1] активно развивающийся в последнее время. Так как онкологические аномалии сразу вызывают температурные изменения, метод комбинированной термометрии способен помочь врачу обнаружить опухоль на ранней стадии заболевания. Помочь ему в этом может отечественный прибор РТМ-01-РЭС, который проводит измерение температур на поверхности кожи и на глубине до 7 см.
Однако считать показания, а что более важно, правильно их интерпретировать способен лишь врач-маммолог высокой квалификации, предварительно
© Гребнев В.И., Зенович А.В., 2018
43
прошедший специальную подготовку, что осложняет применение данного метода при профилактических осмотрах.
Последние несколько лет коллективом специалистов из ВолГУ под руководством д.ф.-м.н. Лосева А.Г. ведется разработка консультативной информационной системы [3], которая могла бы предложить врачу общей практики предварительный диагноз и его обоснование. Главной частью системы является блок принятия решений, состоящий из различных алгоритмов диагностики (на основе нейросетей, на основе генетических алгоритмов, на основе одномерных и двумерных характеристических признаков и т. д.). В данной работе рассматривается реализация одного из алгоритмов диагностики с применением аппарата нечетких множеств.
Диагностика начинается с измерений поверхностных и глубинных температур в двух опорных точках, девяти точках на каждой молочной железе и двух точках в аксиллярных областях [1]. Таким образом, каждой пациентке ставится в соответствие вектор из 44-х температур, по которому проводится предварительная диагностика. При этом известен ряд качественных медицинских признаков ([1], [4], [5]), описывающих нехарактерное для здорового пациента состояние. Такими признаками, например, являются:
-повышенная термоассиметрия между одноименными точками (областями) молочных желез
-повышенный разброс температур между различными точками в пораженной молочной железе
-соотношение кожной и глубинной температуры
и другие.
Для каждого качественного признака можно построить достаточно большой набор моделирующих функций ( ), зависящих от вектора температур. Например, при анализе повышенной термоассиметрии можно брать разность температур между одноименными точками, средние арифметические разностей температур между различными областями, разницу температур сосков, дисперсию разностей температур между одноименными точками молочной железы и т.п. Далее по моделирующей функции строится нечеткое множество, которое будет использовано в алгоритме диагностики.
Алгоритм построения нечеткого множества больных по моделирующей функции ( )заключается в следующем [2]. Пусть множество значений функции f представляет собой промежуток [m; M]. Выделяем промежутки [m; a] и [b; M], в которых содержатся значения моделирующей функции только больных пациентов. На указанных промежутках функцию принадлежности нечеткому множеству больных считаем равной 1. Оставшееся множество [a; b] разбиваем
44

на значимые промежутки, в каждом из которых не меньше 10 % МЖ из класса «Больные» и 10% из класса «Здоровые». На каждом промежутке вычисляем долю здоровых и долю больных пациентов. Функцию принадлежности нечеткому множеству больных в центре заданного промежутка вычисляем по формуле µ = ( ). Далее методом наименьших квадратов аппроксимируем
полученный набор точек. Проводились вычислительные эксперименты с целью оптимального подбора аппроксимирующей функции, в результате был выбран многочлен 4-й степени.
Алгоритм классификации зависит от вектора параметров = ( , , , , ) и функций принадлежности ( ). Параметры подбираются в процессе вычислительных экспериментов с целью обеспечения наибольшей эффективности алгоритма. Для каждого пациента высчитываются значения( ), где = 1,5− и сортируются в порядке убывания. Далее происходит классификация пациентов по принципу:
1.если i ( ) ≥ , то относим пациента к группе больных;
2.иначе пациент здоров.
Критерием эффективности D алгоритма является среднее геометрическое чувствительности – доли верно диагностированных больных и специфичности
– доли верно диагностированных здоровых.
Было написано приложение, состоящее из двух независимых модулей. Первый обеспечивает построение нечеткого множества по заданной моделирующей функции. Второй модуль выполняет функции классификатора и ставит первичный диагноз пациенту. В рамках вычислительных экспериментов был рассмотрен один из минимизирующих наборов из 26 наиболее информативных признаков. Подбор наиболее эффективной пятерки функций осуществляется путем полного перебора всех возможных комбинаций при заданном векторе β. Далее осуществляется подбор вектора
= ( , , , , ). Необходимое условие ≥ . Стартовый = (0.65,0.6, 0.55, 0.5,0.45) и с шагом 0.025 меняются значения βi пока β1 не станет
равно 1. Это означает выполнение характеристического признака. Таким образом, в алгоритме удалось получить значение D до 0,754. Результаты вычислительных экспериментов представлены в таблице 1.
