

6.1 Быстрый кластерный анализ
Этот метод кластерного анализа (Quick cluster), так называемый метод "К средних", реализован в пакете SPSS и базируется на достаточно простой идее. Перед проведением анализа исследователь принимает решение о том, на какое количество групп следует попытаться разбить совокупность объектов. Оно может основываться на теоретических соображениях, результатах предшествующих исследований (диаграммы рассеяния) или догадке. Выполняя последовательное разбиение на различное число кластеров, мы можем сравнивать качество получаемых решений.
Чаще всего начинают анализ, пытаясь разбить совокупность объектов на две группы, затем увеличивают их число до трех, четырех и т.д. После того, как принято решение о числе разбиений, алгоритм начинает свою работу с того, что случайным образом в пространстве назначает центры будущих кластеров. Затем вычисляется расстояние между центрами кластеров и каждым объектом, и объект приписывается к тому кластеру, к которому он ближе всего.
Завершив приписывание, алгоритм вычисляет средние значения для каждого кластера. Этих средних будет столько, сколько используется переменных для проведения анализа (К штук). Набор средних представляет собой координаты нового положения центра кластера. Алгоритм вновь вычисляет расстояние от каждого объекта до центров кластеров и приписывает объекты к ближайшему кластеру. Вновь вычисляются центры тяжести кластеров, и этот процесс повторяется до тех пор, пока центры тяжести не перестанут "мигрировать" в пространстве.
В итоге мы получим набор координат центров тяжести кластеров, сможем вычислить расстояние между ними, а также узнаем, к какому кластеру ближе всего оказался каждый из объектов.
Для проведения анализа в пакете следует выбрать в главном меню последовательность команд Statistics | Classify | K-Means Cluster. На экране появится основное окно процедуры (рис.18). Перенесите в список Variables имена К переменных (их называют "критериями классификации"). Например, на рисунке К=3. В поле Label Cases By ("пометить наблюдения с помощью") перенесите имя той переменной, которая используется в вашем исследовании в качестве идентификатора (например, переменная Name в нашем случае).
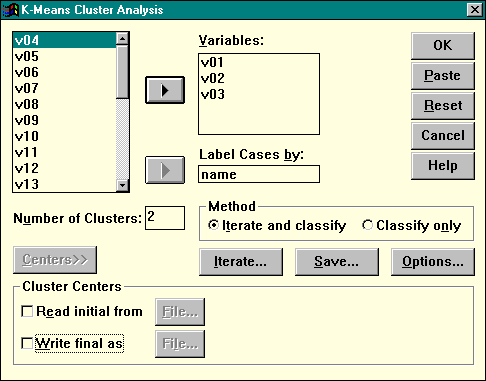
Рисунок 18. Диалоговое окно быстрого кластерного анализа
В поле Number of Clusters (число кластеров) уже по умолчанию стоит 2 — для начала это нам подходит. Кнопка Options раскрывает подчиненное окно, в котором можно заказать дополнительные параметры. Установим флажки ANOVA table (таблица дисперсионного анализа) и Cluster information for each case (информация о принадлежности каждого наблюдения к кластеру).

Рисунок 19. Диалоговое окно опций кластерного анализа
Кнопка Save вызывает дополнительное окно, в котором можно заказать сохранение двух новых переменных — принадлежность к кластеру (флажок Cluster membership) и расстояние от объекта к центру кластера (флажок Distance from cluster center). С помощью последней переменной можно определить, насколько "прототипичным" является данный объект для кластера — т.е. находится ли он на периферии (и, следовательно, вполне может быть "притянут" другим кластером) или непосредственно возле центра тяжести (т.е. является ярким примером, типичным представителем кластера).

