


Уменьшаем время задержки до тех пор пока тестовый тон еще слышен (например 5 ms).
Повторяем используя различную громкость тестового тона и получаем:
Общий эффект от частотного и временного маскирования:
Транзиентные сигналы
Представленная выше теория маскирования верна в случае рассмотрения квазистационарных, медленно меняющихся по амплитуде и частотным характеристикам сигналов. В случае же рассмотрения сигналов с резко меняющимися параметрами (транзиентные сигналы) она неприменима.
Ухо в данном случае невозможно описать с помощью линейной системы. Теоретически обоснованных подходов для описания восприятия в данном случае автору не известно. Можно описать лишь несколько хорошо известных эффектов проявляющихся при кодировании данных сигналов:
•Пре-эхо (pre-echo, ringing). Возникает перед резкими увеличениями амплитуды сигнала (атаками). При кодировании с недостаточным временным разрешением (и выделением недостаточного количества бит при квантовании) часть сигнала предшествующая атаке существенно искажается шумом квантования. Так как существует эффект пре-маскирования, то некоторое искажение допустимо, однако оно должно быть достаточно коротким по времени. Некоторые исследования показывают, что время пре-маскирования уменьшается с увеличением частоты сигнала.
•Речевой сигнал. Голосовые участки речевого сигнала являются по своей природе часто идущими атаками с быстрым затуханием (pitched signals):
Стандартная психоакустическая модель маскирования сигналов в данном случае выдает завышенные пороги слышимости (из-за недостаточного временного разрешения) и, как результат, становится слышимым шум квантования.

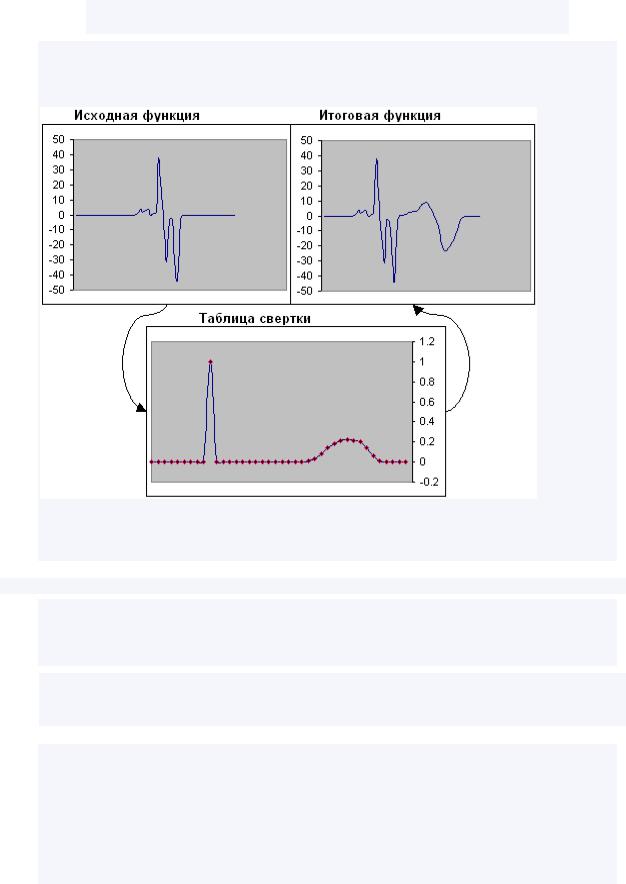
Для начала - немного теории. Свертка - это последовательный процесс, заключающийся в
сложении N точек входной функции, умноженных на коэффициенты (таблицу свертки), для получения одной точки результирующей функции. Данная операция проводится столько раз, сколько точек будет содержать результирующая функция.
Проще всего этот процесс, наверное, будет понятен по иллюстрации: справа изображена свертка некой функции (зеленые клетки) с помощью таблицы свертки {0, 1, 1} (желтые клетки), результат - столбик значений (функция) в синих клетках. Получение первых трех значений результирующей функции показано подробно - значения трех последовательных элементов исходной функции умножаются на значения таблицы свертки, результат складывается и записывается в одну ячейку результата.
•Видно, что количество точек результирующей функции всегда меньше, чем количество точек исходной. Конкретно говоря, их меньше на N-1 штук, где N - размер таблицы свертки.
•Мы применяли симметричную свертку - т.е. свертку относительно середины отрезка. Если пометить центральный элемент таблицы свертки <вот так>, то наша свертка записывалась бы в виде {0, <1>, 1}. К примеру, одноточечная свертка {<1>} оставит функцию как есть - не отняв ни одного отсчета и не изменив ни одного значения, а {<2>} - усилит функцию (увеличит каждый её элемент) в два раза. Свертка {0, <0>, 1} просто сдвинет функцию на один отсчет. Собственно говоря, для такой операции мы могли бы воспользоваться и просто несимметричной сверткой из двух точек - {<0>, 1}.
Видно, что сама по себе свертка - простой и понятный процесс. Вся хитрость и мощь заключена в том, как, с какими параметрами, этот процесс можно применить - то есть в таблице свертки. К вопросу о том, что же такое таблица свертки (далее называемая просто сверткой) и мы сейчас и перейдем.
Для наглядного представления процесса бывает очень удобно изображать таблицу свертки в виде графика, аналогичного обрабатываемым функциям. Все дальнейшие иллюстрации будут проходить с использованием картинок, подобной данной:

На картинке изображена исходная функция, построена таблица свертки ("холостая" - т.е. состоящая из множества нулей и одной единички, просто сдвигающая функцию) и изображен сам результат свертки этой функции этой таблицей. Применяемая во всех дальнейших примерах таблица свертки прикладывается симметрично, т.е. центр процесса свертки находится в центре таблицы (и, соответственно, посередине графика "таблица свертки"), сама таблица состоит из 41 точки (20 точек в одну сторону, центральная точка и 20 точек в другую сторону). Оговорюсь сразу, что эффект сдвига функции, который имеет место на предыдущей иллюстрации, нас нисколько не интересуют - суть обработки заключается не в этом.
Пример N1 - Одиночное эхо.

Начнем с простого. Данная свертка иллюстрирует получение одиночного эха, равного по амплитуде половине от исходного сигнала. Можно легко догадаться, что второй импульс (всплеск) свертки просто дублирует сигнал еще один раз через определенное число отсчетов.
Отвлечемся еще немного и поговорим о концепции, которая неразрывно связана со сверткой - импульсная функция (impulse response). Импульсная функция - характеристика процесса, отвечающая на вопрос: что сделает процесс с одиночным импульсом? Попытаемся получить импульсную функцию свертки, т.е. скормим нашему процессу одиночный импульс в качестве входной функции и посмотрим, что он с ним сделает:

Можно заметить, что свертка послала в выходной результат... себя. Очень важный вывод: таблица свертки - это импульсная функция производимого процесса. Перефразируемся: для создания процесса, отвечающего данной импульсной функции, надо просто "сверстать" данные этой импульсной функцией. Как получить импульсную функцию? Очень просто: нужно всего лишь пропустить через искомую систему импульс...
Пример N2 - Реальное эхо.
Последовательность действий проста до гениальности: мы берем микрофон и идем в некую пещеру. Устанавливаем аппаратуру, включаем запись и издаем "импульс" - вернее, максимально приближенное к нему явление: например, какой-нибудь предельно резкий удар. Записываем эхо нашего импульса. Что мы получили? Мы получили способ полностью воссоздать акустику помещения - по крайней мере в той степени, в какой нам это гарантирует неизменность звука при неизменности импульсной функции. Это важный момент, который следует понимать: не все параметры процесса определяются импульсной функцией, но большинство важных для человека - всё же определяется. Итак, мы записали затихающее реальное эхо импульса и теперь свертываем им наш собственный звук:
Пожалуйста, эхо. Эхо именно того помещения, которое закодировано в таблице свертки (то есть в импульсной функции реального эха) - со всеми тональными тонкостями, звуковой окраской и параметрами затухания (при условии достаточной длинны свертки).
Пример N3 - Частотная фильтрация
Настала пора синтезировать собственную таблицу свертки. На этот раз мы будем делать фильтрацию звука - да, обыкновенный частотный фильтр, причем частотный фильтр "высшего класса", не вносящий фазовых искажений - FIR фильтр, вернее, его частный случай - windowed-sinc. Я всё же не буду объяснять, как синтезируются подобные таблицы сверток - это не входит в тему данной статьи, просто посмотрите на готовые результаты.
Фильтр, задерживающий низкие частоты и увеличивающий содержание высоких частот (таблица свертки схематично нарисована пальцем, но и такая вполне работает):