45

Набор признаков |
( , , , , ) |
Специфичность |
Чувствительность |
D |
P1 |
(0.95,0.8,0.675,0.65,0.6) |
0.650 |
0.852 |
0.754 |
|
|
|
|
|
P2 |
(0.95,0.8,0.675,0.6,0.55) |
0.678 |
0.823 |
0.747 |
|
|
|
|
|
P3 |
(0.775,0.65,0.6,0.55,0.5) |
0.554 |
0.941 |
0.722 |
|
|
|
|
|
P4 |
(0.7,0.65,0.6,0.55,0.5) |
0.623 |
0.852 |
0.729 |
|
|
|
|
|
Таблица 1
Библиографический список
1.Веснин С.Г. Современная микроволновая радиотермометрия молочных желез / Веснин С.Г., Каплан М.А., Авакян Р.С.// Опухоли женской репродуктивной системы.
– 2008. – № 3. – С. 28-33.
2.Зенович А. В. Алгоритмы классификации заболеваний парных органов на основе нейросетей и нечетких множеств /Зенович А. В., Гребнев В. И., Примаченко Ф. Г.// Вестник Волгоградского государственного университета. Серия 1, Математика. Физика. — 2017. — № 6 (37)— C. 26–37.
3.Зенович А.В. Алгоритмы принятия решений в консультативной интеллектуальной системе диагностики молочных желез / Зенович А.В., Глазунов В.А., Опарин А.С., Примаченко Ф.Г. // Вестник Волгоградского государственного университета. Серия 1, Математика. Физика. – 2016. - №6 (37). – С.141-151.
4.Лосев А.Г., Хоперсков А.В., Астахов А.С., Сулейманова Х.М. Проблемы измерения и моделирования тепловых и радиационных полей в биотканях: анализ данных микроволновой термометрии. // Вестник Волгограского. государственного университета. Серия 1, Математика. Физика. 2015. №6. С. 31–71.
5.Лосев, А.Г. О некоторых характерных признаках в диагностике патологий молочных желез по данным микроволновой термометрии / А.Г.Лосев, Е.А. Мазепа, Т.В. Замечник // Современные проблемы науки и образования. -2014.-№6.-С.254
46

УДК 658.012.2:629.472
АЛГОРИТМЫ СОСТАВЛЕНИЯ РАСПИСАНИЯ ОБСЛУЖИВАНИЯ ТО-2 ЛОКОМОТИВОВ В ДЕПО
Е.М. Гришин, А.А. Лазарев МГУ им. М. В. Ломоносова
Представлены несколько эвристических алгоритмов для составления расписания обслуживания локомотивов различных типов в депо, состоящем из трех специально оборудованных смотровых канав. Вычислительные эксперименты показали, что абсолютная погрешность лучшего алгоритма составляет менее 1% и слабо зависит от количества локомотивов, а время его работы в несколько раз меньше оптимизатора IBM IlogCPLEX.
ALGORITHMS OF SCHEDULING OF LOCOMOTIVES’ MAINTENANCE TS-2 IN A
DEPOT
E. Grishin, A. Lazarev
Lomonosov Moscow State University
Тhis paper is devoted to several heuristic algorithms for scheduling maintenance of locomotives (three types) in the depot, consisting of three observation ditches. These algorithms give opportunity to set priority of service requirements by various permutations. Computer experiments show that the proposed algorithms provide scheduling for less computer time with small errors (less than 1%) compared to standard optimizers as IBM IlogCplex.
Каждому локомотиву необходимо обеспечить периодический ремонт в пункте технического обслуживания локомотивов (ПТОЛ) во избежание поломок и сбоев в работе. Один из видов технического обслуживания ТО-2 регулируется пробегом или временем от последнего ремонта и реализуется в ПТОЛ. Каждый ПТОЛ состоит из специально оборудованных смотровых канав (слотов), на которых может быть обслужен локомотив. Локомотивы могут прибывать в депо в произвольные моменты времени. Если все слоты депо заняты, образуется очередь локомотивов. Задача работы состоит в определении последовательности обслуживания прибывших локомотивов.
