

Задание для самостоятельной работы:
Проведите кластерный анализ, используя в качестве данных полуколичественный спектральный анализ проб.
Попробуйте различные сочетания критериев классификации, разное число кластеров.
Обоснуйте ваше решение об окончательном числе кластеров.
Сравните наблюдения, принадлежащие разным кластерам, по другим переменным, не использовавшимся при построении модели
6.2 Иерархический кластерный анализ
Алгоритм быстрого кластерного анализа, рассмотренный в предыдущей работе, имеет ряд существенных ограничений. Прежде всего, он рассчитан на использование исключительно метрических признаков, поскольку основывается на вычислении Евклидова расстояния между объектами и центрами кластеров. Во-вторых, последовательное разбиение совокупности объектов на разное число кластеров весьма трудоемко, а решение о количестве естественных групп предполагает анализ многочисленных результатов.
От этих недостатков свободен иерархический кластерный анализ. С его помощью можно анализировать данные о сходстве и объектов и переменных, полученные разными способами и для любых шкал измерения. Кроме того, результаты анализа представляются в удобной наглядной форме, облегчающей принятие решения об оптимальном числе факторов и взаимосвязи различных разбиений.
Прежде чем перейти к обсуждению основных этапов проведения кластерного анализа, необходимо сделать несколько предостережений общего характера.
1) Многие методы кластерного анализа — довольно простые эвристические процедуры, которые, как правило, не имеют достаточного статистического обоснования.
2) Разные кластерные методы могут порождать и порождают различные решения для одних и тех же данных. Это обычное явление в большинстве прикладных исследований.
3) Цель кластерного анализа заключается в поиске существующих структур. В то же время его действие состоит в привнесении структуры в анализируемые данные, т. е. методы кластеризации могут приводить к порождению артефактов.
Исследования, использующие кластерный анализ, характеризуют следующие пять основных шагов: 1) отбор выборки для кластеризации; 2) определение множества признаков, по которым будут оцениваться объекты в выборке, и способа их стандартизации; 3) вычисление значений той или иной меры сходства между объектами; 4) применение метода кластерного анализа для создания групп сходных объектов; 5) проверка достоверности результатов кластерного решения.
Для вызова процедуры иерархического кластерного анализа выберите в главном меню последовательность пунктов Statistics | Classify | Hierarchical Cluster. Основное окно процедуры показано ниже (рис. 21).
Иерархический кластерный анализ может использоваться для построения как типологии объектов, так и классификации переменных. Поэтому первым шагом является установка значений переключателя Cluster: если кластеризации подвергаются наблюдения, оставьте его в положении Cases (“наблюдения”), в противном случае установите этот переключатель в положение Variables (“переменные”).
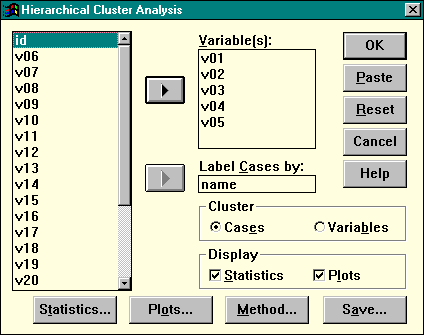
Рисунок 21. Диалоговое окно иерархического кластерного анализа
В поле Label Cases by следует перенести имя строковой переменной, с помощью значений которой на графике можно идентифицировать отдельные наблюдения. Если классифицируются переменные, данное поле становится недоступным.
При кластеризации наблюдений меры сходства вычисляются на основании тех переменных, которые помещены в список Variables. Эти переменные называются критериями кластеризации. От их выбора непосредственным образом зависит, какие объекты окажутся похожими, а какие — непохожими. Основная проблема состоит в том, чтобы найти ту совокупность переменных, которая наилучшим образом отражает сходство объектов. В идеале базисом для разумного выбора переменных, необходимых в исследовании, должна быть теория. Искушение скатиться к наивному эмпиризму в использовании кластерного анализа очень сильно, так как метод специально создан для получения "объективной" группировки объектов. Под "наивным эмпиризмом" понимается отбор и последующий анализ как можно большего количества переменных в надежде на то, что "структура" проявится, как только будет собрано достаточное количество данных. Хотя эмпирические исследования важны для любой науки, те из них, в основе которых лежит наивный эмпиризм, опасны при применении кластерного анализа ввиду эвристической природы метода и большого числа нерешенных проблем.