Фильтр, задерживающий высокие частоты (таблица свертки схематично нарисована пальцем, но и такая вполне работает):
[оговорюсь: если предыдущий фильтр еще как-то похож на windowed-sinc, то последний - просто бред сивой кобылы :). На самом деле импульсная функция (таблица свертки) должна иметь затухающие в обе стороны колебания, а не
одинокий горб, как у меня. Но тем не менее даже это грубое приближение, как видно, вполне фильтрует, хотя и вносит существенные искажения, надо полагать...]
Пример N4 - Комбинированная свертка
Еще один простейший пример - однократное эхо, имеющее глухую окраску - т.е. эхо, сопряженное с фильтром высоких частот:
Первый одиночный импульс таблицы свертки оставляет в неизменной форме исходный сигнал, а второй - фильтрующий горбик - с некоторой задержкой добавляет отфильтрованный вариант сигнала, содержащий только низкие частоты.
Это - лишь малая часть всего того, что можно сделать с помощью свертки. Комбинируя различные приемы построения таблиц можно добиваться очень разнообразных эффектов - как я уже говорил, 90% всех функций типичного музыкального редактора можно реализовать с помощью сверток.
Сверткой запросто делаются следующие эффекты (в любой комбинации):
•накладываемые задержки
•любая частотная фильтрация
•вариации фаз сигналов
Поверьте, это не так уж мало - с помощью этого набора процессов легко делается хорус, вокодеры, фланжеры, любая реверберация (даже самая естественная) и эхо, любые эквалайзеры и фильтрация, а также великое множество других эффектов. Стоит один раз тщательно рассчитать таблицу свертки, и любой из этих эффектов можно запросто выполнять чуть ли не в реальном времени - так, например, реализовано большое число сложных эффектов в популярном редакторе
CoolEdit.
Подводя итог: Свертка - процесс, который реализует некое преобразование, заданное через импульсную функцию этого преобразования. Свертка позволяет в точности воспроизвести

множество процессов, имея их импульсную функцию, а также легко осуществить самую разнообразную обработку, синтезируя импульсную функцию по неким известным заранее законам.
"Что мы измеряем?"
Михаил Чернецкий
К сожалению, многие из работающих в сфере профессионального звука не имеют фундаментального академического образования звукорежиссера или звукоинженера. Поэтому в их подготовке порой встречаются досадные пробелы вследствие отсутствия системных теоретических знаний, что здорово мешает в работе. Будем эти пробелы ликвидировать!
И начнем с одного из двух главных понятий акустики - децибела.
Поможет нам в этом инженер-разработчик приборов обработки звука Михаил Чернецкий. Имя его хорошо известно профессионалам со стажем - разработанные им и его фирмой "Long" приборы обработки звука очень популярны в наших студиях. Пожалуй, нет такого вопроса в аудиотехнологиях, на который он не знал бы ответа. В написанном им для нашего журнала цикле статей о теории звука он делится своими обширными знаниями. В этом номере - первая статья, сочетающая теорию с полезными практическими сведениями.
Уже много тысячелетий человечество живёт в мире цифр. Мы измеряем в цифрах всё - один килограмм конфет, две шоколадки, пол-литра "жидкости" и др. При этом мы применяем так называемые "вещественные" единицы измерения - граммы, метры, ниты, атмосферы, литры и т.д.
Однако существуют и весьма широко используются также и нематериальные единицы измерения, причём не только в ядерной физике, где их огромное количество, но и в обычной повседневной практике. Здесь мы расскажем об одной из таких единиц, причём "дважды экзотической" - децибеле.
Почему же экзотической, да ещё дважды? Во-первых, не существует воплощённого "в металле" эталона децибела, его нельзя "повертеть в руках", пощупать. Платиноиридиевые эталоны метра, килограмма - существуют, а децибела - нет. Во-вторых, децибел - это не целая, а дольная единица. Мы часто пользуемся единицами целыми (грамм, метр) и кратными (килограмм, километр), но практически никогда - дольными. В самом деле - часто ли вы используете дециметр или дециграмм? Никому же не придёт в голову сказать: "у меня дома потолки 27 дециметров"! Так откуда же взялась и для чего нужна эта малопонятная единица? Казалось бы: есть вольты, герцы, амперы... Чего ещё желать? Однако не всё так просто! Посмотрите на два следующих рисунка.
На рис. 1 изображены две частотные характеристики. (На этом рисунке по вертикали отложено реальное выходное напряжение исследуемого устройства в вольтах). Как видим, эти две АЧХ не очень-то похожи.
На рис. 2 по вертикали отложены не вольты, а децибелы. Сразу стало видно, что эти характеристики идентичны, только одна находится чуть выше, а другая - ниже. На самом деле все четыре характеристики принадлежат одному и тому же регулятору тембра, просто характеристики 1 и 3 снимались при подаче на его вход сигнала в 1 вольт, а 2 и 4 -

