

6 Расчет доверительного интервала для прогноза
Доверительный
интервал для прогнозируемого отклика
y
записывается в виде:
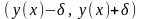 ,
где
,
где
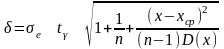 ;
;
= 1,798 – стандартная ошибка (см. табл. 1.15);
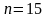 – количество
наблюдений;
– количество
наблюдений;
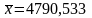 – среднее
значение фактора (см. табл. 1.14);
– среднее
значение фактора (см. табл. 1.14);
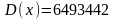 – дисперсия
выборки (см. табл. 1.14);
– дисперсия
выборки (см. табл. 1.14);
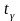 – критическая
точка распределения Стьюдента.
– критическая
точка распределения Стьюдента.
Чтобы
найти
,
выбирают команду «Вставка функции»,
категорию «Статистические», функцию
Стьюдраспобр.
Вводят требуемую вероятность (0,05) и
число степеней свободы (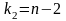 ).
Получают для однофакторной регрессии
(при n
=15)
= 2,16.
).
Получают для однофакторной регрессии
(при n
=15)
= 2,16.
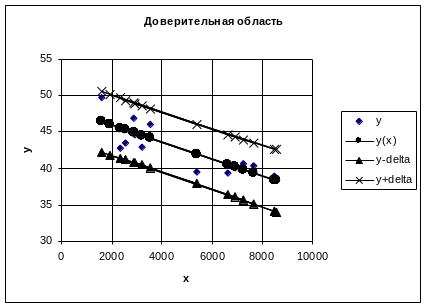
7 Построение доверительной области для прогноза
Доверительная
область – совокупность доверительных
интервалов. Строят точечную диаграмму:
по оси абсцисс – значения фактора х,
по оси ординат – значения отклика y,
расчетных значений y(x)
и границ доверительных интервалов
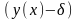 ,
,
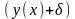 .
Получают диаграмму:
.
Получают диаграмму:
8 Расчет максимального % ошибки прогнозирования
Максимальный % ошибки прогнозирования рассчитывается по формуле:
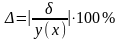 .
.
9 Выводы по работе
В результате статистического анализа данных получено, что между фактором x и откликом y существует достаточная линейная зависимость, т. к. коэффициент корреляции , и эта зависимость обратная.
Среднее
значение фактора
,
среднее значение отклика
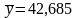 .
.
Полученная модель связи между фактором x и откликом y:
.
Модель адекватна исходным данным по критерию Фишера с уровнем доверия более 95%. Оба коэффициента статистически значимы по критерию Стьюдента..
Максимальный % ошибки прогнозирования составляет порядка 10%.
Листы Excel с расчетами приведены на рисунках 1.5 и 1.6.
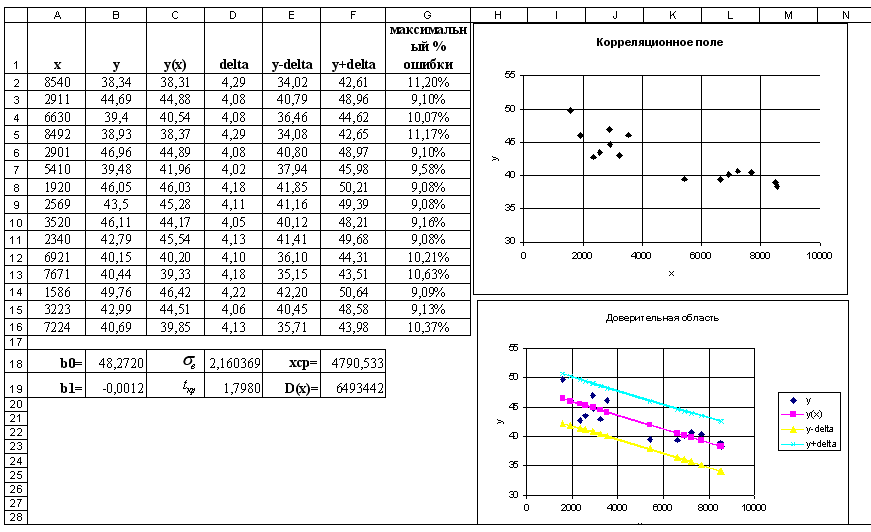
Рисунок 1.5 – Расчет в Excel
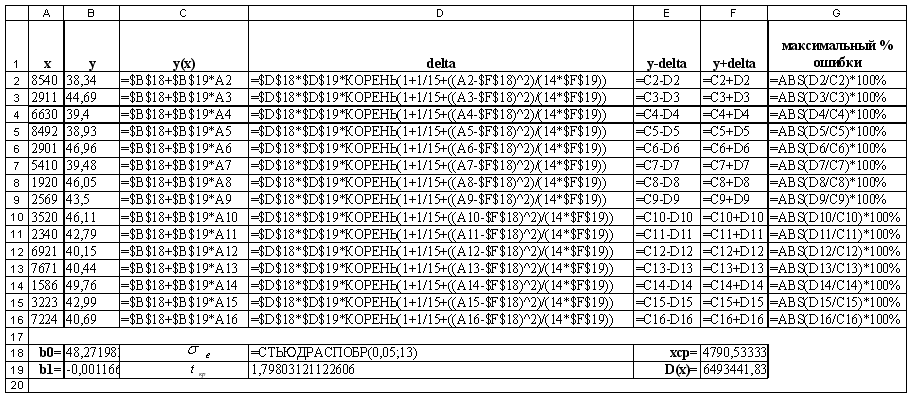
Рисунок 1.6 – Лист с формулами в Excel
1.3.2 Построение степенной модели в Excel (пример)
При
построении линейной зависимости
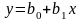 используются заданные значения x
и y,
при построении степенной зависимости
используются заданные значения x
и y,
при построении степенной зависимости
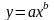 используются их логарифмы (ln
x
и ln
y).
Последовательность работы аналогична.
используются их логарифмы (ln
x
и ln
y).
Последовательность работы аналогична.
1 Настройка пакета анализа
2 Ввод данных
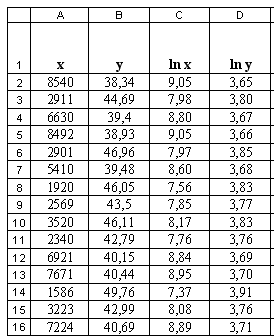
Вводим исходные данные и находим их логарифмы (таблица 1.19):
Таблица 1.19 – Исходные данные
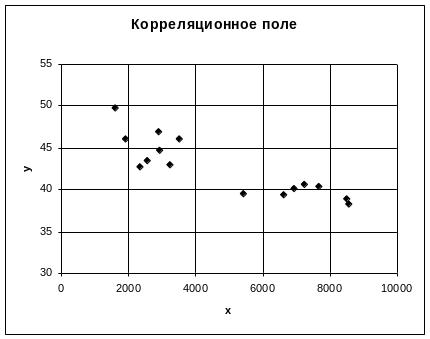
По исходным данным строится корреляционное поле с помощью «Мастера диаграмм», тип диаграммы – точечная.
3 Нахождение основных числовых характеристик
В качестве входного интервала выделяем все 4 столбца.
Получается следующая таблица для однофакторной регрессии (таблица 1.20).
Таблица 1.20 – Основные числовые характеристики
-
x
y
ln x
ln y
Среднее
4790,53
42,6853
8,3266
3,75089
Стандартная ошибка
657,948
0,88818
0,14947
0,02049
Медиана
3520
42,79
8,16622
3,7563
Мода
#Н/Д
#Н/Д
#Н/Д
#Н/Д
Стандартное отклонение
2548,22
3,43991
0,5789
0,07937
Дисперсия выборки
6493442
11,833
0,33513
0,0063
Эксцесс
-1,7127
-0,6446
-1,5251
-0,8672
Асимметричность
0,28061
0,56719
-0,1262
0,45444
Интервал
6954
11,42
1,68355
0,26072
Минимум
1586
38,34
7,36897
3,64649
Максимум
8540
49,76
9,05252
3,90721
Сумма
71858
640,28
124,899
56,2633
Счет
15
15
15
15