Не рекомендуется использовать большое число критериев кластеризации. Чем больше переменных участвует в вычислении меры близости, тем сложнее вскрыть реальную структуру данных, поскольку не имеющие отношения к делу признаки вносят статистический "шум" и затрудняют интерпретацию полученных кластеров. Лучше начинать с 2-3 существенных признаков, постепенно добавляя новые переменные при необходимости. При таком подходе вы всегда сможете проверить свои предположения о свойствах кластеров с помощью двух- или трехмерных диаграмм рассеивания.
После того, как определен состав наблюдений и критериев кластеризации, необходимо принять решение о том, какая должна быть использована мера сходства и метод кластеризации. Нажмите кнопку Method для вызова дополнительного окна, показанного на рисунке ниже:
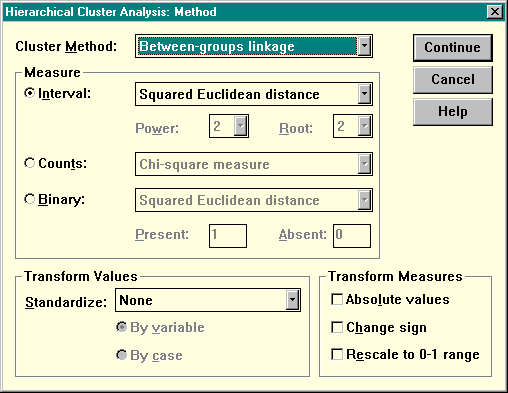
Рисунок 22. Выбор метода кластерного анализа
Прежде всего следует сказать, что в пакете SPSS не предусмотрена возможность анализа разнотипных переменных. То есть, все основания кластеризации должны относиться к одному и тому же типу:
Интервальные шкалы (Interval):
Частоты (Counts)
Дихотомические переменные (Binary)
По умолчанию установлена такая мера сходства, как квадрат Евклидова расстояния. Однако, вы можете выбрать и другие меры: коэффициент корреляции Пирсона, например, является подходящим показателем сходства профилей. Формально профиль определяется просто как вектор значений признаков объекта, графически изображаемый в виде ломаной линии.
Кронбах и Глезер (1953) впервые показали, что сходство между профилями определяют следующие три элемента:
форма, т.е. спуски и подъемы ломаной линии для всех переменных;
рассеяние, т.е. дисперсия значений переменных относительно их среднего;
поднятие (уровень или сдвиг), т.е. среднее значение для объекта по всем переменным.
Чувствительность коэффициента корреляции Пирсона лишь к форме означает, что два профиля могут иметь корреляцию +1,0, и все же не быть идентичными (т. е. профили объектов не проходят через одни и те же точки). Коэффициент Пирсона чувствителен только к форме из-за неявной нормировки каждого объекта по всем переменным.
Перед вычислением мер сходства можно выполнить их преобразование. Цель таких преобразований состоит в том, чтобы привести переменные к некоторой единой шкале, единому масштабу, что позволяет производить осмысленное сравнение объектов по разным признакам.
Метод кластеризации (называемый еще "стратегией кластеризации") определяет способ объединения объектов в кластеры. Раскрывающийся список Cluster Method позволяет выбрать один из нескольких методов: Between-groups linkage (метод средней связи), Within-groups linkage (метод минимальной связи), Nearest neighbor (метод ближайшего соседа), Furthest neighbor (метод дальнего соседа), Centroid clustering (центроидный метод), Median clustering (медианная кластеризация), Ward's method (метод Уорда).
Все перечисленные методы просматривают матрицу сходства размерностью N*N (где N — число объектов) и на каждом шаге последовательно объединяют пару наиболее схожих объектов (отдельных наблюдений или кластеров). Именно поэтому они называются алгомеративными (объединяющими). Объединение завершается формированием кластера, содержащего все объекты. Различие между методами состоит в том, каким образом осуществляется измерение расстояния. Способ измерения расстояния определяет особенности получаемых кластеров.
Например, при использовании метода ближайшего соседа объединяются те кластеры, которые имеют наименьшее расстояние между периферийными объектами. Центроидный метод определяет расстояние между кластерами как расстояние между их центрами тяжести.