100 милливольт. Очевидно, что сравнение характеристик устройств по рис 2. более удобно.
Характеристики "в децибелах" не зависят от реальных физических величин сигналов, применяемых в процессе измерений. Это - одна из главных причин того, почему логарифмический способ отображения АЧХ получил наибольшее распространение. Хотя на самом деле, помимо удобства чтения графиков, существует и другая, гораздо более существенная и глубокая причина: по закону Вебера-Фихнера между воспринимаемым ощущением и вызывающим его внешним воздействием имеется логарифмическая зависимость, т.е. чтобы ощущение изменилось "на" какую-то величину, вызвавшее его воздействие должно измениться "в" раз.
Пояснить это можно на следующем примере: от 20 до 40 Герц - одна октава, и от 10000 до 20000 Герц - тоже одна октава. Только в первом случае частота изменилась на 20Гц, во втором - на 10000Гц, а результат - одинаков: и в том, и в другом случае частота изменилась "в" два раза и мы слышим повышение высоты звукового тона "на" одну октаву. Таким образом, отображение данных в логарифмическом масштабе нам просто почеловечески "ближе".
Ранее в технике связи широкое применение получила единица НЕПЕР, основанная на натуральных логарифмах и названная в честь их изобретателя Дж. Непера (1550-1617г). 1 непер соответствует изменению уровня сигналов в =2,718 раз (в "е" раз). Интересно, что непер существует давным-давно - а на практике пользуются децибелом. Но почему именно децибелом, если уже существуют натуральные логарифмы, а есть ещё двоичные и т.д.?
Применяемое для вычисления Неперовых логарифмов число "е" - число трансцендентное, и для расчётов крайне неудобное. Поэтому по свойственной всем нам любви к круглым числам логарифмы, имеющие в своём основании число 10, и получили более широкое распространение. На десятичных логарифмах основан бел - единица, названная в честь изобретателя телефона А.Г. Бела. Однако, при ближайшем рассмотрении, он оказался "слишком крупным", а вот одна десятая его - "децибел" - оказался в самый раз. Почему же?
Дело в том, что децибел нам ближе по психофизиологическому восприятию. Один децибел (1 дБ) - это величина, максимально близкая к субъективному порогу восприятия - порогу различения громкости двух сигналов нашим ухом, и именно поэтому децибел занял ведущее место в звукотехнике. Так как децибел - величина относительная, то с его
помощью можно измерять все, что
угодно - хоть музыкальные интервалы. Действительно, в одной октаве содержится шесть нотных интервалов, а изменению напряжений в два раза (как бы "на октаву") соответствует изменение уровня на 6 дБ, т.е. музыкальный звуковысотный интервал в один тон соответствует одному децибелу. Причём значения совпадают с точностью 0,0004.
Что это - глубинная, скрытая взаимосвязь? Как знать...
Однако, как уже упоминалось, децибел - величина относительная. А как быть, если надо измерять реальные физические величины - вольты, ватты и др.? Да очень просто: надо выбрать опорный (эталонный) уровень, от которого и отталкиваться при измерениях.
Давным-давно (так уж исторически сложилось) за опорный уровень была принята величина мощности в 1 милливатт на нагрузке 600 Ом. При этом величина напряжения составляет:
U= 0,001*600 = 0,6 = 0,775 В, где
P=1 мВт - мощность;
R=600 Ом - сопротивление.
До настоящего времени эта величина напряжения является опорной для подавляющего большинства измерений.
Встречаются и некоторые другие величины. Опорная величина должна указываться после букв дБ. В английском языке приняты две основные величины: обозначению dBu (русское дБ) - соответствует опорное напряжение 0,775 В; обозначению dBV (русское дБв) - соответствует опорное напряжение 1В; встречается и обозначение dBm (дБм), для него опорный уровень - также 0,775В. Как же пользоваться децибелами, как их вычислять?
Очень просто. Для расчёта существует всего одна формула:
N=20*lg(U2/U1)
где U1 - опорное напряжение; U2 - измеряемое напряжение; N - их соотношение в децибелах.
При измерении мощности в этой формуле изменяется только одна цифра: первый множитель заменяется числом 10, а напряжения заменяются мощностью. Если после расчёта результат "N" получается со знаком "минус" - то это значит, что измеряемая величина меньше опорной (эталонной). Всё. На этом вся математика, связанная с понятием "децибел", закончена.
Теперь немного о практическом значении некоторых параметров, выраженных (измеренных) в децибелах.
• 1dB-минимальное различие в громкости сигналов, уверенно замечаемое большинством слушателей;
-3dB-увеличение мощности сигнала (не громкости!) в два раза;
-6dB-возрастание напряжения в два раза;
-10dB-увеличение мощности сигнала в 10 раз, а громкости звука - в два (!) раза;
-20dB-возрастание напряжения в 10 раз, мощности - в 100, громкости - в четыре.
-Если о каком-то устройстве известно, что его коэффициент передачи равен 0dB, то это значит, что выходной сигнал в точности равен входному. И ничего более!
Некоторые наиболее распространённые уровни электрических сигналов:
-Стандартный "нулевой" уровень 0dB=0,775V;
-часто встречающийся уровень +4dB=1,23V;
-уровень, используемый в профессиональной аппаратуре +6dB=1,55V;
-уровень, используемый в бытовой аппаратуре -10dB=0,25V (250 милливольт)
Измерение уровней в звукотехнике
Казалось бы, что здесь сложного - измерить напряжение? Подключи вольтметр - и измеряй себе на здоровье! Если бы всё было так просто... Так легко бывает, наверно, только у электриков. В звуке всё гораздо сложнее. Реальные звуковые сигналы похожи на всё что угодно, кроме известной всем синусоиды. При измерении уровней звуковых сигналов результат будет зависеть как от характера анализируемой фонограммы, так и от типа применяемого вольтметра. "Секрет" здесь заключается в том, что звуковой сигнал имеет ярко выраженный импульсный характер, со значительным пик-фактором. (Пик-фактором называется отношение мгновенной, "пиковой" амплитуды сигнала к его эффективному, действующему значению).
Пик-фактор очень сильно отличается у различных звуковых источников. Для нормально сведённой фонограммы поп-музыки (не "пережатой") он составляет величину порядка 12 дБ, для речи 18-20 дБ, а уж для необработанной фонограммы, да ещё отдельных треков, а если там записаны ударные... Даже подумать страшно!
Соответственно и разные типы вольтметров на одном и том же сигнале будут давать различные показания.
Существуют три основных типа вольтметров - вольтметр "средних значений", "пиковый" вольтметр и вольтметр "действующих значений", иначе называемый "среднеквадратичный" (RMS).
- Вольтметр средних значений (VU-meter, или "волюметр") исторически появился самым первым, и является самым простым по устройству - показывающий прибор просто включён в диагональ диодного моста. Динамические характеристики измерителя полностью определяются инерционными параметрами стрелочного индикатора, а все механические измерители имеют весьма значительный разброс по этим параметрам, соответственно и показывает он по преимуществу "цену на дрова на северном полюсе во время засухи".
Однако - благодаря его длительному применению - звукорежиссёры накопили богатый опыт работы, позволяющий (при соответствующей практике) правильно оценивать показания измерителя и вносить необходимые поправки "на слух", с учётом характера звукового материала. Только этим - и ничем иным - и объясняется такая феноменальная "живучесть" этого типа измерителей.
- Вольтметр действующих значений (среднеквадратичный) показывает величину напряжения, пропорциональную реальной долговременной мощности сигнала, его "тепловой эквивалент" И в самом деле, лучшие RMS-вольтметры построены именно с использованием термопреобразователей - исследуемое напряжение нагревает термоэлемент, по температуре которого и судят о величине напряжения.
Однако, как вы понимаете, нагрев термоэлемента - дело долгое, измеритель получается излишне инерционным, и применять его для оценки звуковых сигналов - занятие неблагодарное. Другое дело - измерение напряжения шумов.
Запомните! Измерять уровень шумов аппаратуры можно только среднеквадратичным вольтметром! И никаким иным! При использовании любых других - ошибки в результатах из-за стохастического характера шумов абсолютно непредсказуемы!
- Пиковый вольтметр в подавляющем большинстве случаев как раз и служит измерителем уровней звуковых сигналов в профессиональной аппаратуре. Однако он "в чистом виде" малопригоден для работы, так как, реагируя даже на самые короткие пики сигнала, будет давать постоянно завышенные показания, а фонограмма при этом будет тихой. Как же быть? Выход был найден в некотором (намеренном) "ухудшении" параметров измерителя - таким образом, чтобы отдельные, "очень уж короткие" пики сигналов он как бы "перестал видеть". Для этого в схему измерителя были введены специальные интегрирующие зарядно-разрядные цепочки, определяющие динамические характеристики прибора. Такие измерители получили название "квазипиковые", и вот они-то на самом деле и являются теми измерителями, с которыми мы имеем дело в повседневной практике.
Запомните! ВСЕ измерители, на которых написано "Peak" - на самом деле являются квазипиковыми! Единственные чисто пиковые измерители - это индикаторы "Over" на некоторых цифровых рекордерах.
Самые первые квазипиковые измерители имели время интеграции 60 миллисекунд, что примерно соответствует инерционности человеческого слуха. Время интеграции - это величина, определяющая быстродействие измерителя - или, иначе говоря, - длительность тех коротких пиков сигнала, на которые измеритель ещё реагирует. На более короткие сигналы измеритель, конечно, тоже реагирует, но плохо, слабо. Постепенно, с ростом технических требований к качеству записей, ужесточались и требования к измерителям уровней. Требовалось всё большее отношение сигнал/шум, постоянно возрастал уровень записи (намагниченность ленты), и всё меньшим становился запас по перегрузке. (А "цифра", например, не терпит вообще никаких перегрузок, даже малейших)
Чтобы более-менее надёжно контролировать максимальные уровни сигналов, стали увеличивать быстродействие измерителей. Сначала время интеграции было уменьшено до 10 миллисекунд, а затем - и вовсе до 5 миллисекунд. Считается, что искажения перегрузки с длительностью менее 5 мс ухо не замечает. Смотря какие искажения! Цифровые - ещё как замечает...
Но... За всё приходится платить. В данном случае за увеличение быстродействия измерителей пришлось расплачиваться значительным увеличением разрыва между субъективно воспринимаемой громкостью звучания и показаниями индикаторов. Хотя в случае современной поп-музыки, до предела "сжатой", закомпрессированной, этот разрыв не очень уж и велик.
Итак - 60-мс измерители удовлетворительно соответствуют субъективному восприятию громкости, но плохо показывают пики сигналов. 5-мс измерители хорошо индицируют пики, но их показания плохо коррелируют с громкостью звука.
Как быть? Да очень просто. Решите - что вам, собственно, нужно контролировать? Если вы радиоинженер и обслуживаете передатчик или другую линию связи, то для вас главное - не допустить перегрузки. Смело выбирайте самый быстрый индикатор - и спокойно работайте. Но если вы звукорежиссер, то перед вами встанет проблема "плотности" звучания и других художественных особенностей. Тупик? Пока ещё нет. Есть два выхода. Первый - это применение "двойных" индикаторов, которые показывают оба значения - и пиковое, и действующее. Они уже существуют и довольно широко применяются, хотя в их конструкции наличествует оттенок лёгкого и нестрашного вранья: индикатор "Peak"
реально квазипиковый (см. выше), а та часть индикатора, которая на самом деле показывает истинный RMS-уровень (есть и такие, только цена "кусается"), стыдливо, по инерции, именуется "VU".
Но возможен и второй выход. Как знать, может быть, со временем, когда звукорежиссёры накопят достаточный опыт, снова повторится история с волюметром, только на этот раз "с точностью до наоборот"? А как вы думаете?..
|
N,dB |
|
A |
|
N,dB |
|
A |
|
|
|
|
||||
|
0.1 |
|
1.012 |
|
-0.1 |
|
0.989 |
|
|
|
|
||||
|
0.2 |
|
1.023 |
|
-0.2 |
|
0.977 |
|
|
|
|
||||
|
0.3 |
|
1.035 |
|
-0.3 |
|
0.966 |
|
|
|
|
||||
|
0.4 |
|
1.047 |
|
-0.4 |
|
0.955 |
|
|
|
|
||||
|
0.5 |
|
1.059 |
|
-0.5 |
|
0.944 |
|
|
|
|
||||
|
0.6 |
|
1.072 |
|
-0.6 |
|
0.933 |
|
|
|
|
||||
|
0.7 |
|
1.084 |
|
-0.7 |
|
0.923 |
|
|
|
|
||||
|
0.8 |
|
1.096 |
|
-0.8 |
|
0.912 |
|
|
|
|
||||
|
0.9 |
|
1.109 |
|
-0.9 |
|
0.902 |
|
|
|
|
||||
|
1.0 |
|
1.122 |
|
-1.0 |
|
0.892 |
|
|
|
|
||||
|
2 |
|
1.259 |
|
-2 |
|
0.794 |
|
|
|
|
||||
|
3 |
|
1.412 |
|
-3 |
|
0.707 |
|
|
|
|
||||
|
4 |
|
1.585 |
|
-4 |
|
0.630 |
|
|
|
|
||||
|
5 |
|
1.778 |
|
-5 |
|
0.562 |
|
|
|
|
||||
|
6 |
|
1.996 |
|
-6 |
|
0.501 |
|
|
|
|
||||
|
7 |
|
2.239 |
|
-7 |
|
0.447 |
|
|
|
|
||||
|
8 |
|
2.512 |
|
-8 |
|
0.398 |
|
|
|
|
||||
|
9 |
|
2.818 |
|
-9 |
|
0.355 |
|
|
|
|
||||
|
10 |
|
3.162 |
|
-10 |
|
0.316 |
|
|
|
|
||||
|
11 |
|
3.548 |
|
-11 |
|
0.282 |
|
|
|
|
||||
|
12 |
|
3.981 |
|
-12 |
|
0.251 |
|
|
|
|
||||
|
13 |
|
4.467 |
|
-13 |
|
0.224 |
|
|
|
|
||||
|
14 |
|
5.012 |
|
-14 |
|
0.200 |
|
|
|
|
||||
|
15 |
|
5.623 |
|
-15 |
|
0.178 |
|
|
|
|
||||
|
16 |
|
6.310 |
|
-16 |
|
0.158 |
|
|
|
|
||||
|
17 |
|
7.080 |
|
-17 |
|
0.141 |
|
|
|
|
||||
|
18 |
|
7.943 |
|
-18 |
|
0.126 |
|
|
|
|
||||
|
19 |
|
8.913 |
|
-19 |
|
0.112 |
|
|
|
|
|
|
||
|
20 |
|
10.0 |
|
-20 |
|
0.100 |
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
30 |
|
31.623 |
|
-30 |
|
0.031 |
|
|
|
|
||||
|
40 |
|
100.0 |
|
-40 |
|
0.010 |
|
|
|
|
|
|
|
|
ПРИЛОЖЕНИЕ. ТАБЛИЦА ПЕРЕВОДА ДЕЦИБЕЛ В ОТНОСИТЕЛЬНЫЕ ЕДИНИЦЫ
Как пользоваться таблицей?
Cложите из составляющих в графе dB необходимую вам величину, а коэффиеценты из графы А - перемножьте, это и будет искомый результат.

