

Контрольные вопросы к главе 2
1. Перечислите способы сглаживания экспериментальных данных, предусмотренных в MathCad?
2. Какая функция используется для получения регрессии отрезками полинома? Как меняется вид зависимости от параметра span?
3. В каком случае надо менять начальные условия для регрессий специального вида?
4. Можно ли в регрессии общего вида использовать больше 3 функций?
5. Если заменить в программе 5 expfit на lgsfit, то какие еще надо сделать изменения в программе?
6. Чем отличается задача сглаживания от задачи фильтрации?
7. Назовите три функции, используемые для решения задачи сглаживания в MathCad?
8. Как решают задачу фильтрации в MathCad?
Расчетная многовариантная задача № 2
По данным таблицы 2 [X,Y] многовариантной задачи № 1:
а) проведите регрессию отрезками полинома, подобрав оптимальный параметр span.
б) рассчитайте параметры аппроксимирующей нелинейной функции из «регрессий специального вида» MathCad и линейную комбинацию трех функций для регрессии общего вида. Расчетные данные занесите в таблицу:
Регрессия |
span |
|
Отрезками полинома
|
0.5 0.7 0.9 1 |
|
Экспонентой |
|
|
Логистической функцией |
||
Синусоидой |
||
Степенной функцией |
||
Общая регрессия F(x)= |
За критерий оптимальности принять минимум суммы квадратов отклонений расчетных и опытных значений функции;
г) проведите сглаживание табличных данных с помощью трех алгоритмов: “бегущих медиан”, функции Гаусса и адаптивным алгоритмом; проанализировать результаты расчета.
Варианты творческих заданий
1. Дополните программу 5 расчетом погрешностей искомых параметров а, b, c. Проведите расчет со своим вариантом данных.
2. Дополните программу 6 расчетом погрешностей искомых параметров с0, с1, с2. Проведите расчет со своим вариантом данных.
3. Проведите регрессию общего вида для своего варианта данных, предварительно сглаженных функциями supsmooth и ksmooth.
Глава 3. Интерполяция и экстраполяция
Пусть на отрезке [a,b] задана сеточная функция y i(xi) (табл. 1), которая получена табулированием сложной функции f(x) или задана экспериментально. Напомним, что задача интерполяции является частным случаем задачи аппроксимации, при этом интерполирующая функция Y(x) (в отличие от аппроксимирующей) должна точно проходить по узлам сеточной функции (рис. 1).
y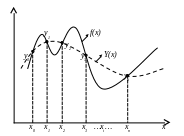
Рис. 1. Задача интерполяции
Если в качестве интерполирующей функции взять полином n-ной степени
![]() (20)
(20)
то условие прохождения интерполирующей функции по узлам (число i-тых узлов равно n+1) можно записать в виде:
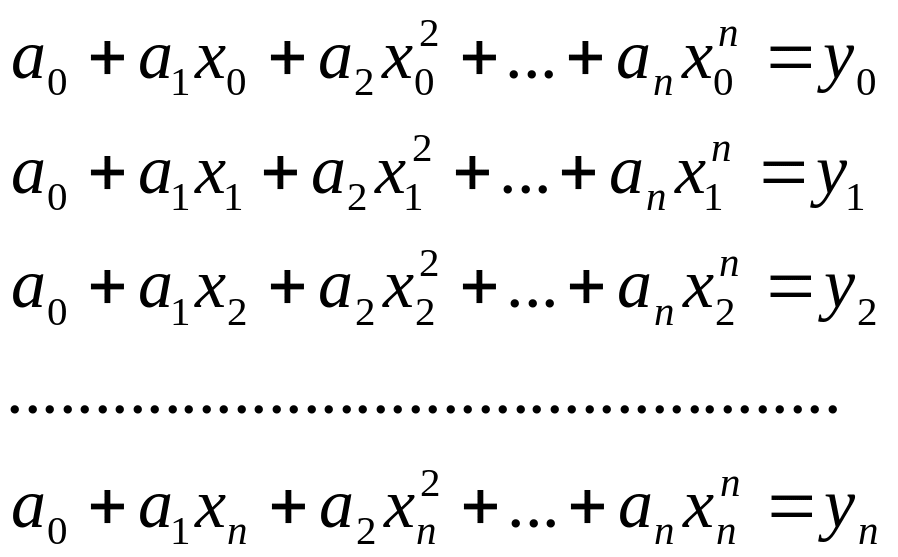 (21)
(21)
Получили
систему линейных алгебраических
уравнений (СЛАУ) из n+1
уравнений с n+1
неизвестными
![]() ,
которая имеет единственное решение:
,
которая имеет единственное решение:
A = М-1B (22)
где
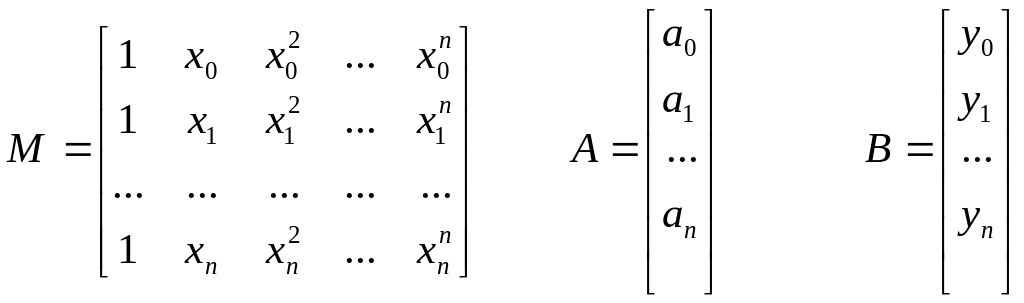
В программе 8 показано решение задачи интерполяции для набора из 6 экспериментальных точек.