Метод ближайшего соседа. Главное преимущество этого метода заключается в его математических свойствах: результаты, полученные по этому методу, инвариантны к монотонным преобразованиям матрицы сходства; применению метода не мешает наличие "совпадений" в данных. Это означает, что метод одиночной связи является одним из немногих методов, результаты применения которых не изменяются при любых преобразованиях данных, оставляющих без изменения относительное упорядочение элементов матрицы сходства. Главный недостаток метода одиночной связи, однако, состоит в том, что, как было показано на практике, метод приводит к появлению "цепочек" ("цепной эффект"), т. е. к образованию больших продолговатых кластеров. По мере приближения к окончанию процесса кластеризации образуется один большой кластер, а все остающиеся объекты добавляются к нему один за другим.
Метод дальнего соседа. В этом методе в противоположность методу одиночной связи правило объединения указывает, что сходство между кандидатами на включение в существующий кластер и любым из элементов этого кластера не должно быть меньше некоторого порогового уровня. Здесь имеется тенденция к обнаружению относительно компактных гиперсферических кластеров, образованных объектами с большим сходством.
Метод Уорда. Данный метод построен таким образом, чтобы оптимизировать минимальную дисперсию внутри кластеров. Эта целевая функция известна как внутригрупповая сумма квадратов или сумма квадратов отклонений (СКО). Метод имеет тенденцию к нахождению (или созданию) кластеров приблизительно равных размеров и имеющих гиперсферическую форму. Обычная трудность, связанная с использованием метода Уорда, заключается в том, что найденные с его помощью кластеры можно упорядочить по величине профильного сдвига.
Имеется несколько способов сравнения различных иерархических агломеративных методов. С помощью одного из них можно проанализировать, как эти методы преобразуют соотношения между точками в многомерном пространстве. Сжимающие пространство методы изменяют эти соотношения, "уменьшая" пространство между любыми группами в данных. Когда очередная точка подвергается обработке таким методом, она скорее всего будет присоединена к уже существующей группе, а не послужит началом нового кластера. Расширяющие пространство методы действуют противоположным образом. Здесь кластеры как бы "расступаются"; образуя в пространстве мелкие, более "отчетливые" кластеры. Этот способ группировки также склонен к созданию кластеров гиперсферической формы и приблизительно равных размеров. Методы Уорда и полных связей являются методами, расширяющими пространство.
К методам, сохраняющим пространство, относятся такие методы, которые оставляют без изменения свойства исходного пространства (например, метод средней связи). В результате работы этих кластерных методов получаются неперекрывающиеся кластеры, которые, однако, являются вложенными в том смысле, что каждый кластер может рассматриваться как элемент другого, более широкого кластера на более высоком уровне сходства.
Процесс слияния объектов фиксируется в специальной таблице объединения (Agglomeration Schedule). Ниже приведена такая таблица для данных примера предыдущей работы:
Agglomeration Schedule using Average Linkage (Between Groups)
Clusters Combined Stage Cluster 1st Appears Next
Stage Cluster 1 Cluster 2 Coefficient Cluster 1 Cluster 2 Stage
1 3 4 .000000 0 0 5
2 10 14 2.000000 0 0 6
3 11 12 2.000000 0 0 9
4 7 8 2.000000 0 0 8
5 2 3 2.000000 0 1 7
6 10 13 5.000000 2 0 9
7 2 5 5.000000 5 0 11
8 6 7 7.000000 0 4 10
9 10 11 8.333333 6 3 13
10 6 9 14.333333 8 0 12
11 1 2 20.250000 0 7 12
12 1 6 168.850006 11 10 13
13 1 10 1084.444458 12 9 0
Первый столбец в таблице содержит номер этапа кластеризации. Поскольку на каждом из них объединяются два объекта, число этапов (K) однозначно определяется объемом выборки (K = 2N-1). Два следующих столбца (Clusters Combined) содержат номера объединяемых кластеров. Так, на втором этапе сливаются в один кластер объекты под номерами 10 и 14. Полученному кластеру присваивается номер первого из объединяемых объектов (в данном случае 10). В столбце Coefficient приводится значение расстояния между объединяемыми кластерами. Последние два столбца (Stage Cluster 1st Appears) показывают, на каком этапе впервые появился каждый из кластеров. Нулевые значения приведены для исходных объектов, ненулевые — для кластеров, полученных их слиянием.