Что мы измеряем? Часть 2. Шумы и искажения
Михаил Чернецкий
Наверное, не будет большим преувеличением сказать, что главные параметры, на которые мы обращаем внимание при выборе аппаратуры - это уровни шумов и искажений. Почему? Возможно потому, что практически любые другие - динамические, частотные и
др., при наличии желания и некоторой квалификации можно без особых затруднений изменить в любую нужную вам сторону, а эти практически неизменяемы. То есть изменить-то можно, но это потребует полной переделки всего изделия, что в реальности маловероятно. Таким образом, эти два параметра - уровень шума и искажения - "объективная реальность, данная нам в ощущениях", и с ними - жить и работать. Как же их измерить, и - что ещё важнее - правильно истолковать результат?
Измерение шумов
Как я ранее уже писал (пилотный номер "Звукорежиссера"), для правильного измерения шумов необходим прежде всего квадратичный вольтметр. Обычные вольтметры, тестеры и т.д., в том числе и цифровые, для этих целей непригодны, потому, что все они измеряют другие значения - пиковое, средневыпрямленное и т.д. При этом часто на шкале может быть даже написано "RMS", но это не соответствует истине, т.к. шкала только проградуирована в этих значениях, а реально измеряется то, что написано выше. Такими приборами можно точно измерять только синусоидальный сигнал: для "синуса" между различными его значениями (пиковым, эффективным) существуют строго определённые соотношения, и в конструкции приборов это уже учтено. Благодаря этому, при измерении синусоидального сигнала результаты получаются достоверными, но при измерении шумов их показания, увы, весьма недостоверны...
Широкополосный шум в сигнале
Так что, если вы хотите получить при измерении шума достоверные результаты, то прежде всего убедитесь, что применяемый Вами для этих целей вольтметр истинно квадратичный.
Итак, вы взяли подходящий прибор, подключили его к выходу исследуемого вами устройства и можно уже измерять? Можно, но лучше не нужно. Не хватает осциллографа. Казалось бы - зачем? Собрались шум померить, а не посмотреть? Но шумы в реальной студийной аппаратуре весьма малы, и составляют (в худших случаях!) доли милливольт. В силу их малости, даже самое незначительное присутствие других сигналов может сильнейшим образом повлиять на результаты измерений, исказив их до полной неузнаваемости. Поэтому, чтобы точно знать, что мы измеряем уровень именно шумов, а не чего-то ещё неизвестного, желательно, даже необходимо, дополнительно осуществлять визуальный контроль исследуемого сигнала. Кстати, это полезно всегда, чтобы знать, что именно измеряется, а то - такого можно "намерить"! В сигнале теоретически всегда может присутствовать "много чего", например, фон, ультразвуковые наводки от цифровых цепей и т.д. И чтобы не ошибиться, лучше этот сигнал ещё и посмотреть.
Подключать осциллограф нужно не к выходу исследуемого прибора, а к специальному выходу вольтметра. Практически в любом профессиональном вольтметре есть специальное гнездо - "Выход". На него подаётся уже усиленный внутри вольтметра сигнал, и, подавая на осциллограф сигнал именно оттуда, вы "убиваете двух зайцев". Так как уровень напряжения шумов очень мал, то, подав его на осциллограф напрямую, можно, скорее всего, вообще ничего не увидеть, т.к. чувствительность большинства осциллографов недостаточна для анализа слабых сигналов. Кроме того, если вы подключите осциллограф к входу вольтметра, то сам осциллограф, вполне вероятно, сможет навести помехи на входные цепи вольтметра, и тогда - прощай объективность измерений!
Теперь, когда к выходу исследуемого устройства подключен вольтметр, а к его выходу - осциллограф, мы готовы к проведению измерений? Не совсем. Дело в том, что современные устройства обработки звуковых сигналов собраны, как правило, на весьма скоростных, высокочастотных элементах - транзисторах и микросхемах. Спектр их шумов может простираться очень далеко за пределы звукового диапазона, а так как вольтметр измеряет "всё", то его показания вследствие этого могут существенно отличаться от воспринимаемых "на слух" в звуковом диапазоне величин. Как быть?
Очень просто - включить в цепь измерительный фильтр, ограничивающий полосу частот, подаваемых на вольтметр, сигналами звукового диапазона, от 20 Гц до 20 кГц. В некоторых моделях лабораторных вольтметров такие фильтры уже встроены в конструкцию прибора, а если у вас такого фильтра нет - не беда, его несложно сделать и самому.
Запомните - фильтр должен ограничивать только полосу частот, подаваемых на детектор (выпрямитель) вольтметра! И ничего более!
Теперь, имея всё необходимое: вольтметр, фильтр звукового диапазона, осциллограф - можно приступать к измерениям.
Рассмотрим для начала параметр, вызывающий наибольшие затруднения - входной шум микрофонного усилителя. Если у вас в описании пульта указано, что эта величина составляет, к примеру, -130 дБ, то означает ли это, что отношение сигнал/шум будет составлять такую же точно величину? Конечно, нет.
В профессиональной аппаратуре вообще не очень часто указывается соотношение сигнал/шум, т.к. эта величина неконкретна, и зависит от условий реальной работы. Это можно пояснить следующим примером: представьте, что некоторое устройство имеет выходной шум в 1 милливольт. Каково будет отношение сигнал/шум? Это будет зависеть от величины полезного сигнала. Если сигнал будет 1 вольт, то отношение сигнал/шум = 60 дБ, а если 10 вольт, то отношение сигнал/шум составит 80дБ.
Так и в случае с пультом: можно снимать выходной сигнал величиной 10 вольт, а можно 250 милливольт. Естественно, что отношение сигнал/шум будет в этих случаях различным. Вот как раз, чтобы избежать возможных разночтений, и указывается не отношение сигнал/шум, а величина входных шумов, только выраженная не в вольтах, а в децибелах.
Посмотрите на спецификацию своего пульта. Там вы увидите множество значений уровней шумов для многих случаев: когда мастер-фейдер закрыт или открыт, одна ячейка открыта или несколько, и т.д. и т.п. Всё это именно абсолютные величины, а не отношения сигнал/шум!
Однако вернёмся к микрофонному входу. В описании указано: "EIN= -130 dB". Как это понимать и измерять? "EIN" - это Equivalent Input Noise ("эквивалентный входной шум"), то есть уровень шума устройства, приведённый к его входу. Для измерения достаточно узнать коэффициент усиления и величину шумов на выходе устройства, а затем - вторую величину разделить на первую, и результат - выразить в децибелах.
Пример. Для измерения EIN необходимо сделать следующее: подключить (обязательно!) на вход вместо микрофона его эквивалент, постоянный резистор номиналом 150 или 200 Ом (его величина обычно указывается в документации), и установить регулятор GAIN на максимум. Измерить выходное напряжение шумов. Затем отключить эквивалент микрофона и подать на вход небольшой сигнал (к примеру, 1 мВ). Измерить величину выходного сигнала. Разделив её на величину входного, получим коэффициент усиления устройства. Допустим: вход - 1 мВ, выход - 1 В, 1 В/1 мВ=1000. То есть в 1000 раз или 60 дБ.
Если при измерении шума ранее было получено, к примеру, 0,25 мВ (-70 дБ), то для нашего устройства EIN = (-70 дБ) + (60 дБ)= -130 дБ.
Казалось бы, для чего такая громоздкая и малопонятная на первый взгляд величина? Вы получили реальную величину шумов на входе вашего устройства. И теперь, при необходимости, очень легко узнать величину отношения сигнал/шум для любого сигнала. Для этого достаточно из полученной величины EIN вычесть уровень подаваемого на вход сигнала - и готово!
Пример. Допустим, вы подаёте на вход сигнал величиной 0,775 мВ (-60 дБ). Сигнал/шум = EIN(дБ)-Uвх (дБ)=(-130 дБ)-(-60 дБ)=-70 дБ.
Всё! Для данного входного сигнала, с этим предусилителем, отношения сигнал/шум большего, чем -70 дБ, не получить!
Здесь необходимо сделать одно замечание. Дело в том, что не шумящих источников не бывает! Шумит всё, в том числе и резисторы. Тепловые шумы резистора номиналом 150 Ом составляют величину 0,22 мкВ (или -131 дБ). Плюс собственные шумы входного каскада... Поэтому, если у вас вдруг получится, к примеру, -135 дБ, то проверьте приборы и всё, что можно. Аналогично, некоторые, не совсем добросовестные фирмы указывают
EIN=-132 дБ.
Не бывает! (Если, конечно, после букв "дБ" не стоит буква "А").
Так мы постепенно подошли к применению так называемого "псофометрического фильтра" (мало было осциллографа и одного фильтра!). Что же это такое и для чего нужно?
Как известно, чувствительность слуха к разным частотам неодинакова, и поэтому два шума с одинаковой "приборной" величиной, измеренной в широкой полосе, могут "на слух" восприниматься совершенно по-разному. Чтобы учесть особенности именно слухового восприятия, в цепь измерения, кроме уже описанных устройств, дополнительно включается специальный фильтр, чья АЧХ соответствует чувствительности нашего уха к слабым сигналам. В последнее время этот фильтр часто называют "взвешивающим".

