

2.8. Архитектура клиент/сервер
На высоком уровне систему баз данных можно рассматривать как систему, состоящую из двух частей – сервера (или машины базы данных) и набора клиентов (или внешнего интерфейса) (рис. 2.6) [9].
Сервер – это собственно СУБД.
Клиенты – это различные приложения, которые выполняются «над» СУБД. Они делятся на приложения, написанные пользователями, и приложения, предоставляемые поставщиками (инструментальные системы).

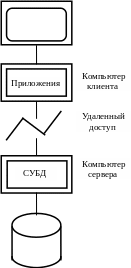
Рис 2.6. Архитектура клиент/сервер. Рис. 2.7. Клиент и сервер
запускаются на разных машинах.
Инструментальные системы делятся на несколько классов:
процессоры языков запросов;
генераторы отчетов;
графические бизнес-подсистемы;
электронные таблицы;
процессоры обычных языков;
средства управления копированием;
генераторы приложений;
другие средства разработки приложений, включая CASE-продукты (CASE или Computer-Aided Software-Engineering – автоматизация разработки программного обеспечения).
Поскольку система в целом может быть четко разделена на две части (сервер и клиенты), появляется возможность работы этих двух частей на разных машинах, т.е. существует возможность распределенной обработки (рис. 2.7).
Разные машины соединяются в коммуникационную сеть так, что одна задача обработки данных распределяется на несколько машин в сети, связь осуществляется с помощью специального программного обеспечения для управления сетью.
Преимущества распределенной обработки:
возможность параллельной обработки данных: для всей задачи применяется несколько процессоров и обработка сервера и клиента осуществляется параллельно, поэтому время ответа и производительное время должны уменьшиться;
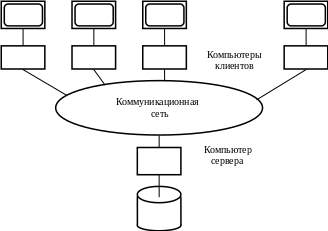
Рис. 2.8. Один сервер, много клиентов
машина сервера может быть изготовлена по специальному заказу, приспособлена для работы с СУБД и может обеспечить лучшую производительность СУБД;
машина клиента может быть персональной станцией, приспособленной к потребностям конечного пользователя;
возможность совместного использования базы данных (рис. 2.8);
выполнение сервера и клиента на отдельных машинах соответствует практической работе многих предприятий.
Машины клиентов могут иметь свои собственные сохраняемые данные, а машина сервера может иметь свои собственные приложения, т.е. каждая машина будет выступать в роли сервера для одних пользователей и в роли клиента для других, иными словами, каждая машина будет поддерживать полную систему баз данных (рис. 2.9).
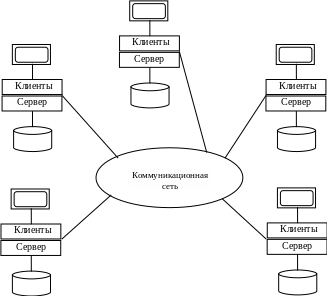
Рис. 2.9. Каждая машина одновременно является клиентом и сервером
Отдельная машина клиента может иметь доступ к нескольким разным машинам серверов. Такой доступ предоставляется двумя способами:
Клиент получает доступ к любому количеству серверов, но лишь к одному в одно и то же время.
Клиент может получать доступ к любому количеству серверов одновременно (т.е. за один запрос можно получить комбинированные данные двух или более серверов). В этом случае серверы рассматриваются клиентом как один (с логической точки зрения), и пользователь может не знать, на какой именно машине какая часть данных содержится.
Второй пример системы обычно называют распределенной системой баз данных. Полная поддержка для распределенных баз данных означает, что отдельное приложение может «прозрачно» обрабатывать данные, распределенные на множестве различных баз данных, управление которыми осуществляют разные СУБД, работающие на многочисленных машинах с различными операционными системами, соединенными вместе коммуникационными сетями. Понятие «прозрачно» означает, что приложение выполняет обработку данных с логической точки зрения, как будто управление данными полностью осуществляется одной СУБД, работающей на отдельной машине. Такая возможность может показаться невероятно трудной задачей, но весьма желанной с практической точки зрения.