


APPLICATION PROGRAMMING MODEL
CHAPTER 2
APPLICATION PROGRAMMING MODEL
The application programming model for AVX2 is the same as Intel AVX and FMA. The VEX-encoded general-purpose instructions generally follows legacy general-purpose instructions. They are summarized as follows:
•Section 2.1 through Section 2.8 apply to AVX2, AVX and FMA. The OS support and detection process is identical for AVX2, AVX, F16C, and FMA
•The numeric exception behavior of FMA is similar to previous generations of SIMD floating-point instructions. The specific details are described in Section 2.3.
CPUID instruction details for detecting AVX, FMA, AESNI, PCLMULQDQ, AVX2, BMI1, BMI2, LZCNT and INVPCID are described in Section 2.9.
2.1DETECTION OF PCLMULQDQ AND AES INSTRUCTIONS
Before an application attempts to use the following AES instructions: AESDEC/AESDECLAST/AESENC/AESENCLAST/AESIMC/AESKEYGENASSIST, it must check that the processor supports the AES extensions. AES extensions is supported if CPUID.01H:ECX.AES[bit 25] = 1.
Prior to using PCLMULQDQ instruction, application must check if CPUID.01H:ECX.PCLMULQDQ[bit 1] = 1.
Operating systems that support handling SSE state will also support applications that use AES extensions and PCLMULQDQ instruction. This is the same requirement for SSE2, SSE3, SSSE3, and SSE4.
2.2DETECTION OF AVX AND FMA INSTRUCTIONS
AVX and FMA operate on the 256-bit YMM register state. System software requirements to support YMM state is described in Chapter 3.
Application detection of new instruction extensions operating on the YMM state follows the general procedural flow in Figure 2-1.
Ref. # 319433-011 |
2-1 |
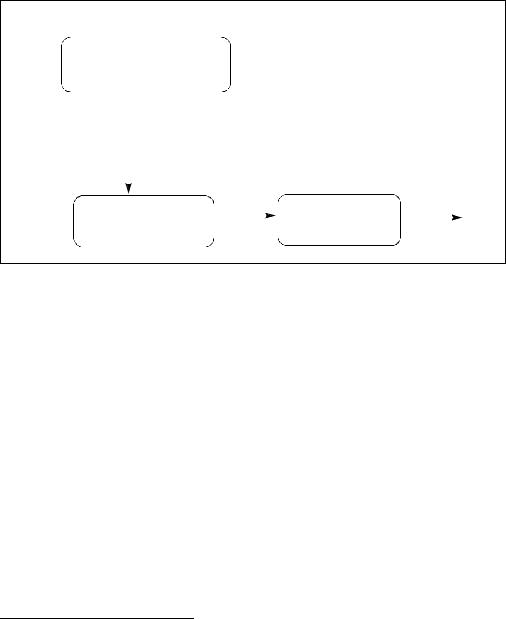
APPLICATION PROGRAMMING MODEL
Check feature flag
CPUID.1H:ECX.OXSAVE = 1?
|
OS provides processor |
|
extended state management |
Yes |
Implied HW support for |
|
XSAVE, XRSTOR, XGETBV, XFEATURE_ENABLED_MASK |
|
|
Check enabled state in |
|
Check feature flag |
|
|
|
|
|
||
XFEM via XGETBV |
State |
for Instruction set |
ok to use |
|
enabled |
|
Instructions |
||
|
|
|||
Figure 2-1. General Procedural Flow of Application Detection of AVX
Prior to using AVX, the application must identify that the operating system supports the XGETBV instruction, the YMM register state, in addition to processor’s support for YMM state management using XSAVE/XRSTOR and AVX instructions. The following simplified sequence accomplishes both and is strongly recommended.
1)Detect CPUID.1:ECX.OSXSAVE[bit 27] = 1 (XGETBV enabled for application use1)
2)Issue XGETBV and verify that XFEATURE_ENABLED_MASK[2:1] = ‘11b’ (XMM state and YMM state are enabled by OS).
3)detect CPUID.1:ECX.AVX[bit 28] = 1 (AVX instructions supported).
(Step 3 can be done in any order relative to 1 and 2)
The following pseudocode illustrates this recommended application AVX detection process:
----------------------------------------------------------------------------------------
INT supports_AVX() { ; result in eax
mov eax, 1 cpuid
1.If CPUID.01H:ECX.OSXSAVE reports 1, it also indirectly implies the processor supports XSAVE, XRSTOR, XGETBV, processor extended state bit vector XFEATURE_ENALBED_MASK register. Thus an application may streamline the checking of CPUID feature flags for XSAVE and OSXSAVE. XSETBV is a privileged instruction.
2-2 |
Ref. # 319433-011 |
APPLICATION PROGRAMMING MODEL
and ecx, 018000000H
cmp ecx, 018000000H; check both OSXSAVE and AVX feature flags jne not_supported
; processor supports AVX instructions and XGETBV is enabled by OS mov ecx, 0; specify 0 for XFEATURE_ENABLED_MASK register XGETBV; result in EDX:EAX
and eax, 06H
cmp eax, 06H; check OS has enabled both XMM and YMM state support jne not_supported
mov eax, 1 jmp done
NOT_SUPPORTED: mov eax, 0
done:
}
-------------------------------------------------------------------------------
Note: It is unwise for an application to rely exclusively on CPUID.1:ECX.AVX[bit 28] or at all on CPUID.1:ECX.XSAVE[bit 26]: These indicate hardware support but not operating system support. If YMM state management is not enabled by an operating systems, AVX instructions will #UD regardless of CPUID.1:ECX.AVX[bit 28]. “CPUID.1:ECX.XSAVE[bit 26] = 1” does not guarantee the OS actually uses the XSAVE process for state management.
These steps above also apply to enhanced 128-bit SIMD floating-pointing instructions in AVX (using VEX prefix-encoding) that operate on the YMM states. Application detection of VEX-encoded AES is described in Section 2.2.2.
2.2.1Detection of FMA
Hardware support for FMA is indicated by CPUID.1:ECX.FMA[bit 12]=1.
Application Software must identify that hardware supports AVX as explained in Section 2.2, after that it must also detect support for FMA by CPUID.1:ECX.FMA[bit 12]. The recommended pseudocode sequence for detection of FMA is:
----------------------------------------------------------------------------------------
INT supports_fma() { ; result in eax
mov eax, 1 cpuid
and ecx, 018001000H
Ref. # 319433-011 |
2-3 |
APPLICATION PROGRAMMING MODEL
cmp ecx, 018001000H; check OSXSAVE, AVX, FMA feature flags jne not_supported
; processor supports AVX,FMA instructions and XGETBV is enabled by OS mov ecx, 0; specify 0 for XFEATURE_ENABLED_MASK register
XGETBV; result in EDX:EAX and eax, 06H
cmp eax, 06H; check OS has enabled both XMM and YMM state support jne not_supported
mov eax, 1 jmp done
NOT_SUPPORTED: mov eax, 0
done:
}
-------------------------------------------------------------------------------
Note that FMA comprises of 256-bit and 128-bit SIMD instructions operating on YMM states.
2.2.2Detection of VEX-Encoded AES and VPCLMULQDQ
VAESDEC/VAESDECLAST/VAESENC/VAESENCLAST/VAESIMC/VAESKEYGENASSIST instructions operate on YMM states. The detection sequence must combine checking for CPUID.1:ECX.AES[bit 25] = 1 and the sequence for detection application support for AVX.
Similarly, the detection sequence for VPCLMULQDQ must combine checking for CPUID.1:ECX.PCLMULQDQ[bit 1] = 1 and the sequence for detection application support for AVX.
This is shown in the pseudocode:
----------------------------------------------------------------------------------------
INT supports_VAES() { ; result in eax mov eax, 1
cpuid
and ecx, 01A000000H
cmp ecx, 01A000000H; check OSXSAVE, AVX and AES feature flags jne not_supported
2-4 |
Ref. # 319433-011 |
APPLICATION PROGRAMMING MODEL
; processor supports AVX and VEX.128-encoded AES instructions and XGETBV is enabled by OS
mov ecx, 0; specify 0 for XFEATURE_ENABLED_MASK register XGETBV; result in EDX:EAX
and eax, 06H
cmp eax, 06H; check OS has enabled both XMM and YMM state support jne not_supported
mov eax, 1 jmp done
NOT_SUPPORTED: mov eax, 0
done:
}
INT supports_VPCLMULQDQ() { ; result in eax
mov eax, 1 cpuid
and ecx, 018000002H
cmp ecx, 018000002H; check OSXSAVE, AVX and PCLMULQDQ feature flags jne not_supported
; processor supports AVX and VPCLMULQDQ instructions and XGETBV is enabled by OS
mov ecx, 0; specify 0 for XFEATURE_ENABLED_MASK register XGETBV; result in EDX:EAX
and eax, 06H
cmp eax, 06H; check OS has enabled both XMM and YMM state support jne not_supported
mov eax, 1 jmp done
NOT_SUPPORTED: mov eax, 0
done:
}
-------------------------------------------------------------------------------
Ref. # 319433-011 |
2-5 |