

Прикладна економетрика - Комашко О. В
.pdfекзогенних змінних системи. Наприклад, для оцінювання функції попиту (3.5) потрібно побудувати регресію p відносно y та z:
pi = γ0 + γ1 yi + γ2 zi + εi . |
(3.11) |
Позначимо через g0, g1, g2 оцінки коефіціентів рівняння (3.11)методу найменших квадратів. Маємо
p$i = g0 + g1 yi + g2 zi . |
(3.12) |
На другому етапі замість ендогенних змінних, що входять у праву частину рівняння, підставляємо їх оцінки, знайдені на першому етапі. Одержане рівняння оцінюємо за допомогою звичайного методу найменших квадратів. У нашому прикладі будуємо регресію
qi = δ0 + δ1 p$i + δ2 yi + εi , |
(3.13) |
де p$i обчислюються за формулою (3.12). Оцінки d0, d1, d2 коефіціентів δ0, δ1, δ2
рівняння (3.13), одержані за допомогою звичайного методу найменших квадратів, є оцінками двоетапного методу найменших квадратів параметрів вихідної функції попиту (3.5). Введемо наступні позначення:
q1 |
|
1 |
p1 |
|||
q |
|
1 |
p |
|||
|
2 |
|
|
|
2 |
|
q = |
|
|
, Z = |
|
||
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
||||
qn |
1 |
pn |
||||
y1 y2 , yn
1 p$11 p$2 Z* = 1 p$n
y |
|
|
|
|
|
y1 |
|
d1 |
|
||
2 |
|
||||
|
|
, d = d |
2 |
. |
|
|
|
|
|
||
|
d3 |
|
|||
|
|||||
yn |
|
|
|
|
|
Асимптотична коваріаційна матриця оцінки d обчислюється за такою формулою:
Dd = σ$2 (ZT*Z* )−1 ,
де
σ$2 = (q − Zd)T (q − Zd)T . n
Зауваження. Для строго ідентифікованих рівнянь оцінки непрямого методу найменших квадратів і двоетапного методу найменших квадратів співпадають.

РОЗДІЛ 4. МОДЕЛІ З ОБМЕЖЕНИМИ ЗАЛЕЖНИМИ ЗМІННИМИ І МОДЕЛІ З ПАНЕЛЬНИМИ ДАНИМИ 4.1.Моделі з обмеженими залежними змінними.
4.1.1.Моделі бінарного вибору.
Припустимо, що нас цікавить, чому дана сім’я має або, навпаки, не має
автомобіль. Нехай єдиною пояснюючою змінною є |
доход. Ми зібрали дані |
|||
про n сімей (i = |
|
). Позначимо через xi доход i −ї |
сім’ї. Визначим залежну |
|
1, n |
||||
змінну y таким чином: |
|
|||
yi |
= 1, якщо i -та сім’я має автомобіль; |
|
||
yi |
= 0 , якщо i -та сім’я не має автомобіль. |
|
||
Проаналізуємо модель лінійної регресії yi = β0 + β1 xi +εi , i =1, n.
З одного боку
M (yi | xi )= β0 + βxi ,
оскільки за стандартним припущенням регресії M (εi | xi )= 0.
З іншого боку
M (yi | xi )= 1 ρ{ yi = 1| xi } + 0 ρ{ yi = 0 | xi } = ρ{ yi = 1| xi }.
Отже,
ρ{ yi = 1| xi } = β0 + βxi .
Це співвідношення показує, що модель лінійної регресії буде не реалістичною, оскільки вираз β0 + βxi не обов’язково обмежений нулем та одиницею. Крім того, виникають проблеми з властивостями збурень. Для розв’язання цієї проблеми було запропоновано підхід, так званих, латентних змінних.
Припустимо, що справжня модель має вигляд yi* = β0 + β1 xi +εi , але значення змінної y ми не спостерігаємо. Тому змінна y називається латентною.
Значення спостережень yi повязані зі значеннями латентної змінної yi* таким чином
y1 = 1, якщо yi > 0 ; yi = 0 , Якщо yi ≤ 0.
Латентну змінну можна інтерпретувати як “здібність”, “здатність”, або “схильність”. Тобто, якщо здатність або схильність придбати автомобіль (або, скажімо, в іншій моделі - повернути кредит) є додатньою, то сім’я купує автомобіль (кредит повертається, тощо). Інша можлива інтерпретаціяце різниця функції користності для двох рішень. Параметри моделі оцінюються методом максимальної правдоподібності. Позначимо через F функцію розподілу збурень і припустимо, що розподіл збурень є симетричним. Тоді
P{ yi =1} = P{ yi >0} = P{β0 + β1 xi + εi >0}
= P{εi > −(β0 + β1 xi )} = P{εi < β0 + β1 xi } = F (β0 + β1 xi ),
і
P{ yi = 0} = P{ yi ≤0} =1 − P{ yi > 0} =1 − F (β0 + β1 xi ).