Рисунок 20. Диалоговое окно сохранения новых переменных
Рассмотрим результаты анализа на примере данных по 14 объектам (рис.17) с двумя переменными (X, Y) - критериями классификации, и на первом этапе мы решили разбить совокупность на 2 кластера. Прежде всего, процедура выводит информацию о том, какие были выбраны координаты для исходных центров кластеров:
Initial Cluster Centers.
Cluster X Y
1 26.0000 14.0000
2 10.0000 47.0000
Затем следует блок, в котором приведены данные о возможной принадлежности объектов к одному из двух кластеров, а также евклидово расстояние от объекта до центра тяжести кластера.
Поскольку мы уже анализировали диаграмму рассеивания, нетрудно догадаться, что первый кластер (к нему отнесено 9 объектов) состоит фактически из двух групп, находящихся неподалеку друг от друга, а кластер под номером 2 (5 объектов) — это группа наблюдений, максимально удаленная от всех остальных (см. рис.17).
Case listing of Cluster membership.
NAME Cluster Distance
A 1 3.182
B 2 1.281
C 1 6.921
D 1 9.405
E 1 7.235
F 2 2.010
G 2 1.281
H 1 7.311
I 1 7.001
J 1 7.001
K 2 1.200
L 1 4.411
M 1 4.809
N 2 2.010
Второй кластер более однородный, чем первый — об этом говорят гораздо меньшие расстояния его объектов до центра, чем в первом кластере. Это логично, поскольку первый кластер составлен из двух групп, центр тяжести располагается между ними, поэтому и расстояния до центра в этом кластере значительно больше.
На следующем блоке распечатки процедура вывела координаты окончательных центров кластеров. Фактически это средние значения переменных X и Y в двух группах наблюдений:
Final Cluster Centers.
Cluster X Y
1 30.1111 19.6667
2 10.2000 45.0000
Можно классифицировать любой объект, не участвовавший в анализе, зная его значения по переменным X,Y и координаты центров: для этого надо вычислить расстояния до центра первого и второго кластеров и отнести наблюдение к ближайшему из них.
Процедура K-Means позволяет сохранять значения центров тяжести кластеров в файле данных и производить только классификацию новых наблюдений. Чтобы воспользоваться этой возможностью, необходимо нажать кнопку Centers >> в основном диалоговом окне, при анализе данных установить флажок Write final as (записать финальные координаты в файл) и указать имя файла. При проведении классификации новых наблюдений надо установить флажок Read initial from (прочесть координаты из файла), указать имя файла, в котором были сохранены координаты центров, и установить переключатель Method в положение Classify only (выполнять только классификацию).
Следующий блок распечатки содержит информацию о расстоянии между центрами тяжести кластеров. Для двух кластеров эти данные не слишком полезны, однако если число кластеров больше 2, эта таблица помогает понять, какие кластеры располагаются рядом и принять решение об окончательном числе кластеров.
Distances between Final Cluster Centers.
Cluster 1 2
1 .0000
2 32.2216 .0000
Если бы при проведении кластерного анализа мы указали 3 кластера, то получили бы такую матрицу расстояний, из которой видно, что наиболее далекими являются 1 и 3 кластеры, наиболее близкими — 1 и 3, поскольку они образовывали единую группу при двухкластерном варианте решения.
Distances between Final Cluster Centers.
Cluster 1 2 3
1 .0000
2 32.0172 .0000
3 12.6950 33.4718 .0000
Таблица результатов дисперсионного анализа помогает ответить на вопрос: какие переменные вносят наибольший вклад в разбиение совокупности объектов на кластеры. Для каждой переменной-критерия классификации приводятся данные о межгрупповой дисперсии (Cluster MS) — т.е. информация о том, насколько кластеры отличаются между собой по этой переменной, о внутригрупповой дисперсии (Error MS) — информация о вариативности объектов внутри кластера по данной переменной, F-отношение этих дисперсий (чем больше различия между кластерами и чем выше однородность объектов внутри кластеров, тем больше F-отношение), а также вероятность такого F-отношения в предположении, что на самом деле кластеры не отличаются между собой по данной переменной (Prob). Последнее значение указывает на значимость различий между кластерами.
Analysis of Variance.
Variable Cluster MS DF Error MS DF F Prob
X 1274.3111 1 15.307 12.0 83.2480 .000
Y 2062.8571 1 18.500 12.0 111.5058 .000
Как видим, обе переменные X и Y значимо отличаются в двух кластерах, и это понятно: на диаграмме рассеивания ясно видно, что внутри кластеров объекты похожи между собой (находятся на небольшом расстоянии друг от друга), в то время как расстояния между кластерами значительно больше. Обратите внимание также на то, что для переменной Y F-отношение больше, чем для X. Это также объяснимо: именно по вертикали разведение кластеров сильнее, как видно из диаграммы рассеивания.
Если принадлежность к кластерам сохранить в виде новой переменной, то можно провести дисперсионный анализ с теми признаками, которые не выступали в качестве критериев классификации. В этом случае мы получаем ценную информацию о том, объясняет ли кластерное решение различия по признакам, не принимавшим участия в построении модели. Если ответ положительный, то обнаружена действительно существующая группировка.
Наконец, в последнем блоке распечатки мы видим данные о числе объектов в каждом кластере. Заметьте, что приведена информация о невзвешенных (unweighted) и взвешенных (weighted) наблюдениях. Дело в том, что в пакете SPSS мы имеем возможность присваивать наблюдениям различный "вес" в зависимости от того, представляет ли данное наблюдение, с нашей точки зрения, типичный случай или же какое-то исключение, промежуточный вариант.
Number of Cases in each Cluster.
Cluster unweighted cases weighted cases
1 9.0 9.0
2 5.0 5.0
Missing 0
Valid cases 14.0 14.0