

|
|
|
|
INSTRUCTION SET REFERENCE |
VPERMQ - Qwords Element Permutation |
|
|||
|
|
|
|
|
Opcode/ |
Op/ |
64/32 |
CPUID |
Description |
Instruction |
En |
-bit |
Feature |
|
|
|
Mode |
Flag |
|
VEX.256.66.0F3A.W1 00 /r ib |
A |
V/V |
AVX2 |
Permute qwords in ymm2/m256 |
VPERMQ ymm1, ymm2/m256, |
|
|
|
using indexes in imm8 and store |
imm8 |
|
|
|
the result in ymm1. |
|
|
|
|
|
Instruction Operand Encoding
Op/En |
Operand 1 |
Operand 2 |
Operand 3 |
Operand 4 |
A |
ModRM:reg (w) |
ModRM:r/m (r) |
NA |
NA |
|
|
|
|
|
Description
Use two-bit index values in the immediate byte to select a qword element in the source operand, the resultant qword value from the source operand is copied to the corresponding element of the destination operand in the order of the index field. Note that this instruction permits a qword in the source operand to be copied to multiple locations in the destination operand.
An attempt to execute VPERMQ encoded with VEX.L= 0 will cause an #UD exception.
Operation
VPERMQ (VEX.256 encoded version)
DEST[63:0] (SRC[255:0] >> (IMM8[1:0] * 64))[63:0];
DEST[127:64] (SRC[255:0] >> (IMM8[3:2] * 64))[63:0];
DEST[191:128] (SRC[255:0] >> (IMM8[5:4] * 64))[63:0];
DEST[255:192] (SRC[255:0] >> (IMM8[7:6] * 64))[63:0];
Intel C/C++ Compiler Intrinsic Equivalent
VPERMQ __m256i _mm256_permute4x64_epi64(__m256i a, int control)
SIMD Floating-Point Exceptions
None
Other Exceptions
See Exceptions Type 4; additionally
#UD |
If VEX.L = 0. |
Ref. # 319433-011 |
5-239 |
INSTRUCTION SET REFERENCE
VPERM2I128Permute Integer Values
Opcode/ |
Op/ |
64/32 |
CPUID |
Description |
Instruction |
En |
-bit |
Feature |
|
|
|
Mode |
Flag |
|
VEX.NDS.256.66.0F3A.W0 46 /r ib |
A |
V/V |
AVX2 |
Permute 128-bit integer data |
VPERM2I128 ymm1, ymm2, |
|
|
|
in ymm2 and ymm3/mem |
ymm3/m256, imm8 |
|
|
|
using controls from imm8 and |
|
|
|
|
store result in ymm1. |
Instruction Operand Encoding
Op/En |
Operand 1 |
Operand 2 |
Operand 3 |
Operand 4 |
A |
ModRM:reg (w) |
VEX.vvvv |
ModRM:r/m (r) |
NA |
|
|
|
|
|
Description
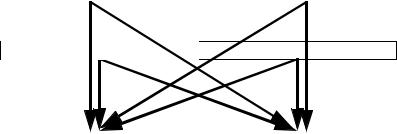
Permute 128 bit integer data from the first source operand (second operand) and second source operand (third operand) using bits in the 8-bit immediate and store results in the destination operand (first operand). The first source operand is a YMM register, the second source operand is a YMM register or a 256-bit memory location, and the destination operand is a YMM register.
SRC2 |
Y1 |
Y0 |
SRC1
|
|
|
|
|
|
|
|
|
|
|
DEST |
X0, X1, Y0, or Y1 |
X0, X1, Y0, or Y1 |
||||||||
|
|
|
|
|
|
|
|
|
|
|
Figure 5-9. VPERM2I128 Operation
5-240 |
Ref. # 319433-011 |
INSTRUCTION SET REFERENCE
Imm8[1:0] select the source for the first destination 128-bit field, imm8[5:4] select the source for the second destination field. If imm8[3] is set, the low 128-bit field is zeroed. If imm8[7] is set, the high 128-bit field is zeroed.
VEX.L must be 1, otherwise the instruction will #UD.