Таким чином, функція правдоподібності має вигляд
L = ∏F(β0 + β1 xi )∏(1 − F(β + β1 xi )).
i: yi =1 i ; yi =0
Поки що ми визначили латентну змінну з точністю до довільної константи. Дійсно, визначимо
y = µy , де µ > 0 .
Тоді,
якщо yi > 0, то yi = 1 i якщо yi ≤ 0, то yi = 0. .
Дисперсії збурень для двох варіантів латентної змінної відрізнятимуться в µ2
разів. Тому ми можемо одозначно визначити латентну змінну, зафіксувавши її дисперсію. Найчастіше припускають, що збурення мають стандартний нормальний розподіл. Модель, яка одержується в такому випадку отримала назву моделі пробіт. Логарифм функції правдоподібності має вигляд
|
n |
|
|
β +β x |
|
x2 |
+∞ |
|
x2 |
|||
ln L(β0 , β1 )= 2π − |
|
− |
∑ |
0 |
∫i i |
e− |
|
dx − ∑ |
∫e |
− |
|
dx. |
2 |
2 |
2 |
||||||||||
|
|
|
i: yi −1 |
|
−∞ |
|
|
i: yi =0 β |
+β x |
i |
|
|
|
|
|
|
|
|
|
0 |
1 |
|
|
||
Модель логіт одержується в припущенні, що збурення мають логістичний розподіл з функцією розподілу
F (x)= |
|
ex |
. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
+ ex |
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
Логарифм функції правдоподібності має вигляд |
|
|
|||||||||||||||
|
|
|
|
|
β |
+ |
β x |
|
|
|
|
|
1 |
|
|
|
|
L(β0 ,β1 )= ∑ |
|
e 0 |
|
1 i |
|
|
|
+ ∑ |
|
|
. |
|
|
||||
|
|
β |
+β |
|
x |
|
|
|
|
|
|
||||||
|
|
i ; yi =1 1 |
+ e |
0 |
1 |
|
i |
i: yi =1 1 |
+ eβ0 +β1 xi |
|
|
||||||
Для обох моделей зручно інтерпретувати не |
βˆ 0 + βˆ 1 xi , а |
F(βˆ 0 + βˆ 1 xi ), де |
|||||||||||||||
F - відповідна функція розподілу. З виведення функції правдоподібності видно, |
|||||||||||||||||
що вираз F(βˆ 0 |
+ βˆ 1 xi ) |
є оцінкою |
імовірності |
ρ{ yi = 1 }, |
тобто оцінкою |
||||||||||||
імовірності того, сім’я матиме автомобіль, кредит буде повернуто, тощо. Внаслідок того, що функції розподілу монотонно зростають,знаки коєфіцієнтов інтерпретуються майже звичним чином. Для характеризації згоди моделі використовують декілька варіантів псевдо R2
1) |
Псевдо R |
2 |
за Амемійя R |
2 |
= 1 |
− |
|
|
|
|
1 |
; |
|
|
1 + |
2(ln L |
|
−ln L )/ n |
|||||||
|
|
|
|
|
|
|
|
|
1 |
0 |
|
|
2) |
Псевдо R2 |
за Мак Фейдом R2 |
= 1 −ln L / ln L , де |
|
||||||||
|
|
|
|
|
|
|
|
|
1 |
|
0 |
|
|
|
|
|
|
|
|
|
n |
|
|
|
|
|
ln L0 = n1 ln(n1 / n)+ (n − n1 )ln 1 − |
1 |
, де |
n1 = ∑ yi ; |
|
|||||||
|
n |
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
3) |
Псевдо R2 |
, що грунтується на коректних прогнозах. |
||||||||||
Визначимо прогнози наступним чином: |
|
|
|
|||||||||
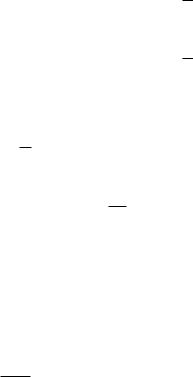
ˆyi = 1, якщо F(β0 + βxi )> 21 ; ˆyi = 0 , якщо F(β0 + βxi )≤ 21 .
Частка некоректних прогнозів дорівнює
wv1 = 1 ∑n (yi − ˆyi )2
n i =1
Позначимо через ρˆ = n1 −долю одиниць у виборці. Визначимо n2
wv0 = 1 − ρˆ , якщо ρˆ > 0,5;, wv0 = ρˆ , якщо ρˆ ≤ 0,5 .