Существует множество таких фильтров с АЧХ, соответствующими свойствам слуха при различных громкостях ,- A, B, C, D. Но реально для измерения шума применяется только один - А. Если измерения проводились с использованием этого фильтра, то в результате пишется не просто "дБ", а "дБА", т.е. наличие обозначения "дБА" означает, что в результаты измерений внесена поправка, учитывающая особенности слухового восприятия. Эти данные более точно соответствуют тому, что мы слышим.
Различие между просто "дБ" и "дБА" зависит от спектра шума, и в общем случае непредсказуемо, однако "дБА" чаще всего меньше. Например, если у вас шум, измеренный в широкой полосе будет -80 дБ, то при измерении с фильтром А это значение может быть и -85 дБА…
Измерение шумов остальных звукотехнических устройств принципиальных отличий от описанного выше не имеет, и, как правило, особых затруднений не вызывает. Да и чаще всего это гораздо проще - например, для усилителей (и многого другого) вовсе не надо результаты пересчитывать, "приводить к входу" и т.д.
Только надо не забывать о подключении к входу испытуемого устройства эквивалента источника сигнала, так как на "висящий в воздухе" вход может навестись всё, что угодно. Замыкать же вход "на землю" не следует - это и методологически неверно, да и в силу возможных особенностей разводки "земельных" проводников в конкретном устройстве в этом случае вполне возможно возрастание уровня шумов, да и фона - тоже (в практике автора, во всяком случае, такое бывало неоднократно). И не забывайте об обязательном контроле измеряемых величин визуально, по осциллографу!
Измерение искажений
В аудиоаппаратуре возникает множество искажений различных видов, однако наибольшее распространение получила оценка одного их вида - гармонических искажений, или попросту коэффициента гармоник Кг, ранее, а иногда ещё и сейчас, называемого коэффициентом нелинейных искажений (синоним, пришедший из немецкого, "клирфактор").
Нелинейные искажения
Долгие годы этот показатель считался вполне достаточным для оценки качества аппаратуры, и во многом это верно и сейчас. Конечно, существует много и других параметров, характеризующих нелинейность систем - таких, например, как интермодуляционные искажения(IMD), переходные интермодуляционные искажения (TIMD), а также способов их измерений. Однако все они достаточно сложны в аппаратурной реализации, и в силу этого не имеют широкого распространения в повседневной практике. Для измерения этих величин необходим, прежде всего, высококачественный узкополосный анализатор спектра, с большим динамическим диапазоном. Плюс несколько (два-три) специальных генераторов, крайне редко встречающихся. Ещё масса трудоёмких и кропотливых измерений, а потом расчёты...
А чем лучше Кг? Тем, что проще! Хотя, на самом деле, его измерение не имеет очень уж больших отличий от вышеописанных, но благодаря некоторым, вполне допустимым упрощениям, стало возможным создать приборы для автоматического измерения Кг, и вследствие этого процедура измерений доступна практически всем.
Отечественная промышленность выпускала много приборов для этих целей, от совсем ручных до полных автоматов с цифровым измерением (не ищите, вымерли как мамонты). Вспомним об С6-11, одном из самых доступных. Это, конечно, не совсем полный автомат, но вполне достаточен для практических целей.
Что это вообще такое Кг? В силу неидеальности элементов тракта, в выходном сигнале любого устройства появляются какие-то элементы, которые отсутствовали во входном. Именно эти лишние составляющие и являются собственно искажениями. Таким образом, Кг - это отношение суммы всех гармоник сигнала к уровню его основного тона.
Часто приходится слышать про некие фазовые и частотные искажения. Всё это околонаучные спекуляции. Искажениями, строго говоря, может быть названо только то, что в дальнейшем не может быть исправлено.
Изменения в сигнале, вызванные неравномерностью АЧХ устройства (или его ФЧХ), могут быть устранены с помощью эквалайзера или фазовращателя, а вот появившиеся новые составляющие - не убрать ничем. Если перегруженный до уровня ограничения усилитель обрезал верхушки синусоид входного сигнала - то попрощайтесь с ними навсегда! Что упало - то пропало...
При определении коэффициента гармоник учитываются только те новые составляющие в выходном сигнале, частота которых в целое число раз выше частоты входного сигнала. Эти составляющие являются гармониками входного сигнала (для 1 кГц: 2 кГц - это вторая гармоника, 3 кГц - третья, 4 кГц - четвёртая, и так далее...), поэтому и интегрированнный показатель их уровней и называется именно так - коэффициент гармоник. Понятно, что при подаче на вход широкополосного сигнала спектр возникающих гармоник будет также очень широк, и будет невозможно определить, где - "вершки", а где - "корешки". Как быть? Вы скажете: надо подать на вход всего один сигнал, тогда и разобраться будет проще. Для этих целей подойдёт любой звуковой генератор, у которого Кг заведомо намного меньше, чем у исследуемого устройства. Наверное Г3-118 лучший отечественный генератор для этих целей, его собственный Кг=0,002%, что вполне достаточно для большинства практических применений.
Сама процедура измерений очень проста - достаточно на вход испытуемого устройства подать сигнал от генератора, а на выход подключить ИНИ (измеритель нелинейных искажений) и готово, ИНИ сам покажет Кг. Но..., опять забыли осциллограф! На всех, без исключения, ИНИ обязательно есть гнездо "Выход", чтобы видеть, что измеряем. Дело в том, что в силу упомянутых ранее упрощений ИНИ измеряет не только гармоники, но все, что есть в выходном сигнале, кроме, естественно, сигнала основной частоты. Таким образом, на результатах измерений могут сказаться любые помехи, имеющиеся в сигнале: фон, шум, и т.д.
В описаниях почти везде пишется "THD+Noise", это и есть результат измерения обычным ИНИ, который реально измеряет отношение амплитуды сигнала основной частоты ко всему остальному. Связано это с самим принципом его работы. ИНИ с помощью имеющегося в нём фильтра полностью подавляет сигнал основной частоты, и измеряет всё то, что осталось после фильтрации. На его выходное гнездо как раз и подаётся всё то, что осталось, то есть - продукты искажений.
Благодаря именно такому построению ИНИ, мы и имеем гнездо "Выход", подключив к которому осциллограф, можно посмотреть, а что наш "испытуемый" внёс в сигнал своего? Какую именно "гадость" добавил?
Надо же знать, что именно измерил ИНИ. А что, если вдруг возник фон, и ИНИ именно его принял за гармоники? Или шумы? Ведь слуховой контроль при этих измерениях, как правило, отсутствует. Вот осциллограф и показывает, что именно измеряли. Кстати, шумов, как правило, можно не бояться. Ведь никто, наверное, не купит усилитель с отношением сигнал/шум 80 дБ? А уровень помех в -80 дБ соответствует Кг=0,01%. Почему? Да потому, что 1% - это одна сотая часть, или -40 дБ. 0,1% - это -60 дБ, 0,01% - это -80 дБ. Кстати, иногда Кг именно так и указывается, в децибелах. Не смущайтесь, встретив такую запись, - это то же самое, только иначе записанное.
А что ещё полезного можно узнать, визуально изучая выходной сигнал ИНИ? Оказывается, многое. Не секрет, что ламповая и транзисторно-микросхемная аппаратура звучат во многом по-разному при прочих равных условиях. Это в значительной степени объясняется именно различным спектром гармоник.
В то время, как в лампах создаваемые ими гармоники имеют сравнительно большую величину, но узкий спектр - как правило, 2-я и 3-я гармоники, а остальные пренебрежимо малы. в транзисторах наоборот: спектр их гармоник может быть очень широк - до 20-й и даже более. И хотя все они имеют малую величину, - слышимость их гораздо больше. Суммарный же Кг вполне может и там и там быть одинаковтак как сумма "немногих, но больших" в первом случае, будет равна сумме "многих, но малых" - во втором. Выходной сигнал ИНИ, поданный на осциллограф, как раз и поможет оценить спектр гармоник.
Если на экране картинка, более-менее похожа на синусоиду, то, значит, спектр гармоник достаточно узкий, и, скорее всего, ваш аппарат будет звучать достаточно чисто. Если же картинка имеет множество изломов, острых углов, и больше напоминает старую, ржавую пилу, то спектр гармоник очень широк, и, скорее всего, хорошего звука ждать не приходится.
Кстати, часто приходится сталкиваться с неизвестно откуда взявшимся мнением, якобы измерение Кг на высоких частотах не имеет смысла, т.к. гармоники, мол, всё равно за пределами звукового диапазона, и поэтому на качество звука не влияют.
Глубочайшее заблуждение! Да, гармоники - за диапазоном слышимости. Да, на качество звука синусоидального сигнала не влияют. Но слушают ведь не синус!
А раз не синус - приходится считаться с объективной реальностью того факта, что сигнал широкополосный! А, значит, и спектр гармоник реального сигнала - тоже не линейчатый, а широкополосный. А поэтому там, где гармоники синуса чувствовали себя привольно, далеко отстояли друг от друга и не взаимодействовали, высшие гармоники настоящего звукового сигнала будут влиять друг на друга. Это приводит к омерзительнейшему результату - появлению комбинационных частот, биений. А уж как они портят звук - никаким гармоникам и не сравниться! Поэтому, если хотите полностью оценить исследуемый прибор, то необходимо измерить Кг во всём звуковом диапазоне, или хотя бы в нескольких точках - в его середине и на краях диапазона. Подробное описание методик измерения "всего и вся" - к сожалению, выходит далеко за пределы этой статьи.
В большинстве моделей ИНИ имеются различные дополнительные устройства, помогающие в работе. В упомянутом ранее С6-11, к примеру, есть возможность по желанию пользователя производить измерения как в вольтах и процентах, так и в