Программа 8

Из текста программы видно, что интерполяционный полином проходит через узлы заданной таблицы, а любое интерполяционное значение функции можно вычислить, подставляя значение аргумента в интерполирующий полином. Как показывает практика, если количество узлов таблицы больше 7, использование полинома для интерполяции (нахождение промежуточных значений функции) становится некорректным. Интерполирующая функция, точно проходя по узлам таблицы, в промежуточных интервалах выписывает большие минимумы и максимумы, как говорят, «осциллирует» около экспериментальных данных. Поэтому для целей глобальной интерполяции полином (20) можно использовать лишь для небольшого числа данных.
Если вместо полинома (20) взять интерполяционный полином Лагранжа (23), то вычисления неизвестных параметров ai не потребуется:
![]() (23)
(23)
Вычисление интерполяционных значений по уравнению (23), (программа 9), кроме формы представления полинома не отличается от программы 8 и обладает теми же недостатками. Однако для целей локальной интерполяции полином Лагранжа используется часто.
Наиболее известны частные случаи интерполяционного полинома Лагранжа – когда n = 1 и n = 2, которые называются соответственно линейной и квадратичной интерполяцией:
![]() (24)
(24)
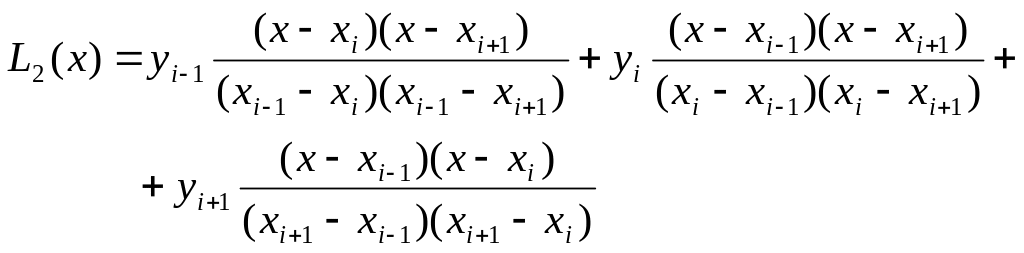 (25)
(25)
Программа 9
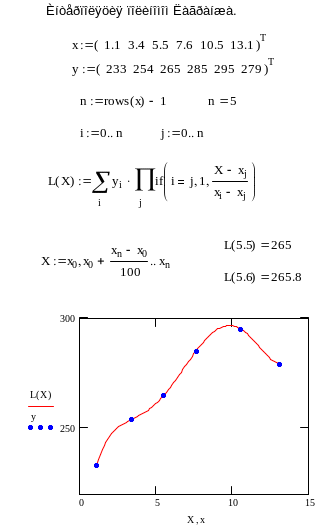
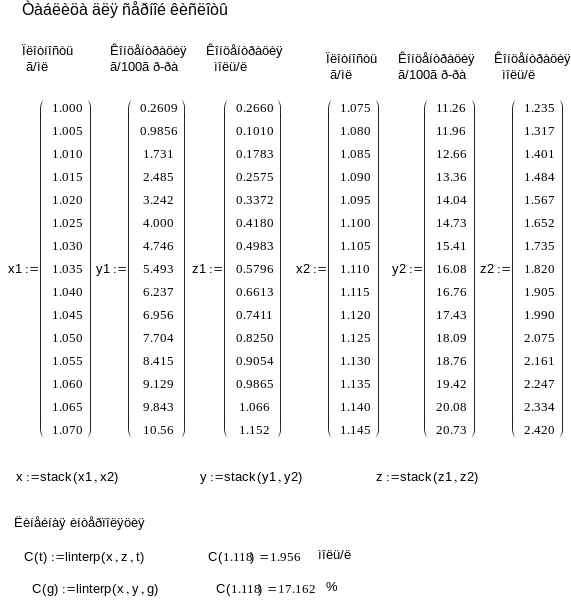
С необходимостью решения задачи интерполяции химики встречаются очень часто. Например, при приготовлении растворов кислот и щелочей необходимо пользоваться табличными данными. Пусть приготовленный раствор серной кислоты оказался плотностью 1.118 г/см3 при 20оС. Какова его молярная концентрация? Для решения этой задачи воспользуемся таблицей из справочника Лурье [8] (табл. 4).
