

9.2. Индексы
Основное назначение индексов состоит в обеспечении эффективного прямого доступа к кортежу отношения по ключу и последовательный просмотр в порядке возрастания или убывания значений ключа. Обычно индекс определяется для одного отношения и ключом является значение атрибута (возможно, составного). Если ключом индекса является возможный ключ отношения, то индекс должен обладать свойством уникальности, т.е. не содержать дубликатов ключа.
Общей идеей любой организации индекса является хранение упорядоченного списка значений ключа с привязкой к каждому значению ключа списка идентификаторов кортежей. Различные способы организации индекса отличаются друг от друга, главным образом, способом поиска ключа с заданным значением.
Наиболее популярным подходом к организации индексов в базах данных является использование техники бинарных деревьев (B-деревьев).
В-деревья можно построить на основе неплотных или плотных индексов.
Пусть основной файл F упорядочен по полю ключа K. Построим дополнительный файл FD (рис. 9.5) по правилу: 1) записи файла FD имеют формат FD(K,P), где K - поле, принимаемое значение ключа первой записи блока основного файла F; P - указатель на этот блок; 2) записи файла FD упорядочены по полю K.
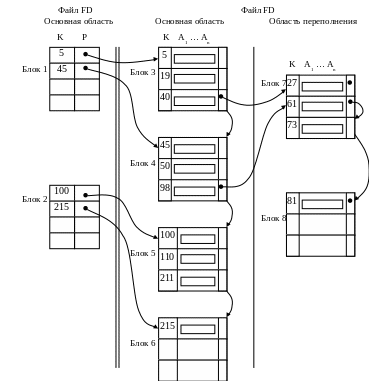
Рис. 9.5. Пример неплотного индекса
Полученный файл FD называется неплотным индексом. Количество записей файла FD равно количеству блоков основного файла F.
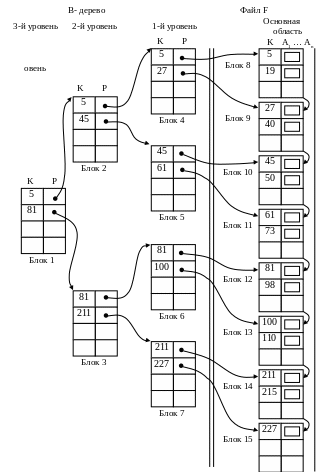
Рис. 9.6. Пример структуры типа B-дерево
Поиск вначале выполняется в индексе для нахождения адреса блока основного файла, а затем этот блок считывается в оперативную память и в нем, например, с помощью последовательного поиска определяется требуемая запись.
Так как неплотный индекс упорядочен по ключевому полю, то над ним можно построить еще один неплотный индекс и т.д., пока на самом последнем, верхнем уровне не останется всего один блок (рис. 9.6). Полученная структура называется B-деревом порядка m, где m - количество записей в блоке индекса. Такое дерево должно иметь в каждом узле не менее m/2 зависимых узлов, и все листья должны располагаться на одном уровне.
Поиск в В-дереве осуществляется так же, как и в неплотном индексе. При поиске по интервалу aKb вначале выполняется поиск по K=a в B-дереве, а затем – последовательный поиск по условию Kb в блоках первого уровня B-дерева.
Плотный индекс строится почти так же, как и неплотный индекс. Различие заключается в том, что для каждого значения ключа К в файле FD имеется отдельная запись, а в неплотном индексе – только для значения ключа первой записи блока. Над плотным индексом также можно построить B-дерево.
9.3. Журнальная информация
Одним из основных требований к развитым СУБД является надежность хранения баз данных. Это требование предполагает, в частности, возможность восстановления согласованного состояния базы данных после любого рода аппаратных и программных сбоев. Для выполнения восстановления необходима некоторая дополнительная информация, которая в большинстве современных реляционных СУБД поддерживается в виде журнала изменений базы данных.
Целью журнализации изменений баз данных является обеспечение возможности восстановления согласованного состояния базы данных после любого сбоя. Поскольку основой поддержания целостного состояния базы данных является механизм транзакций, журнализация и восстановление тесно связаны с понятием транзакции. Общими принципами восстановления являются следующие:
• результаты зафиксированных транзакций должны быть сохранены в восстановленном состоянии базы данных;
• результаты незафиксированных транзакций должны отсутствовать в восстановленном состоянии базы данных.
Это означает, что восстанавливается последнее по времени согласованное состояние базы данных.
Возможны следующие ситуации, при которых требуется производить восстановление состояния базы данных:
• индивидуальный откат транзакции;
• восстановление после внезапной потери содержимого оперативной памяти (мягкий сбой);
• восстановление после поломки основного внешнего носителя базы данных (жесткий сбой).
Во всех трех случаях основой восстановления является избыточное хранение данных. Эти избыточные данные хранятся в журнале, содержащем последовательность записей об изменении базы данных.
Возможны два основных варианта ведения журнальной информации. В первом варианте для каждой транзакции поддерживается отдельный локальный журнал изменений базы данных этой транзакцией. Эти локальные журналы используются для индивидуальных откатов транзакций и могут поддерживаться в оперативной памяти. Кроме того, поддерживается общий журнал изменений базы данных, используемый для восстановления состояния базы данных после мягких и жестких сбоев.
Этот подход позволяет быстро выполнять индивидуальные откаты транзакций, но приводит к дублированию информации в локальных и общем журналах. Поэтому чаще используется второй вариант - поддержание только общего журнала изменений базы данных, который используется и при выполнении индивидуальных откатов.