децибелах. Есть также очень полезная функция - встроенный обрезной фильтр, подавляющий все частоты, лежащие ниже 1 кГц. Зачем? Если придётся измерять Кг мощных усилителей, то вполне возможна такая ситуация: с увеличением выходной мощности усилителя будет расти и уровень фона.
Дело в том, что во многих моделях усилителей ёмкость фильтрующих конденсаторов невелика, и при росте мощности питание "проседает", увеличиваются пульсации питающего напряжения, что сопровождается ростом сетевого фона. Конечно, это происходит только при работе усилителя на нагрузку. Не забудьте её подключить! Измерять параметры усилителей мощности без нагрузки, на холостом ходу, бессмысленно. Все усилители покажут такие Кг, что хоть на Золотую медаль выдвигай! Конечно, это не относится к измерению шумов, там наличие или отсутствие нагрузки принципиальной роли не играет. Включив этот фильтр, можно убрать фон из измерений и получить более достоверные результаты.
К сожалению, ограниченный объём статьи не позволяет охватить подробно весь круг вопросов измерений в звукотехнической практике. Если у вас возникнут какие либо вопросы - пишите в редакцию. Ваши письма помогут полнее узнать круг необходимых тем.
Компьютеры находят все более широкое применение во всех областях человеческой
деятельности. В настоящее время сдерживающим фактором к увеличению количества компьютеров в мире является неприятие их неподготовленным пользователем, его страх перед компьютерами. В определенной степени это неприятие связано с традиционными для вычислительной техники способами ввода информации, в первую очередь, ввода с клавиатуры.
Внастоящее время во всем мире ведутся работы по созданию более естественных для человека средств общения с компьютером, среди которых первое место занимает речевой ввод информации в компьютер. Проблема речевого ввода информации осложняется рядом факторов: различием языков, спецификой произношения, шумами, акцентами, ударениями и т.п. Данная работа посвящена разработке приемов и алгоритмов распознавания речи на русском языке.
Влюбом языке существует некий набор звуков, который участвует при формировании звукового облика слов. Как правило, звук вне речи не имеет значения, он приобретает его лишь как составная часть слова, помогая отличить одно слово от другого. Элементы этого набора звуков называются фонемами.
Процесс произнесения звуков речи имеет несколько основных стадий.
Легкими создается поток воздуха, который проходя через гортань, ротовую и носовую полость получает полезную информацию, которая распространяется в пространстве в виде звуковых волн. Звуки могут формироваться при участии истинных голосовых связок и без их участия и от этого коренным образом меняется их образ. Звуковые колебания воспринимаются микрофоном, и как результат преобразования имеется аналоговый сигнал, что дает возможность применить аналоговые методы анализа сигнала. Как правило, на этой стадии могут применяться системы фильтров. Однако, если рассматривать распознавание речи в приложении к компьютерным

