

6.2.4. Объединение моделей локальных представлений
При объединении моделей локальных представлений проектировщик может формировать конструкции, являющиеся производными по отношению к использованным в локальных представлениях. Вводимые производные конструкции должны обеспечивать непротиворечивое представление данных.
При объединении представлений используются три основополагающие концепции: идентичность, агрегация и обобщение.
Два или более элементов модели идентичны, если имеют одинаковое семантическое (смысловое) значение.
Агрегация позволяет рассматривать связь между элементами модели как новый элемент.
При объединении представлений агрегация встречается в следующих трех формах:
1. В одном представлении агрегатный объект определен как единое целое, а во втором - рассматриваются его составные части.
2. Агрегатный объект как единое целое не определен ни в одном из представлений, но в обоих представлениях рассматриваются его различные составные части.
3. Один и тот же агрегатный объект рассматривается в обоих представлениях, но составляющие различаются.
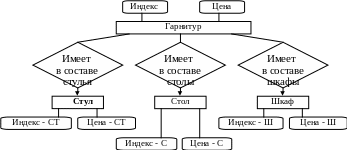
Пример. Объединению подлежат два представления (рис. 6.6, а, б). С использованием агрегации можно объединить эти представления (рис. 6.6, в).
Обобщением называется абстракция данных, позволяющая трактовать класс различных подобных типов объектов как один поименованный обобщенный тип объекта. В обобщении подчеркивается общая природа объектов.
В случае многоуровневой иерархии обобщений структура обобщения образует родовую иерархию, что приводит к появлению понятий родовой и видовой сущности. При построении обобщений вводятся смысловые категории (обычно категории типа или роли), относительно которых формируются родовые иерархии. Пример обобщения приведен на рис. 6.7.
В процессе объединения выявляются противоречия между отдельными локальными представлениями, вызванные некорректностью требований, неполнотой спецификаций, наличием возможных ошибок, различием требований в отдельных приложениях.
а)
б)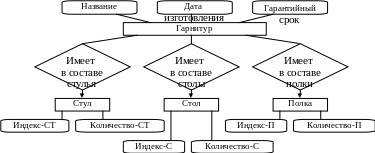
1
Рис. 6.6. Пример объединения локальных множеств с использованием агрегации
Процесс объединения носит итеративный характер и продолжается до тех пор, пока не будут интегрированы все представления, согласованы и устранены все противоречия. После завершения объединения результаты проектирования, представляющие собой концептуальную инфологическую модель ПО, оформленную в виде графических диаграмм и соответствующих спецификаций, поступают на этап даталогического проектирования БД. Сформированные спецификации вводятся в словарь данных системы.
в)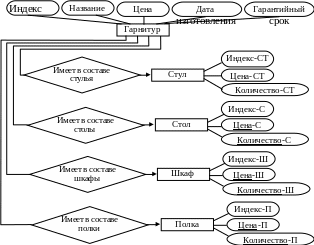
Рис.
6.6 (окончание).
Пример объединения локальных множеств
с использованием агрегации

Рис. 6.7. Пример использования обобщения
6.3. Даталогическое проектирование
Любая СУБД оперирует с допустимыми для нее логическими единицами данных, а также допускает использование определенных правил композиции логических структур более высокого уровня из составляющих информационных единиц более низкого уровня. Кроме того, многие СУБД накладывают количественные и иные ограничения на структуру базы данных. Поэтому прежде, чем приступить к построению даталогической модели, необходимо детально изучить особенности СУБД, определить факторы, влияющие на выбор проектного решения, ознакомиться с существующими методиками проектирования, а также провести анализ имеющихся средств автоматизации проектирования, возможности и целесообразности их использования.
Хотя даталогическое проектирование является проектированием логической структуры базы данных, на него оказывают влияние возможности физической организации данных, предоставляемые конкретной СУБД. Поэтому знание особенностей физической организации данных является полезным при проектировании логической структуры.
Логическая структура базы данных, а также сама заполненная данными база данных являются отображением реальной предметной области. Поэтому на выбор проектных решений самое непосредственное влияние оказывает специфика отображаемой предметной области, отраженная в инфологической модели.
Конечным результатом даталогического проектирования является описание логической структуры базы данных на ЯОД. Спроектировать логическую структуру базы данных означает определить все информационные единицы и связи между ними, задать их имена; если для информационных единиц возможно использование разных типов, то необходимо определить их тип. Следует также задать некоторые количественные характеристики, например длину поля.