Самым распространенным способом наглядного представления результатов кластеризации является дендрограмма (древовидная диаграмма), которая графически изображает иерархическую структуру, порожденную матрицей сходства и правилом объединения объектов в кластеры. На следующем рисунке вы видите дендрограмму для тех же данных (рис. 23).
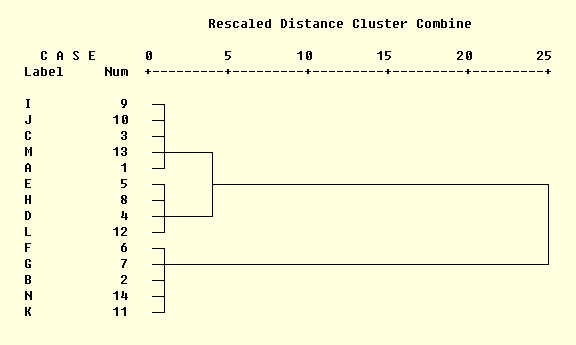
Рисунок 23. Дендрограмма результатов кластеризации.
Вверху графика изображена шкала расстояния, значения на которой всегда находятся в диапазоне от 0 (минимальное расстояние между объектами, полное сходство) до 25 (максимальное расстояние). Два столбца под общим заголовком CASE (наблюдение) содержат номера объектов и значения переменной-идентификатора (в примере объекты были обозначены буквами от A до N). В основной части диаграммы находится "дерево", показывающее наглядным образом степень сходства объектов. Так, объекты с номерами 9 10 3 13 1 5 принадлежат одному кластеру — на графике они входят в одну "гроздь" (английское слово кластер и обозначает гроздь). Продолжая вертикальную линию, их объединяющую, до шкалы измерения расстояния, мы сможем узнать степень относительной близости объектов в кластере — 1 единица. Второй кластер образуется объектами под номерами 5 8 4 12. Оба кластера затем сливаются в одну группу на уровне 4. Наконец, к ним присоединяется третий кластер на уровне 25. Как видим, дендрограмма описывает реальное соотношение объектов гораздо нагляднее, чем быстрый кластерный анализ.
Интерпретируя полученное решение, пытаются найти то общее, что характеризует объекты каждого кластера и их объединения. Для этого можно изучать и описательные статистики наблюдений в кластерах как по критериям кластеризации, так и по переменным, которые не являлись основанием для проведения анализа (внешним критериям). В итоге мы должны найти краткое название, описывающее эколого-геологическую группировку.
Кнопка Plots главного окна процедуры позволяет заказать различные формы представления результатов кластерного анализа. Установите флажок Dendrogram для вывода древовидной диаграммы. По умолчанию выводится также представление результатов кластеризации при помощи "сосулек" (icicles). На этой диаграмме (рис. 24) вдоль левого края откладывается номер этапа слияния, а вдоль верхнего — номера объектов (обратите внимание на то, что двузначные номера следует читать сверху вниз). Затемненные области соответствуют этапу слияния. Глядя на это представление, мы также видим, что выделяется три кластера (три темных сросшихся сосульки).
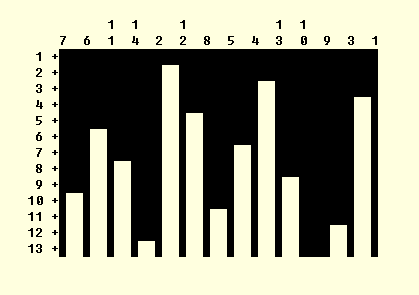
Рисунок 24. Вертикальная дендрограмма
Диалог, вызываемый кнопкой Save главного окна, дает возможность сохранить принадлежность объектов к кластерам. При этом вы можете указать, сохраняется ли одно решение (Single Solution) или диапазон решений (Range of Solutions).

Рисунок 25. Сохранение результатов кластеризации.
Когда вы выберете один из эти пунктов, станут доступны поля ввода, в которых вы сможете указать число кластеров в решении, которое необходимо сохранять. Создаваемые пакетом новые переменные представляют собой признаки, измеренные в номинальной шкале. Их значения — номера кластеров, к которым принадлежат наблюдения. Эти номинальные признаки могут в дальнейшем участвовать в других процедурах: дискриминантном анализе (в качестве независимой переменной), в дисперсионном анализе (в качестве факторов), при построении таблиц сопряженности.