Operation
VPERM2I128
CASE IMM8[1:0] of
0:DEST[127:0] SRC1[127:0]
1:DEST[127:0] SRC1[255:128]
2:DEST[127:0] SRC2[127:0]
3:DEST[127:0] SRC2[255:128] ESAC
CASE IMM8[5:4] of
0:DEST[255:128] SRC1[127:0]
1:DEST[255:128] SRC1[255:128]
2:DEST[255:128] SRC2[127:0]
3:DEST[255:128] SRC2[255:128] ESAC
IF (imm8[3]) DEST[127:0] 0 FI
IF (imm8[7])
DEST[255:128] 0
FI
Intel C/C++ Compiler Intrinsic Equivalent
VPERM2I128 __m256i _mm256_permute2x128_si256 (__m256i a, __m256i b, int control)
SIMD Floating-Point Exceptions
None
Other Exceptions
See Exceptions Type 6; additionally
#UD |
If VEX.L = 0, |
|
If VEX.W = 1. |
Ref. # 319433-011 |
5-241 |
INSTRUCTION SET REFERENCE
VEXTRACTI128Extract packed Integer Values
Opcode/ |
Op/ |
64/32 |
CPUID |
Description |
Instruction |
En |
-bit |
Feature |
|
|
|
Modet |
Flag |
|
VEX.256.66.0F3A.W0 39 /r ib |
A |
V/V |
AVX2 |
Extract 128 bits of integer data |
VEXTRACTI128 |
|
|
|
from ymm2 and store results in |
xmm1/m128, ymm2, imm8 |
|
|
|
xmm1/mem. |
|
|
|
|
|
Instruction Operand Encoding
Op/En |
Operand 1 |
Operand 2 |
Operand 3 |
Operand 4 |
A |
ModRM:r/m (w) |
ModRM:reg (r) |
NA |
NA |
|
|
|
|
|
Description
Extracts 128-bits of packed integer values from the source operand (second operand) at a 128-bit offset from imm8[0] into the destination operand (first operand). The destination may be either an XMM register or a 128-bit memory location.
VEX.vvvv is reserved and must be 1111b otherwise instructions will #UD. The high 7 bits of the immediate are ignored.
An attempt to execute VEXTRACTI128 encoded with VEX.L= 0 will cause an #UD exception.
Operation
VEXTRACTI128 (memory destination form)
CASE (imm8[0]) OF
0:DEST[127:0] SRC1[127:0]
1:DEST[127:0] SRC1[255:128]
ESAC.
VEXTRACTI128 (register destination form)
CASE (imm8[0]) OF
0:DEST[127:0] SRC1[127:0]
1:DEST[127:0] SRC1[255:128]
ESAC. DEST[VLMAX:128] 0
Intel C/C++ Compiler Intrinsic Equivalent
VEXTRACTI128 __m128i _mm256_extracti128_si256(__m256i a, int offset);
5-242 |
Ref. # 319433-011 |
INSTRUCTION SET REFERENCE
SIMD Floating-Point Exceptions
None
Other Exceptions
See Exceptions Type 6; additionally
#UD |
IF VEX.L = 0, |
|
If VEX.W = 1. |
Ref. # 319433-011 |
5-243 |
INSTRUCTION SET REFERENCE
VINSERTI128Insert packed Integer values
Opcode/ |
Op/ |
64/32 |
CPUID |
Description |
Instruction |
En |
-bit |
Feature |
|
|
|
Mode |
Flag |
|
VEX.NDS.256.66.0F3A.W0 38 /r ib |
A |
V/V |
AVX2 |
Insert 128-bits of integer data |
VINSERTI128 ymm1, ymm2, |
|
|
|
from xmm3/mem and the |
xmm3/m128, imm8 |
|
|
|
remaining values from ymm2 |
|
|
|
|
into ymm1 |
|
|
|
|
|
Instruction Operand Encoding
Op/En |
Operand 1 |
Operand 2 |
Operand 3 |
Operand 4 |
A |
ModRM:reg (w) |
VEX.vvvv |
ModRM:r/m (r) |
NA |
|
|
|
|
|
Description
Performs an insertion of 128-bits of packed integer data from the second source operand (third operand) into an the destination operand (first operand) at a 128-bit offset from imm8[0]. The remaining portions of the destination are written by the corresponding fields of the first source operand (second operand). The second source operand can be either an XMM register or a 128-bit memory location.
