

2.1.2. Вероятностные модели шифров.
Введем теперь вероятностную модель шифра. Определим априорные распределения вероятностей P(X), P(K) на множествах X и K соответственно. Тем самым для любого x X определена вероятность pX(x)P(X) и для любого k K – вероятность pK(k) P(K), причем выполняются равенства
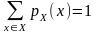 и
и
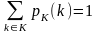 .
.
В тех случаях, когда требуется знание распределений P(X) и P(K), мы будем пользоваться вероятностной моделью В, состоящей из пяти множеств, связанных условиями 1) и 2) предыдущего определения алгебраической модели шифра, и двух вероятностных распределений:
В=(X, K, Y, E, D, P(X), P(K)).
Распределение P(Y) индуцируется распределениями P(X) и P(K) согласно формуле полной вероятности:

В большинстве случаев множества X и Y представляют собой объединения декартовых степеней A и B соответственно, так что для некоторых натуральных L и L1
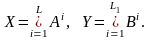
Множества A и B называют соответственно алфавитом открытого текста и алфавитом шифрованного текста. Другими словами, открытые и шифрованные тексты записываются привычным образом в виде последовательности букв.
Принята
также формулировка вероятностной модели
шифра в которой вместо включения в
совокупность распределений случайных
величин множества X,
K
Y,
рассматриваются как случайные величины
 ,
полагая при этом случайные величины
,
полагая при этом случайные величины
 независимыми.
независимыми.
Определение: вероятностной моделью шифра назовем совокупность
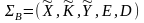 ,
,
введенных
случайных величин, множество правил
зашифрования и расшифрования. При этом
выполняются требования, предъявляемые
к алгебраической модели шифра.
Для вероятностной модели шифра
используется также обозначение
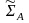 .
.
Пусть
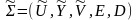 -
вероятностная модель опорного шифра.
Введя априорные распределения вероятностей
P(Ul)
и P(Kl)
на декартовых степенях множеств U
и K,
рассмотрим вероятностную модель
l-го
опорного шифра, рассматривая вместо Ul
– множества всех l-грамм,
множество U(l),
состоящее из тех l-грамм,
для которых выполняется условие
-
вероятностная модель опорного шифра.
Введя априорные распределения вероятностей
P(Ul)
и P(Kl)
на декартовых степенях множеств U
и K,
рассмотрим вероятностную модель
l-го
опорного шифра, рассматривая вместо Ul
– множества всех l-грамм,
множество U(l),
состоящее из тех l-грамм,
для которых выполняется условие
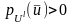 ,
то есть всех незапрещенных l-грамм.
Также вместо Vl
будем рассматривать V(l),
полагая, что выполняется равенство
,
то есть всех незапрещенных l-грамм.
Также вместо Vl
будем рассматривать V(l),
полагая, что выполняется равенство
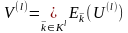 .
.
Введем вероятностную модель шифра с неограниченным ключом.
Определение: Пусть для l N