технологиям на уровне программного обеспечения, то необходимо провести следующий этап преобразования информационного образа речи - из аналогового сигнала в непрерывно-дискретный.
Преобразование реализуемо с применением различных видов аналого-цифровых преобразователей. Главным требованием к ним является достаточность качественных характеристик преобразования. Такими качественными характеристиками являются частота дискретизации и разрядность представления каждой дискреты.
Частота дискретизации определяет ту предельную частоту аналогового сигнала, которая может быть информативна в дискретном представлении. Из исследований в технической фонетике, в частности, в телефонии известно, что приемлемый диапазон частот, при котором человек может распознавать речь и определить говорящего является 4. Именно это значение легло в основу частотного уплотнения каналов в телефонии и определении пропускной способности цифровых каналов связи.
Анализ аналоговых характеристик речи показывает, что реально частота дискретизации должна быть не менее 8 - 12 Khz. При дальнейшем понижении частоты начинает теряться информация, которая активно используется при распознавании (особенно это важно при распознавании звуков, содержащих шум). Нет смысла поднимать частоту дискретизации выше 25 Khz, так как при незначительном увеличении полезной информации, начинает увеличиваться количество бесполезной информации - шумов.
По диапазону количества разрядов, передающих дискретный сигнал, достаточно 8 разрядов, но при условии хорошего качества сигналов и его высокого уровня. Человек способен воспринимать речь в более худших условиях, чем описанные выше, например, телефонные разговоры. Однако, при восприятии речи человек использует механизмы ассоциативного анализа, не просто разбирая и сравнивая услышанные звуки, но собирая фонемы в словесные образы, подбирая наиболее подходящие не только по звуковому подобию, но и по интонации, эмоциональной окраске, контексту слова, фразы, предложения и всего текста. Поэтому, человек способен распознавать речь даже при большой нехватке несущей информации. Например: человек намного требовательней к качеству звука при прослушивании речи на чужом языке, при слабом его знании, чем при восприятии родной речи.
Обратимся к полученной после дискретизации осциллограмме речи. В общем случае информация в виде образа речи может быть представлена последовательностью участков. На одних прослеживаются некие периодические процессы различной амплитуды (см. рисунок), другие представляют из себя различные виды шумов, третьи - участки с сигналом, близким к нулевому значению, четвертые могут быть описаны как скачки.
Над полученным образом речи можно производить работу по распознаванию. Рассмотрим иерархию построения системы распознавания речи. В качестве простого примера рассмотрим схему распознавания, когда сигнал делится на два слова (для уверенного деления в простейших случаях достаточно полуторносекундной задержки между словами при произношении). Слова, в свою очередь, распознаются как единое целое. При этом используются различные методы сравнения с эталонами, вид которых зависит от методики распознавания: при использовании методов динамического программирования эталоны представляются в том же виде, что и поступающий сигнал (с учетом деления на слова), при применении методов разложения в ряды, эталоны представляют из себя наборы параметров этого ряда.
Результатом работы этой схемы является слово из списка присутствующих в множестве эталонов или сообщение об ошибке, если полученный образ не соответствует в достаточной мере ни одному эталону.
К недостаткам такой системы можно отнести: необходимость создания совокупности эталонов фактически для каждого человека (так называемый процесс обучения системы распознавания), невозможность создания автоматической системы коррекции эталонов, пропорциональность времени, затрачиваемого на распознание слова, количеству эталонов, и необходимость конечного выбора из нескольких возможных вариантов.

Из-за перечисленных недостатков описанная схема может применяться только при необходимости распознавания ограниченного списка слов одного или нескольких операторов. Например, в различных системах управления с небольшим количеством команд.
Улучшить качество работы рассмотренной выше одноуровневой системы распознавания возможно за счет увеличения количества уровней. Пусть рассмотренная нами система распознавания слова из совокупностей шаблонов занимает средний уровень нашей иерархии.
Добавим к распознаванию среднего уровня еще один, верхний, уровень. На этом уровне предполагаемое слово анализируется с точки зрения фразы в целом. В результате, за счет синтаксических и семантических свойств языка приобретается дополнительная информация, повышающая качество распознавания.
Однако, идея увеличения количества информации о слове необязательно должна быть связана с верхним уровнем. Рассмотрим более нижний уровень иерархии, где производится фонемный разбор речевого образа, то есть деления выделенных слов на фонемы с последующим их распознаванием. Это позволило производительно использовать распознавание по иерархической схеме: из списка фонем, распознанных с определенной точностью, составляется шаблон, который передается на следующий уровень, где по нему происходит подбор наиболее подходящего слова, передача информации о выборе на более высокий уровень, для дальнейшего анализа, и на нижний, для подстройки системы на конкретного пользователя. Достоинством это схемы является высокая адаптивность, дающая возможность динамической самоподстройки системы на оператора, и многоуровневая система проверок, повышающая точность работы.
Сравнивая распознавание речевого потока методом распознавания целых слов и распознавание фонем, можно сделать вывод: при небольшом количестве слов, используемых оператором, более высокую надежность и скорость можно ожидать от распознавания целых слов, Но при увеличении словаря скорость резко падает. Предположительно, размер словаря системы распознавания уже в сотню слов делает переход на уровень более низкий, чем распознавание слов в целом актуальным.
Звуки, участвующие в формировании речи, имеют две основные классификации: по артикуляционным признакам и по акустическим признакам.
Классификация звуков по артикуляционным признакам является крайне важной при использовании методов генерации и распознавания речи с помощью моделирования носоглотки, но для решения задач деления на фонемы более интересно рассмотрение акустических различий звуков. По акустическим признакам звуки подразделяются:
Тональные звуки - образуются голосом при полном отсутствии шумов, что обеспечивает хорошую слышимость звука:
гласные: а, э, и, о, у, ы.
Сонарные (звучные) - чье качество определяется характером звучания голоса, который играет главную роль в их образовании, а шум участвует в минимальной степени:
согласные: м, м’, н, н’, л, л’, р, р’, j.
Шумные - их качество определяется характером шума - акустического эффекта от трения воздуха при сближенных или взрыве при сомкнутых органах речи:

