

Задание для самостоятельной работы
Вычислите среднее значение какого-либо показателя по всем данным файла исходных данных ("генеральное среднее").
Затем отберите 15 случайных выборок объемом 10 наблюдений и 15 случайных выборок объемом 20 наблюдений.
Постройте 70-ные и 95-ные доверительные интервалы для генерального по выборочным данным и запишите их в тетрадь (можно округлять полученные значения до десятых).
Отметьте, какие интервалы накрывают генеральное среднее, а какие нет. Сделайте выводы о точности оценки среднего в зависимости от величины доверительного коэффициента и объема выборки.
Примечание. После того, как извлечена первая случайная выборка данного объема, вновь вызовите диалоговое окно процедуры Select cases и щелкните кнопку ОК. В результате пакет отберет другую случайную выборку.
2 Лабораторная работа №2
Проверка статистических гипотез
Сравнивая описательные статистики, мы интересуемся не тем, различаются ли средние или дисперсии в двух конкретных выборках — это можно установить непосредственно, не прибегая к помощи статистики. Нас интересуют различия, существующие между исследуемыми объектами - генеральными совокупностями. Поскольку подвергнуть исследованию все наблюдения из генеральных совокупностей чаще всего не представляется возможным, мы извлекаем из них случайные выборки и пытаемся по выборочным данным оценить интересующие нас различия. Вследствие постоянного наличия флуктуаций выборочных статистик, мы не можем утверждать, что это указывает на различия в генеральных совокупностях. Поэтому нам необходим какой-то способ рассуждения, который позволит рассматривать одни различия как случайные, а другие — как свидетельство существования реальных различий между объектами (генеральными совокупностями). Такой способ называется статистическим выводом и реализуется известным нам методом проверки гипотез и интервального оценивания. Проверка статистических гипотез предполагает следующие шаги: Кратко напомним его.
1.Исследователь формулирует исходное утверждение, подлежащее эмпирической проверке. Это утверждение базируется на предыдущем опыте (результатах предшествующих эмпирических исследований, теории или догадке) и называется нулевой гипотезой. Нулевая гипотеза символически обозначается как H0. Формулируется также противоположное утверждение — альтернативная гипотеза H1. В ходе расчета критериев мы проверяем гипотезу и принимаем решение о том, какое из утверждений является верным.
Рассмотрим процесс проверки гипотез о равенстве дисперсий и средних в двух генеральных совокупностях на конкретном примере. Пусть нас интересует вопрос о том, существует ли различие между двумя участками по уровню загрязнения свинцом. Исходя из смысла поставленной задачи, формулируем нулевую гипотезу: уровень загрязнения свинцом не отличается для двух участков. Альтернативная гипотеза будет состоять в том, что такие различия существуют.
Для проверки гипотезы выберите в главном меню команду
Statistics | Compare Means | Independent-Samples T Test (Статистики | Сравнение средних | T критерий для независимых выборок). Появится следующее диалоговое окно (рис. 10):
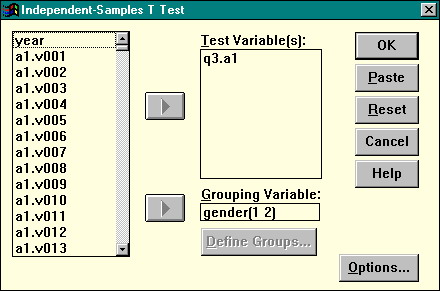
Рисунок 10. Диалоговое окно проверки одномерных гипотез
Перенесите переменную, различиями в которой мы интересуемся (содержание свинца), в список Test Variable(s), а независимую, группирующую переменную (номер участка) в поле Grouping Variable. Теперь необходимо указать процедуре, каким образом кодируется принадлежность проб к участкам. Для этого нажмите кнопку Define Groups. На экране появится диалоговое окно, в поля которого следует ввести коды, соответствующие первому и второму участкам. Введите 1 в поле Group 1 и код 2 в поле Group 2 и нажмите кнопку Continue, а затем OK. В окне распечатки вы увидите результаты работы процедуры. Заголовок t-tests for independent samples of Pb указывает на то, что в распечатке приведены результаты t-критерия Стьюдента для независимых выборок по содержанию свинца. Под заголовком приводятся описательные статистики для проверяемой переменной в каждой группе: Number of Cases (объем выборки), Mean (среднее), SD (стандартное отклонение), SE of Mean (стандартная ошибка среднего). Под таблицей с описательными статистиками приводится разница между средними двух групп (Mean Difference). Затем следует информация о проверке гипотезы равенства дисперсий по критерию Ливена (Levene's Test for Equality of Variances). Последним блоком в распечатке следуют данные о проверке гипотезы равенства средних с помощью t-критерия Стьюдента (t-test for Equality of Means). В этой таблице две строки. В первой строке приводится информация для случая, когда дисперсии двух совокупностей равны (Variances: Equal), во второй — для случая неравенства дисперсий (Unequal). В зависимости от результатов проверки гипотезы о равенстве дисперсий с помощью критерия Ливена мы выбираем одну из этих строк. В данном случае, как было установлено, дисперсии различны, и мы должны рассматривать строку Unequal.
Для проверки гипотезы о равенстве средних в таблице приводится следующая информация: значение t-критерия (t-value), степень свободы критерия (df), двухсторонняя значимость (2-Tail Sig), стандартная ошибка разности средних (SE of Diff), 95%-ный доверительный интервал для разницы средних (95% CI for Diff).
t-критерий Стьюдента можно применять в том случае, если зависимая переменная измерена в метрической шкале и имеет нормальное распределение. Такие критерии, которые предъявляют особые требования к параметрам распределения, называют параметрическими. Непараметрические критерии не накладывают столь строгих ограничений, однако именно поэтому они обладают гораздо меньшей мощностью: т.е. для отвержения нулевой гипотезы может понадобиться гораздо большая выборка.
Для проверки гипотезы о равенстве мер центральной тенденции имеется непараметрический критерий Манна-Уитни, основанный на рангах. Он может применяться в тех случаях, когда зависимая переменная измерена как минимум в шкале порядка и/или распределение не является нормальным. Для использования этого непараметрического критерия следует выбрать в меню команду Statistics | Nonparametric Tests | 2 Independent Samples.
Критерий Манна-Уитни основан на сравнении средних рангов представителей двух совокупностей. Предварительно всем испытуемым присваиваются ранги, указывающие их положение в отсортированном ряду по величине зависимой переменной. Затем вычисляются усредненные ранги для представителей каждой группы.