Каждый тип модели данных и каждая разновидность модели, поддерживаемая конкретной СУБД, имеют свои специфические особенности. Вместе с тем имеется много общего во всех структурированных моделях данных и принципах проектирования БД в их среде. Все это дает возможность использовать единый методологический подход к проектированию структуры базы данных (что отражается в ИЛМ).
Процесс проектирования БД предусматривает предварительную классификацию объектов предметной области, систематизированное представление информации об объектах и связях между ними. На начальных этапах проектирования должен быть определен состав БД.
При проектировании логической структуры БД осуществляется преобразование исходной инфологической модели в модель данных, поддерживаемую конкретной СУБД, и проверка адекватности полученной даталогической модели отображаемой предметной области. Для любой предметной области существует множество вариантов проектных решений ее отображения в даталогической модели. Методика проектирования должна обеспечивать выбор наиболее подходящего проектного решения. Минимальная логическая единица данных семантически для всех СУБД одинакова и соответствует либо идентификатору объекта, либо свойству объекта или процесса.
Связи между сущностями предметной области, отраженные в инфологической модели, могут отображаться в даталогической модели, либо посредством совместного расположения соответствующих им информационных элементов, либо путем объявления связи между ними. Связь может передаваться как на внутризаписном, так и на межзаписном уровне.
Не все виды связей, существующие в предметной области, могут быть непосредственно отображены в конкретной даталогической модели. Так, многие СУБД не поддерживают непосредственно отношение М:М между элементами. В этом случае в даталогическую модель вводится дополнительный вспомогательный элемент, отображающий эту связь.
При проектировании логической структуры БД основное значение имеет специфика отображаемой предметной области. Однако и характер обработки информации оказывает влияние на принимаемое проектное решение. Например, рекомендуется хранить вместе информацию, часто обрабатываемую совместно и, наоборот, разделять по разным файлам информацию, не использующуюся одновременно. Информацию, используемую часто, и информацию, частота обращения к которой мала, также следует хранить в разных файлах, причем последнюю может оказаться выгодным вынести в архивные файлы, а не поддерживать в составе БД.
При переходе от инфологической модели к даталогической следует иметь в виду, что инфологическая модель включает в себя всю информацию о предметной области, необходимую и достаточную для проектирования БД. Это не означает, что все сущности, зафиксированные в ИЛМ, должны в явном виде отражаться в даталогической модели. Прежде чем строить даталогическую модель, необходимо решить, какая информация будет храниться в базе данных. Например, в инфологической модели должны быть отражены вычисляемые показатели, но вовсе не обязательно, что они должны храниться в базе данных.
Существуют разные подходы к определению состава показателей, которые должны храниться в базе данных. Согласно одному из них в БД должны храниться только исходные показатели, все производные показатели должны быть получены расчетным путем в момент реализации запроса (этот подход иногда называют принципом синтезирования, имея в виду возможность «синтезировать» требуемые показатели из хранимых в информационной базе данных).
Такой подход имеет очевидные достоинства: 1) простота и однозначность в принятии решения «что хранить»; 2) отсутствие неявного дублирования информации со всеми вытекающими из этого последствиями (меньше объем памяти, чем при хранении как исходных, так и производных показателей, проще проблемы контроля целостности данных); 3) потенциальная возможность получить любой расчетный показатель, а не только те, которые хранятся в БД.
При отображении объекта в файл базы данных идентификатор объекта будет являться полем этого файла, причем в большинстве случаев ключевым полем. Однако в некоторых случаях появляется необходимость введения искусственных идентификаторов, или, как их еще называют, кодов. Такими случаями являются следующие.
1. В предметной области может наблюдаться синонимия, т.е. может случиться, что естественный идентификатор объекта не обладает свойством уникальности. Например, среди сотрудников предприятия могут быть однофамильцы. В этом случае для обеспечения однозначной идентификации объектов ПО в информационной системе необходимо использовать искусственные коды.
2. Если объект участвует во многих связях, то для их отображения создается несколько файлов, в каждом из которых повторяется идентификатор объекта. Для того чтобы не использовать во всех файлах длинный естественный идентификатор объекта, можно ввести и использовать более короткий код. Это не только сэкономит память, но и сократит трудоемкость ввода информации.
3. Если естественный идентификатор может изменяться со временем (например, фамилия), то это может вызвать много проблем, если наряду с таким «динамическим» идентификатором не использовать «статический» искусственный идентификатор.
Когда присваиваются идентификаторы каким-либо объектам, то желательно, чтобы эти идентификаторы были постоянными.
Все шаги проектирования даталогической модели выполняются итеративно. Причем вероятны итерации не только внутри стадии даталогического проектирования, но и с «захватом» других стадий проектирования БД.