•звонкие шумные длительные: в, в’, з, з’, ж;
•звонкие шумные мгновенные: б, б’, д, д’, г, г’;
•глухие шумные длительные: ф, ф’, с, с’, ш, х, х’;
•глухие шумные мгновенные: п, п’, т, т’, к, к’.
По производимыми звуками акустическому впечатлению выделяют следующие группы звуков:
•свистящие: с, с’, з, з’, ц;
•шипящие: ш, ж, ч, щ;
•твердые: п, в, ш, ж, ц и др.;
•мягкие: п’, в’, ч, щ и др.
Для дальнейшего анализа проведем информационные образы звуков различных групп (см. рисунки).
Разница образов и звуков различных видов велика, что значительно облегчила бы задачу разделения звуков, если бы не присутствие нескольких затрудняющих работу факторов.
Во-первых, переход между различными звуками, как правило, осуществляется крайне плавно даже между звуками различных групп (исключение составляют некоторые взрывные согласные). Если же говорить о звуках одной группы, то становится проблематичным разделять переходные процессы от произнесения того или иного звука, например, в последовательности, воспринимаемой человеком как “иау”, звук “а” фактически полностью теряет свой обычный образ в переходе от “и” к “у”. Под влиянием “и” и “у” несколько уменьшилась частота в “а”, да и сама форма звука несколько трансформировалась.
Во-вторых, затруднительно назвать какие-либо постоянные критерии для успешного деления на звуки в связи со сложностью процесса их образования.
Вернемся к отображениям звуков и проанализируем общий вид гласных и сонарных звуков. Легко выявить некую общую закономерность, которая обусловлена происхождением звуков - звуки этих видов отдаленно напоминают реакцию некоторой системы на последовательность равноудаленных импульсов. Действительно, импульсами гласных и сонарных звуков являются колебания истинных и звуковых связок. Окончательный вид звуковые волны приобретают после прохождения через носоглотку, которая по своей сути является системой фильтров. Необходимо отметить, что изменения в напряжении истинных голосовых связок и артикуляции происходят значительно медленнее, чем колебания голосовых связок.
Заметим, что гласные и сонарные звуки состоят из участков затухания импульсов от основных (необертонных) колебаний истинных голосовых связок. Для упрощения, будем называть эти участки доменами.
Использование домен при распознавании речи вполне очевидно. По сути, домен (вспомним, что пока домен рассматривается в приложении только к сонарным и гласным звукам) содержит в себе информацию, достаточную для распознавания звука. Если взглянуть на образ протяженно произнесенной гласной (или сонарного звука), то за исключением небольших по длине участков в начале и конце образа звук состоит из домен с высокой степенью идентичности, даже для различных людей многие характеристики, а соответственно, и общий вид домен во многом схожи, что придает особую универсальность методам распознавания при выделении и распознавании фонем через домены. Еще одним достоинством домен является относительная простота их выделения. По

определению, домен начинается с максимального значения в определенном диапазоне, после которого идет затухающий по некоторому закону колебательный процесс. Как дополнительное условие, которое можно использовать при расчленении речи на домены, можно перечислить:
стабильную (в диапазоне) длину домен;
постоянную, с некоторой точностью, величину максимумов, по которой происходило вычленение домен.
Доопределим понятие домена для остальных групп звуков.
Структура звонких шумных длительных звуков крайне сходно со структурой сонарных и гласных. Основным различием является наличие шума. Появление шума строго закономерно для каждого отдельно взятого звонкого шумного длительного звука, так что принцип деления на домены остается прежним.
Будем рассматривать шумные длительные звуки как один домен. Это позволит легко выделять корень этих звуков из общего потока и облегчит их анализ.
Анализ образов шумных мгновенных (взрывных) звуков показывает наличие участков по структуре схожих с определенным для гласных и сонарных звуков понятием домена. Но наряду с совокупностью общих признаков прослеживается различие: для вышесказанных участков в шумных мгновенных звуках отсутствует та строгая идентичность домен между собой. Во всех мгновенных звуках присутствует момент, сильно облегчающих их выделение из речи - перед произнесением таких звуков наблюдается непродолжительная по меркам восприятия, но весьма значительная, в масштабах длительностей домен, пауза. Это помогает выделению домен. Поэтому в зависимости от различных алгоритмов выделения может быть удобно разбивать такого рода звуки на несколько домен или же воспринимать их целиком, как один.
При разбиении потока речи на домены мы получаем еще один уровень в распознавании. В общей иерархии он находится еще ниже, чем уровень распознавания домен. Рассмотрим функционирование такой системы.
Процесс распознавания начинается с поступления системы данных об образе речи. В зависимости от того как поступает информация в систему, непрерывно поступающий поток или же уже отдельные пакеты (например, слова), построен алгоритм деления. Если в распоряжении данного уровня распознавания имеется слово целиком, то работу можно описать следующим образом.
Сначала производится предварительный анализ полученного блока данных, результатом которого должно являться выделение участков шумов для распознавания глухих шумных длительных звуков и выделения домена взрывных звуков. Выделенные участки помечаются. Далее производится поиск максимумов среди нулей первых производных. Определяется список экстремумов в диапазонах. Далее проводятся проверки на плавное изменение длительности домен и значение экстремумов, что служит критерием отбора домен.
Полученный список уже готов для передачи на уровень распознавания фонем по информационному потоку, деленному на домены, однако возможно и желательно введение дополнительных проверок и формирование вспомогательной информации для упрощения распознавания фонем. На уровне распознавания фонем происходит конкретизация взрывных и глухих шумных длительных звуков. Далее производится работа по селекции переходных домен и домен, по которым будет производиться основная работа по распознаванию фонем.
Обобщенно говоря, уровень деления на домены было бы точнее назвать некоторым подуровнем в распознавании фонем, так как здесь не происходит преобразование вида информационного. Однако, по своей сути процесс выделения домен сложен и многопланен, поэтому он может рассматриваться отдельно, со своими внутренними подсистемами и совокупностью данных.
Некоторые части рассмотренных алгоритмов и способов распознавания удобнее реализовать на аппаратном уровне. Вполне достаточно системы на основе процессора 486 DX4-100/8Мб ОЗУ. При использовании аппаратных средств реализации , например, процессора ASP, входящего в комплект поставки некоторых плат, требования к основному процессору могут быть существенно уменьшены.
По нашему мнению использование домен позволит создавать универсальные системы распознавания речи, работающие в фоновом режиме.
Впоследнее время возможности мультимедийного оборудования претерпели значительный
рост, однако этой области почему-то не уделяется достаточно внимания. Рядовой пользователь страдает от нехватки информации и вынужден учиться лишь на собственном опыте и ошибках. Этой статьей мы постараемся устранить это досадное недоразумение. Данная статья ориентирована на рядового пользователя и ставит своей целью помочь ему разобраться в теоретических и практических основах цифрового звука, выявить возможности и основные приемы его использования.
Что именно мы знаем о звуковых возможностях компьютера, кроме того, что в нашем домашнем компьютере установлена звуковая плата и две колонки? К сожалению, вероятно из-за недостаточности литературы или по каким-либо другим причинам, но пользователь, чаще всего, не знаком ни с чем, кроме встроенного в Windows микшера аудио входов/выходов и Recorder’а. Единственное использование звуковой карты, которое находит простой пользователь – это вывод звука в играх, да прослушивание коллекции аудио. А, ведь, даже самая простая на сегодняшний день звуковая плата, установленная почти в каждом компьютере, умеет намного больше - она открывает широчайшие возможности для всех, кто любит и интересуется музыкой и звуком, а для тех, кто хочет создавать свою музыку, звуковая карта может стать всемогущим инструментом. Для того чтобы узнать что же умеет компьютер в области звука нужно только поинтересоваться и перед вами откроются возможности, о которых вы, может быть, даже не догадывались. И все это не так сложно, как может показаться на первый взгляд.
Некоторые факты и понятия, без которых тяжело обойтись.
В соответствии с теорией математика Фурье, звуковую волну можно представить в виде спектра входящих в нее частот (рис. 1).