

9.1. Хранение отношений
Существуют два принципиальных подхода к физическому хранению отношений: покортежное и хранение отношения по столбцам.
При покортежном хранении отношений кортеж является единицей физического хранения. Это обеспечивает быстрый доступ к целому кортежу, но при этом во внешней памяти дублируются общие значения разных кортежей одного отношения и могут потребоваться лишние обмены с внешней памятью, если нужна часть кортежа.
При хранении отношения по столбцам единицей хранения является столбец отношения с исключенными дубликатами. При такой организации суммарно в среднем тратится меньше внешней памяти, поскольку дубликаты значений не хранятся; за один обмен с внешней памятью в общем случае считывается больше полезной информации. Дополнительным преимуществом является возможность использования значений столбца отношения для оптимизации выполнения операций соединения. Но при этом требуются существенные дополнительные действия для сборки целого кортежа (или его части). Наиболее распространено покортежное хранение отношений.
Наиболее простой формой хранения кортежей в памяти ЭВМ является одномерный линейный список. Линейный список X рассматривают как последовательность X[1], X[2], ..., X[i], ..., X[n], компоненты которой идентифицированы порядковым номером, указывающим их относительное расположение в X.
Отображение логической структуры данных на физическую структуру хранения называют адресной функцией. При реализации адресной функции используют два основных метода: последовательное и связанное распределение памяти.
При последовательном распределении памяти вектор данных логически отделен от описания структуры хранимых данных. Описание структуры хранится в отдельной записи и содержит:
N - размер вектора данных, т.е. число кортежей;
m - размер элемента списка, т.е. размер кортежа;
- адрес базы, указывающий на начало вектора данных в памяти.
В этом случае адрес каждого кортежа можно вычислить с помощью адресной функции (рис. 9.1).
(i)= +(i-1)m

Рис. 9.1. Пример последовательного распределения памяти
для представления линейного списка
При связанном распределении памяти для построения структуры необходимо задать отношения следования и предшествования элементов с помощью указателей. Указателями служат адреса, хранимые в записях данных (рис. 9.2).
Для достижения большей гибкости при работе с линейными списками в каждый узел X[i] вводится два указателя. Один реализует связь рассматриваемого узла с узлом X[i+1], а другой - с узлом X[i-1] (рис. 9.3).
Такой метод распределения памяти позволяет расширить либо сократить структуру без перемещения самих данных в памяти ЭВМ, однако при этом требуется больше памяти для хранения структуры по сравнению с последовательным распределением. Значение адресной функции можно получить только путем просмотра хранящихся указателей, а это ведет к увеличению времени поиска.
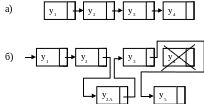
Рис. 9.2. Примеры связанных линейных списков:
а – однонаправленный список;
б – тот же список после удаления узла 4 и включения узлов 2а и 5
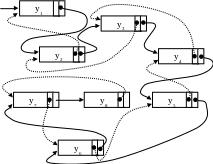
Рис. 9.3. Пример двунаправленного линейного списка
Этот недостаток можно устранить различными способами. Одним из способов является организация связанного списка с пропусками (рис. 9.4, а). Для этого линейный список делится на группы узлов, связанные между собой обратными указателями. Вначале осуществляется доступ по обратным указателям к группе, в которой находится требуемый узел, а затем по прямым указателям перебираются узлы группы, пока не будет найден требуемый узел. Вход в список при таком способе организации начинается с конца.
Другой способ заключается в построении специального дополнительного линейного списка – индекса, например, с последовательным распределением памяти. Элементы индекса – значения первых узлов каждой группы и указатели на них (рис. 9.4, б).
Р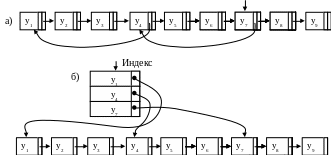 ис.
9.4. Примеры реализации способов
ускорения доступа
ис.
9.4. Примеры реализации способов
ускорения доступа
к узлам линейного списка:
а – организация линейного списка с пропусками;
б – организация линейного списка с использованием индекса
Важной разновидностью представления в памяти линейного списка является циклический список. Циклически связанный список обладает той особенностью, что связь от последнего узла идет к первому узлу списка. Циклический список позволяет получить доступ к любому узлу списка, отправляясь от любого заданного узла.
Таким образом, основой построения связанных списковых структур являются указатели. При практической реализации на ЭВМ используются три типа указателей:
1. Действительный адрес – используется тогда, когда необходимо получить наибольшую скорость обработки данных, организованных в связанные списковые структуры. Недостаток – жесткая привязка записей к конкретному месту расположения в памяти.
2. Относительный адрес – позволяет размещать записи в любом месте памяти и на различных внешних устройствах без изменения значений указателей, при этом относительное расположение в памяти узлов списка между собой должно быть постоянным. При перемещении списка указатели в записях не изменяются, а изменяется базовый адрес при вычислении действительных машинных адресов. Относительные адреса в качестве указателей применяются при страничной организации памяти. Скорость доступа к узлам несколько замедляется по сравнению со случаем машинных адресов, однако появляется возможность размещать список в любом свободном месте памяти подходящего размера.
3. Символический адрес (идентификатор) - позволяет перемещать отдельные записи относительно друг друга, включать или удалять записи в список без изменения указателей во всех остальных записях списка. Однако скорость доступа меньше, чем в первых двух случаях.
При реализации процедур поиска данных необходимо определить адрес записи по значению ключа. Для вычисления адреса чаще всего используется метод хеширования. Основная идея хеш-адресации заключается в том, что каждый экземпляр хранимой записи размещается в памяти по адресу, вычисляемому с помощью некоторой адресной функции – хеш-функции – по значению первичного ключа.
Хеш-функция h имеет не более M различных значений и удовлетворяет условию: 0h(k)<M для всех kK, т.е. для всего множества ключа, и однозначно определяет M по значению k.
В случае необходимости не обязательно организовывать записи в соответствии со значениями первичного ключа. Формально можно выполнять организацию записей по значениям любого из полей, входящих в состав записи. Недостатки хеш-адресации: хранимая структура является неупорядоченной по значению первичного ключа; возможность коллизий (ситуаций, когда для двух различных записей вычисляется один и тот же адрес памяти для хранения).