Таблица 4
Плотности и концентрации растворов серной кислоты (фрагмент)
|
|
Плотность, г/мл при 20 оС |
Концентрация, моль/л |
… 1.105 1.110 1.115 xi x=1.118 1.120 xi+1 1.125 1.130 … |
… 1.735 1.820 1.905 yi C = ? 1.990 yi+1 2.075 2.161 … |
Плотность раствора здесь изменяется с постоянным шагом, равным 0.005 г/мл. Поэтому для нашего случая плотности, равной 1.118 г/мл значения концентрации нет. В таблице можно найти значения функции (концентрации раствора) для двух ближайших значений плотности – 1.115 г/мл и 1.120 г/мл, молярные концентрации для которых равны соответственно 1.905 М и 1.990 М. Если использовать линейную интерполяцию (24), то
![]() (26)
(26)
Задача линейной локальной интерполяции решена. Когда шаг аргумента большой, и требуется высокая точность значения аргумента, то можно использовать три ближайших узла таблицы и провести квадратичную интерполяцию по уравнению (25).
Если требуется использовать таблицу для целей интерполяции часто, то лучше один раз завести всю таблицу в MathCad и использовать встроенную функцию linterp для линейной интерполяции, как это сделано в программе 11. На экран в MathCad выводится только 15 строк таблицы, поэтому для объединения таблиц использована функция stack.
Программа 10
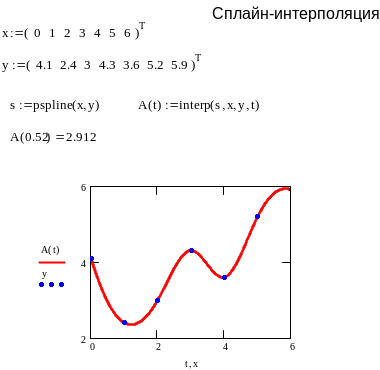
В системе MathCаd нет квадратичной интерполяции, однако в ней очень широко представлены сплайн-интерполяции.
Алгоритм сплайн-интерполяции заключается в том, что в промежутках между точками осуществляется аппроксимация в виде зависимости кубической параболой A(t)=at3 +bt2 +ct +d. Коэффициенты a,b,c,d рассчитываются независимо для каждого промежутка, исходя из значений хi,уi в соседних точках. Очевидно, что для вычисления четырех параметров нужны четыре узла. В зависимости от того, в каком промежутке находится интерполируемое значение, для интерполяции выбирается соответствующее уравнение. Поэтому интерполяция происходит с помощью двух функций – первая формирует сплайн, вторая его интерпретирует (распознает). Для формирования сплайна используются три функции:
s = lspline(x,y) s = pspline(x,y) или s = cspline(x,y)
отличающиеся методикой формирования плавных стыков между отдельными отрезками сплайна. Для использования в задаче интерполяции или для построения графика используется функция A(t) = interp(s,x,y,t) (программа 11).
Программа 11
Экстраполяция. В отличие от задачи интерполяции, в которой находят промежуточное значение функции внутри таблицы, в задаче экстраполяции ищут значение функции за пределами таблицы. Следует сразу сказать, что во многих случаях эта задача не является корректной, поскольку неизвестно будет ли выполняться закон изменения функции за пределами таблицы. Часто предполагают (с большой долей осторожности), что закон выполняется за пределами экспериментальных данных и тогда применяют либо формулы интерполяции, либо решают задачу аппроксимации и используют полученные зависимость для целей экстраполяции. Так, например, строя линейную зависимость, мы ищем отсекаемый на оси ординат отрезок с помощью линейной регрессии, то есть ищем значение у при х=0, а это значение, как правило, выходит за границы исследованных значений х, т. е. мы решаем задачу экстраполяции. Когда отсекаемый отрезок очень мал, то относительные ошибки его определения могут быть очень велики.
В MathCad имеется хорошо развитый инструмент экстраполяции, который учитывает распределение данных вдоль всего интервала значений аргумента. В функцию predict встроен линейный алгоритм предсказания поведения функции, основанный на анализе в том числе осцилляций. Синтаксис функции: predict (y,m,n), где y – вектор действительных чисел, взятых через равные промежутки значений аргумента; m – количество последовательных элементов вектора y, согласно которым строится экстраполяция; n – количество элементов вектора предсказаний. Пример использования функции предсказания приведен в [9], однако в практике анализа данных химического эксперимента функцию предсказаний практически не используют.