-
совокупность, состоящая из случайных
величин
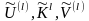 ,
множеств
правил зашифрования и расшифрования
,
множеств
правил зашифрования и расшифрования
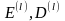 ,
для которой выполняются условия
,
для которой выполняются условия
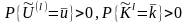
при
любых
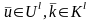 .
Тогда
вероятностной моделью шифра с
неограниченным ключом назовем семейство
.
Тогда
вероятностной моделью шифра с
неограниченным ключом назовем семейство
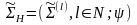 ,
,
где - случайный генератор ключевого потока.
Аналогично вводится вероятностная модель шифра с ограниченным ключом, только вместо множества Kl всех ключевых потоков длины l, рассмотрим множество K(l) возможных ключевых потоков длины l.
Определение: Пусть для l N
-
совокупность, состоящая из случайных
величин
 ,
множеств
правил зашифрования и расшифрования
,
где распределение P(K(l))
определяется
формулой
,
множеств
правил зашифрования и расшифрования
,
где распределение P(K(l))
определяется
формулой
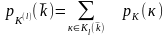 и
при любых
и
при любых
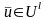
. Тогда вероятностной моделью шифра с ограниченным ключом назовем семейство
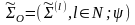 ,
,
где - детерминированный генератор ключевого потока.
2.1.3. Математические модели открытых сообщений.
Применяются для математических исследований свойств шифров и для автоматизации криптоанализа. Учет частот m-грамм приводит к следующей модели открытого текста.
Открытое сообщение – последовательность знаков (слов) некоторого алфавита.
Различают естественные алфавиты (языки), и специальные алфавиты (цифровые, буквенно-цифровые).
Естественные алфавиты могут быть нормальными и смешанными (систематически перемешанные на основе правила и случайные). Смешанные используются в качестве нижней строки подстановки.
Примеры специальных алфавитов:
Код Бодо – 32-х значный 5-битовый алфавит для телетайпов и телексов. 26 английских букв, пробел, скобки, вопрос и плюс.
Двухбуквенный алфавит Ф. Бэкона – двоичный код из букв A и B.
Код ASCII – 256 символьный 8-битовый алфавит. Может быть в различных формах записи (десятичная, двоичная и пр.).
Частотные характеристики.
Наиболее важная характеристика – избыточность открытого текста (подробно рассматривается в разделе надежности шифров).
Более простые:
повторяемость букв, пар букв (биграмм), m-грамм;
сочетаемость букв друг с другом (гласные-согласные и пр).
Такие характеристики устанавливаются на основе эмпирического анализа текстов достаточно большой длины.
Эксперимент по оценке вероятности появления в тексте фиксированных m-грамм (для небольших m).
Подсчет чисел вхождений каждой из nm возможных биграмм в достаточно длинных открытых текстах T = t1t2…tl, составленных из букв алфавита {a1, a2,…,an}. При этом просматриваются подряд идущие m-граммы текста:
t1t2…tm, t2t3…tm+1, … , t1- m+1tl-m+2…tl.
Если
 -
число появлений m-граммы
-
число появлений m-граммы
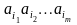 в
тексте T,
а L
– общее число подсчитанных m-грамм,
то при достаточно больших L:
в
тексте T,
а L
– общее число подсчитанных m-грамм,
то при достаточно больших L:
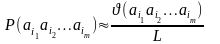
При анализе сочетаемости букв друг с другом используют понятие условной вероятности (зависимость появления буквы в тексте от предыдущих букв).
Для условных вероятностей выполняются неравенства:
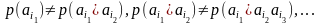
А. А. Марковым отмечена устойчивая закономерность чередования гласных и согласных. Зависимость появления букв текста вслед за несколькими предыдущими ощутима на глубину в 30 знаков, после чего практически отсутствует.
Вероятностная модель m-го приближения.
Пусть
P(m)(A)
– массив, состоящий из приближений для
вероятностей p(b1b2…bm)
появления m-грамм
b1b2…bm
в открытом
тексте, m
N,
A
= {a1,…,an}-
алфавит открытого текста, bi
A,
 .
Тогда источник "открытого текста"
генерирует последовательность
c1,c2,…,ck,ck+1,…
знаков алфавита A,
в которой m-грамма
c1c2…ck
появляется с вероятностью
.
Тогда источник "открытого текста"
генерирует последовательность
c1,c2,…,ck,ck+1,…
знаков алфавита A,
в которой m-грамма
c1c2…ck
появляется с вероятностью
p(c1c2…cm)P(m)(A).
Вероятностная модель первого приближения.
Последовательность знаков c1,c2,… в которой каждый знак ci, i = 1,2,…, появляется с вероятностью p(ci)P(1)(A), независимо от других знаков.
В такой модели открытый текст имеет вероятность
 .
.
Вероятностная модель второго приближения.
Первый знак c1 имеет вероятность p(ci) P(1)(A), а каждый следующий знак ci , зависит от предыдущего и появляется с вероятностью
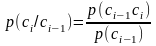
где p(ci-1сi) P(2)(A), p(ci-1) P(1)(A), i = 2,3,… Другими словами модель открытого текста второго приближения представляет собой простую однородную цепь Маркова. В такой модели открытый текст c1c2…cl имеет вероятность

С общих позиций открытый текст рассматривается как стационарный эргодический случайный процесс с дискретным временем и конечным числом состояний.
Критерии распознавания открытого текста.
Строятся на основе моделей открытого текста двумя методами:
на основе различения статистических гипотез;
на основе ограничений по запретным или ожидаемым сочетаниям букв (ЪЪ и прочие).
Первый подход:
Открытый текст – реализация независимых испытаний случайной величины, значениями которой являются буквы алфавита A = {a1,…,an}, появляющиеся в соответствии с распределением вероятностей P(A) = (p(a1),…, p(an)). Требуется определить, является ли случайная последовательность c1c2…cl букв алфавита A открытым текстом или нет.
Пусть H0 – гипотеза, состоящая в том, что данная последовательность – открытый текст, H1 – альтернативная гипотеза. В простейшем случае последовательность c1c2…cl можно рассматривать при гипотезе H1 как случайную и равновероятную либо реализация независимых испытаний некоторой случайной величины, значениями которой являются буквы алфавита A = {a1,…,an}, появляющиеся в соответствии с распределением вероятностей Q(A) = (q(a1),…, q(an)).
Наиболее мощный критерий различения двух простых гипотез – лемма Неймана-Пирсона. Также может использоваться и теорема Фробениуса.
Возможны ошибки двух родов:
ошибка первого рода (открытый текст принят за случайный набор знаков) ее вероятность
 ;
;ошибка второго рода (случайный набор знаков принимается за открытый текст) ее вероятность
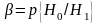 .
.
Второй подход:
Критерий запретных m-грамм. Устроен просто. Отбирается некоторое число s редких m-грамм, которые объявляются запретными. Теперь последовательно просматривая все m-граммы анализируемой последовательности c1c2…cl , мы объявляем ее случайной как только в ней встретится одна из запретных k-грамм. Весьма эффективны несмотря на простоту.
Распознавание открытого текста производится также на основе особенностей нетекстовых сообщений (файловые метки и пр.).