Псевдо R2 визначається таким чином
R2 = 1 − wv1 . wv0
4.1.2.Моделі з впорядкованим відгуком.
Розглянемо вибір між M можливостями, які ми заномеруємо від 1 до M . Якщо ці можливості можна впорядкувати логічним чином (наприклад, автомобіль відсутний, один автомобіль, більш ніж один автомобіль), в такій ситуації застосовуються, так звані, моделі з впорядкованим відгуком. В основу також покладено ідею латентних змінних. Для випадку єдиної пояснюючої змінної можна записати
yi = β0 + β1 xi +εi , якщо γi −1 < yi ≤γi ,
де γ0 = −∞,γ1 = 0,γ m = +∞, а решта γ j невідомі.
В припущенні, що збурення незалежні і мають стандартний нормальний розподіл, одержується модель пробіт з впорядкованим відгуком, а якщо збурення мають логістичний розподіл, одержуємо модель пробіт з впорядкованим відгуком. При M = 2 маємо звичайні моделі. Розглянемо
приклад. Припустимо, що заміжні жінки відповідають на питання: “Скільки часу ви бажаєте працювати?” ,- причому анкета опитування містить три варіанти відповіді: “ні”, “неповний робочий тиждень”, “повний робочий тиждень”. Згідно неокласичної теорії відповідь залежить від індивідуальних переваг і бюджетного обмеження. Такими чинниками можуть бути вік, склад сім’ї, доход чоловіка, рівень освіти, тощо. Для простоти розглянемо модель з однією незалежною змінною. Будемо вважати, що залежна змінна набуває значень таким чином:
yi |
= 1, якщо відповідь “ні”; |
yi |
= 2 , якщо відповідь “неповний робочий тиждень”; |
yi |
= 3 , якщо відповідь “повний робочий тиждень”. |
Модель записується у вигляді |
|
yi = β0 + β1 xi +εi , |
|
yi |
= 1, якщо yi ≤ 0 ; |
yi |
= 2,якщо 0 < yi ≤γ ; |
yi |
= 3, якщо yi >γ *; |
εi .незалежні і мають стандартний нормальний розподіл. Латентну змінну можна проінтерпретувати як бажання працювати або як кількість робочих годин. Таким чином,
P{ yi =1| xi } = P{ yi ≤0 | xi } = F (− (β0 + β1 xi )),
P{ yi = 3 | xi } = P{ yi >γ | xi } = 1 − F (γ − (β0 + β1 xi )),
і
P{ yi = 2 | xi } = P(γ − (β0 + β1 xi ))− P(− (β0 + β1 xi )),
де F- функція розподілу для стандартного нормального розподілу. Невідомий параметр γ оцінюють методом максимальної правдоподібності разом з β і β1 .

В результаті підстановок y попередні формули x замість xi і оцінок замість параметрів одержимо оцінки ймовірностей кожної можливості, якщо значення пояснюючої змінної дорівнює x .
4.1.3.Моделі Тобіт.
Вдеяких ситуаціях залежна змінна є неперервною, але діапазон її значень
єобмеженим. Досить часто значення залежної змінної дорівнює нулю для значної частини популяції і є додатнім для решти популяції. Як приклади можна назвати витрати на товари тривалого користування, робочі години, обсяги прямих іноземних інвестицій, зроблених фірмою.
Вперше модель була запропонована Джейсоном Тобіном у 1958 році, а свою назву, Тобіт, одержала в 1964 році завдяки Артуру Голдбергу, який підкреслив її подібність до моделей пробіт. У подальшому були запропоновані різноманітні узагальнення цієї моделі. Ми розглянемо стандартну модель Тобіт або, як її іноді називають молель цензорованої регресії:
yi = β0 + β1 xi + εi , i = 1, n;,
yi |
= yi , якщо yi |
> 0; |
yi |
= 0 , якщо yi |
≤0, |
εi |
незалежні і мають розподіл N (0,σ 2 ). |
|
Латентна змінна y як правило інтерпретується як “бажала” кількість.