Имеется ряд условий, накладывающих ограничения на работу депо:
в каждый момент времени на слоте может находится только один локомотив;
все локомотивы должны быть обслужены;
локомотив не может покинуть слот после начала обслуживания, пока не будет завершено его обслуживание;
локомотив может быть обслужен только один раз.
Необходимо построить расписание работы ПТОЛа. Построенное расписание должно соответствовать минимальному суммарному времени ожидания обслуживания локомотивов с учетом их значимости (веса), времени прибытия и длительности обслуживания в депо.
Имеются депо с тремя слотами и три типа локомотивов с различными временами обслуживания. Множество всех локомотивов – = , где каждое подмножество, , соответствует одному из типов локомотивов. Всего локомотивов n = | | .
©Гришин Е.М., Лазарев А.А., 2018
47
Поставим каждому локомотиву в соответствие номер ", " = 1,2,...,n.
Локомотивы множества N1 могут обслуживаться на любом слоте депо. Локомотивы множества N2 могут обслуживаться на двух слотах (№2 и №3), а локомотивы множества N3 могут обслуживаться только на одном слоте депо (№3). Каждый локомотив " характеризуется набором параметров:
#$ — время прибытия локомотива в депо;
%$ — время обслуживания локомотива в депо;
&$ — значимость (вес) локомотива.
Пусть существует расписание ' = ' ' ' , где ' , ' , ' — расписания работы |
||
слотов депо с №№ 1, 2, 3, соответственно. Через ($(') |
обозначим время |
завершения |
обслуживания локомотива "при расписании '. |
|
|
Введем функцию суммарного взвешенного простоя: |
|
|
) (') = * &$+($(') − %$ − #$,, |
(1) |
|
$ - . |
локомотива " и |
|
где +($(') − %$ − #$, — время между прибытием |
началом его |
|
обслуживания.
Рассмотрим случай, когда все времена #$ = 0, " . Заметим, что &$%$ = 01234," . Следовательно, ∑$ - . &$%$ = 01234. С учетом этого условия введем целевую функцию, которую надо минимизировать для построения расписания с минимальным суммарным взвешенным простоем:
)(') = *&$($('). |
|
(2) |
$ . |
|
|
В [1] решена задача распределения требований на одном приборе. Требования |
||
(локомотивы)должныобслуживатьсявпорядкенеубывания величин |
78 |
, " . |
|
98 |
|
Для одного и двух идентичных приборов задача распределения требований с минимальным суммарным взвешенным простоем полиномиальное разрешима. В [2] показано, что для трех и более приборов задача в общем случае NP-трудна.
Случай динамического составления расписания для трех идентичных приборов решен в [3]. Авторы доказывают, что как только прибывает требование с более высоким приоритетом необходимо прервать требование с наименее низким приоритетом.
Алгоритм 1
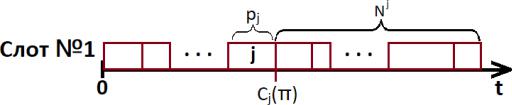
Пусть есть некоторое расписание '. В момент времени ($(') на слоте 1 (без ограничения общности) завершается обслуживание локомотива ". Тогда $ — множество локомотивов, стоящих в очереди на обслуживание после него. Ниже на рис.1 представлено схематическое изображение расписания.
Рис. 1. Схематическое изображения расписания для слота №1
48
Посчитаем вклад локомотива " в значение целевой функции при расписании ': |
|
:$(') = &$($(') + %$ * &< , |
(3) |
< .8 |
|
где первый член связан с обслуживанием текущего локомотива ", а второй член — с |
|
обслуживанием локомотивов множества $, стоящих в очереди. |
|
Очевидно, что для минимизации целевой функции (2) необходимо составить расписание ', |
|
при котором сумма всех параметров :$(') будет минимальной: |
|
* :$(') = > 2. |
(4) |
$ . |
|
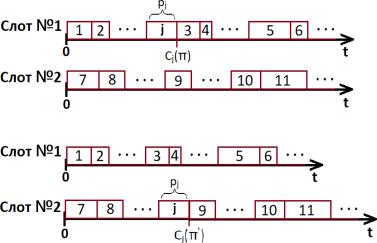
Существование расписания означает, что для каждого слота депо определена последовательность обслуживания локомотивов. Изменение расписания, при котором последовательности обслуживания локомотивов остались прежними за исключением перестановки одного члена (локомотива ") одной из последовательностей на другое место этой или другой последовательности, будем называть перестановкой для расписания ' (см. рис. 2). Очевидно, что с помощью перестановок из любого расписания ' можно получить любое другое расписание '?.
При перестановке локомотива " в расписании ' может измениться значение :$('). Введем
разницу этих значений при расписаниях ' и '?:
@:$('?) = :$(') − :$('?). (5)
Если совершать перестановки, удовлетворяющие условию |
(6) |
@:$('?) > 0, |
Рис. 2. Пример перестановки для депо
можно получить локальный (или абсолютный) минимум значений целевой функции. Для сокращения времени работы алгоритма можно наложить ограничения на
совершаемые перестановки.
Сначала найдем последовательности номеров локомотивов, которые соответствуют минимальному взвешенному простою для каждого набора , , . Согласно статье [1] все локомотивы должны быть обслужены в порядке неубывания величин 7988 , " . Поэтому для
каждой перестановки локомотива " соответствует не больше двух мест в расписании, которые могут удовлетворять условию (6). Выполняя перестановки, которые соответствуют минимальному возможному значению @:$('?), " можно получить расписание, соответствующее минимуму (локальному или абсолютному) значения целевой функции (2).
49
Алгоритм 2
Расставим все локомотивы на слоте №3 в порядке неубывания величин 7988 , " .
Локомотивы множеств , будем переставлять на слот №2, если при этом время окончания их обслуживания уменьшится. Аналогичным образом локомотивы множества переставим на слот №1.
Если на слоте №3 после перестановок остались локомотивы с большим приоритетом (&$⁄%$) начало обслуживания которых начинается позже локомотивов с меньшим приоритетом, то вернем на слот №3 все локомотивы с меньшим приоритетом и более ранним временем начала их обслуживания. Продолжим совершать эти операции, пока при перестановке локомотивов времена окончания их обслуживания будут уменьшаться.
Алгоритм 3
Расставим все локомотивы на слоте №3 в порядке неубывания величин 7988 , " . После всех перестановок (аналогичных алгоритму 1) локомотивы на слотах должны удовлетворять условию 7988 , " . То есть для любых двух локомотивов определена взаимоочередность их
обслуживания. Тогда методом ограниченного перебора можно найти расписание, которое будет
соответствовать минимуму целевой функции (2).
Утверждение 2. Данный алгоритм находит точное решение не более чем за 3|. |2|. | операций.
Доказательство. Локомотивы множества могут быть обслужены на любом слоте, поэтому каждому локомотиву соответствует 3 положения в расписании (по одному на каждом слоте). Так как всего локомотивов этого множества 2 = | |, то вариантов их расстановки 3C . Аналогично для множества 2C вариантов их расстановки, где 2 = | |. Следовательно, за 3C 2C операций можно найти расписание, соответствующее минимуму целевой функции (2).
Алгоритм 4
С помощью алгоритма 3 можно найти точное решение. Однако, если количество элементов множеств и достаточно велико, то количество операций для поиска оптимального расписания будет слишком большим. Пусть можно совершить не более 3a или 2b операций.
Тогда расставим все локомотивы на слоте №3 в порядке неубывания величин 7988 , " .
Будем применять алгоритм 3 для первых n1 локомотивов, среди которых не более a локомотивов множества и не более b локомотивов множества . Далее применим алгоритм для следующих n2 локомотивов, среди которых неболее a локомотивов множества N1 и не более bлокомотивов множества N2. И такдалее, покавсе локомотивы не будут перебраны.
Данный алгоритм составляет оптимальное расписание для каждого рассматриваемого подмножества за разумное время, но в нем никак не учитывается взаимосвязь между разными подмножествами.
Сравнительный анализ
Первый и второй алгоритмы являются эвристическими. Их эффективность доказана не была. Алгоритм 4 является модернизацией алгоритма 3 с учетом вычислительных способностей
50