The high 7 bits of the immediate are ignored.
VEX.L must be 1; an attempt to execute this instruction with VEX.L=0 will cause #UD.
Operation
VINSERTI128
TEMP[255:0] SRC1[255:0]
CASE (imm8[0]) OF
0:TEMP[127:0] SRC2[127:0]
1:TEMP[255:128] SRC2[127:0]
ESAC
DEST TEMP
Intel C/C++ Compiler Intrinsic Equivalent
VINSERTI128 __m256i _mm256_inserti128_si256 (__m256i a, __m128i b, int offset);
SIMD Floating-Point Exceptions
None
5-244 |
Ref. # 319433-011 |
INSTRUCTION SET REFERENCE
Other Exceptions
See Exceptions Type 6; additionally
#UD |
If VEX.L = 0, |
|
If VEX.W = 1. |
Ref. # 319433-011 |
5-245 |
INSTRUCTION SET REFERENCE
VPMASKMOVConditional SIMD Integer Packed Loads and Stores
Opcode/ |
Op/ |
64/32 |
CPUID |
Description |
Instruction |
En |
-bit |
Feature |
|
|
|
Mode |
Flag |
|
VEX.NDS.128.66.0F38.W0 8C /r |
A |
V/V |
AVX2 |
Conditionally load dword values |
VPMASKMOVD xmm1, xmm2, |
|
|
|
from m128 using mask in xmm2 |
m128 |
|
|
|
and store in xmm1 |
VEX.NDS.256.66.0F38.W0 8C /r |
A |
V/V |
AVX2 |
Conditionally load dword values |
VPMASKMOVD ymm1, ymm2, |
|
|
|
from m256 using mask in ymm2 |
m256 |
|
|
|
and store in ymm1 |
VEX.NDS.128.66.0F38.W1 8C /r |
A |
V/V |
AVX2 |
Conditionally load qword values |
VPMASKMOVQ xmm1, xmm2, |
|
|
|
from m128 using mask in xmm2 |
m128 |
|
|
|
and store in xmm1 |
VEX.NDS.256.66.0F38.W1 8C /r |
A |
V/V |
AVX2 |
Conditionally load qword values |
VPMASKMOVQ ymm1, ymm2, |
|
|
|
from m256 using mask in ymm2 |
m256 |
|
|
|
and store in ymm1 |
VEX.NDS.128.66.0F38.W0 8E /r |
B |
V/V |
AVX2 |
Conditionally store dword values |
VPMASKMOVD m128, xmm1, |
|
|
|
from xmm2 using mask in xmm1 |
xmm2 |
|
|
|
|
VEX.NDS.256.66.0F38.W0 8E /r |
B |
V/V |
AVX2 |
Conditionally store dword values |
VPMASKMOVD m256, ymm1, |
|
|
|
from ymm2 using mask in ymm1 |
ymm2 |
|
|
|
|
VEX.NDS.128.66.0F38.W1 8E /r |
B |
V/V |
AVX2 |
Conditionally store qword values |
VPMASKMOVQ m128, xmm1, |
|
|
|
from xmm2 using mask in xmm1 |
xmm2 |
|
|
|
|
VEX.NDS.256.66.0F38.W1 8E /r |
B |
V/V |
AVX2 |
Conditionally store qword values |
VPMASKMOVQ m256, ymm1, |
|
|
|
from ymm2 using mask in ymm1 |
ymm2 |
|
|
|
|
|
|
|
|
|
Instruction Operand Encoding
Op/En |
Operand 1 |
Operand 2 |
Operand 3 |
Operand 4 |
A |
ModRM:reg (w) |
VEX.vvvv |
ModRM:r/m (r) |
NA |
B |
ModRM:r/m (w) |
VEX.vvvv |
ModRM:reg (r) |
NA |
|
|
|
|
|
5-246 |
Ref. # 319433-011 |