Логарифм функції правдоподібності має вигляд
ln L(β |
0 ,β |
|
|
|
β |
|
+ β |
x |
|
+ |
1 ,σ 2 )= ∑ ln 1 |
− F |
|
0 |
1 |
|
i |
||||
|
|
i: yi =0 |
|
|
|
|
σ |
|
|
|
|
|
1 |
|
|
1 (yi − (β0 + β1 xi |
)2 ) |
|||
+ ∑ ln |
|
exp |
− |
2 |
|
|
|
, |
|
πσ 2 |
σ |
2 |
|
||||||
i:yi =1 |
|
|
|
|
|
|
|||
|
|
2 |
|
|
|
|
|
|
|
де F-ф.р. стандартного нормального розподілу. Звернімо увагу на особливість інтерпретації регресійних коєфіцієнтів і вибіркової регресійної функції. Очікувані значення залежної змінної знаходять так:
|
|
|
|
βˆ |
+ βˆ |
x |
|
|
β |
0 |
+ β |
x |
||
M (y | x)= (βˆ |
+ βˆ |
|
x)F |
0 |
1 |
|
|
+σφ |
|
1 |
|
, |
||
|
|
σ |
|
|
|
σ |
|
|||||||
0 |
|
1 |
|
|
|
|
ˆ |
|
|
|
|
|
||
|
|
|
|
ˆ |
|
|
|
|
ˆ |
|
||||
де F- функція розподілу, а φ - щільність стандартного нормального розподілу. Граничний ефект незалежної змінної не дорівнює регресійному коєфіцієнту. За умови цензурування :
∂My |
|
|
β |
0 |
+ β |
x |
|
∂x |
= β φ |
|
1 |
|
. |
||
|
|
σ |
|
||||
1 |
|
|
|
|
|
||
Оскільки оцінки параметрів знаходяться методом максимальної правдоподібності, то знаходження коваріаційної матриці і перевірка гіпотез здійснюється в рамках звичайної для ММП схеми.

4.2. Моделі з панельними даними.
4.2.1.Переваги панельних даних.
Панельні дані або панель утворюється таким чином. Припустимо, що ми маємо N одиниць спостереження (i −1,N ), причому для кожної одиниці (особ,
домогосподарств, фірм, галузей промисловостей, країн, тощо) ми спостерігаємо
набір показників з |
T (t = 1,T ) |
періодів |
часу. Через |
yit |
Будемо позначати |
|
значення залежної |
змінної для |
i −ї в |
момент часу |
t . |
Набір |
значень K |
незалежних змінних, не включаючи константу, позначимо через |
xit ' . Лінійну |
|||||
модель можна записати у такому вигляді |
|
|
|
|
||
yit =αi + x'it β +εit , |
|
|
|
|
|
|
де β - вектор параметрів, які характеризують граничний ефект незалежних змінних на залежну. Це означає,що ефекти від зміни x однакові для всіх одиниць в усіх спостереженнях є однаковими. Але середні змінні можуть змінюватись від одиниці до одиниці. Отже, αi відображає дію факторів, які є специфічними від одиниці до одиниці, але не змінюються протягом часу. У стандартному випадку припускають, що εij незалежні й однаково розподілені з нульовим середнім і дисперсією σε2 . Якщо αi трактуються як фіксовані невідомі параметри, модель називається моделю з фіксованими ефектами, а
випадок, коли αi утворюють виборку з розподілу з середнім µ і дисперсією σα2
одержав назву моделі з випадковими ефектами. Тут важливим є припущення, що αi не залежить від xit . Моделі з панельними даними дозволяють аналізувати зміни на індивідуальному рівні. Розглянемо ситуацію, коли середній рівень споживання зростає на 2 % щорічно, або, скажімо, тим, що приблизно збільшено споживання на 4%, а у решти рівень споживання змінився. Дослідження показали, що оцінювання за панельними даними є у більшості випадків більш ефективним, у порівнянні з ситуацією, коли доступний такиий самий обсяг даних, але дані утворюються в результаті вибору різних одиниць в

кожний період часу. Моделі з панельними даними є більш стійкими по відношенню до пропущених змінних, похибок вимірювання та наявності ендогенних змінних серед регресорів.
4.2.2.Модель з фіксованими ефектами.
Модель з фіксованими ефектами є моделлю з лінійної регресії, в якій константи змінюються від одиниці до одиниці
yit |
=αi + x'it β +εii |
. |
εii |
~ i.i.d.(0,σε2 ) |
Припустимо також, що всі xit незалежні від усіх εit . Цю модель можна записати в рамках стандартної моделі регресії з використанням фіктивної змінної для кожної одиниці і в моделі
N
yit = ∑αJ dij + x'it β +εit , j =1
де dij = 1 для i = j і dij = 0 в протилежному випадку.
Отже, модель можна оцінити звичайним методом найменших квадратів, однак в цьому випадку модель міститиме велику кількість невідомих параметрів. Однак можна вчинити простіше. Можна показати, що ті ж самі оцінки β можна знайти з регресії з використанням даних у формі відхилень від середніх за одиницями. Спочатку зауважимо, що
yi =αi + x'i β +εi ,
де yi = 1 / TΣi yit ,
а решта середніх утворюються аналогічно. Далі, запишемо
yit − yi = (xit − xi )' β + (εit −εi ).
МНК-оцінка β , знайдена за цією моделю з перетвореними даними називається оцінкою з фіксованими ефектами. Позначимо їїчерез βˆ FE . Оцінки
αi знаходяться так: