

1.2 Вычисление описательных статистик
Вычисление описательных статистик в пакете SPSS возможно несколькими способами. Прежде всего, это можно сделать при помощи уже известной нам процедуры построения одномерного распределения, описанной в предыдущем пункте. В дополнительном диалоговом окне, которое вызывается кнопкой Statistics (см. рис.2) имется три группы выключателей, при помощи которых можно заказывать вывод мер положения (Central Tendency), мер вариации (Dispersion) и формы распределения (Distribution). В появившемся дополнительном диалоговом окне (рис.4) установите флажки Mean (среднее) и Std. deviation (стандартное отклонение). Переключатель Display Order (порядок вывода результатов) установите в позицию Name (по имени переменных).
Рисунок 4. Окно опций вычисления описательных статистик
Перенесите из левого списка в список Variables имена переменных, для которых следует вычислить описательные статистики. Затем щелкните кнопку Options для установки необходимых описательных статистик. Чтобы произведенные установки вступили в силу, щелкните кнопку Continue.
Можно их вычислить с помощью специальной процедуры Descriptives. Для вызова процедуры следует выбрать в главном меню последовательность команд: Statistics | Summarize | Descriptives.
Рисунок 5 Диалоговое окно расчета описательных статистик
Перенесите из левого списка в список Variables имена переменных, для которых следует вычислить описательные статистики. Затем щелкните кнопку Options для установки необходимых описательных статистик. Появится следующее диалоговое окно (рис.6):

Рисунок 6 Окно опций для вычисления описательных статистик
В появившемся дополнительном диалоговом окне установите флажки Mean (среднее) и Std. deviation (стандартное отклонение ). Переключатель Display Order (порядок вывода результатов) установите в позицию Name (по имени переменных). Чтобы произведенные установки вступили в силу, щелкните кнопку Continue.
1.3 Построение доверительного интервала для среднего
Цель любого научного исследования состоит в том, чтобы получить вывод общего характера об изучаемом явлении. Для этого необходимо было бы подвергнуть изучению каждый подобный объект, принадлежащий исследуемой генеральной совокупности. Это сделать практически невозможно. Вот почему в науке особое внимание уделяют выборочным исследованиям. С их помощью можно исследовать небольшую часть генеральной совокупности (выборку), а полученные выводы затем распространить на генеральную совокупность. Попробуем смоделировать ситуацию выборочного исследования и рассмотрим способ построения доверительных интервалов для среднего значения показателя в генеральной совокупности. Мы уже знаем, что среднее значение играет важную роль характеристики типичного значения совокупности, т.е. статистической нормы. Сравнивая каждое наблюдение с типичным, мы делаем выводы об изменчивости данного свойства, отличия от известных подобных характеристик. Поэтому очень важна наиболее точная оценка по выборочным данным неизвестного среднего в генеральной совокупности. Извлекая из неё небольшие выборки и строя по выборочным данным оценку среднего, мы сможем сравнивать получаемые оценки и предполагать реальное значение среднего. В пакете SPSS есть возможность извлечения случайных выборок. Для этого нужно в главном меню выбрать последовательность команд Data | Select Cases и в появившемя окне (рис. 7) переключатель Select (отбирать) установить в позицию Random sample of cases (случайная выборка наблюдений).
Рисунок 7. Диалоговое окно извлечения случайных выборок
После этого станет доступной кнопка Sample, с помощью которой вызывается дополнительное окно (рис. 8) для установки параметров случайного отбора. После нажатия ее в появившемся на экране окне следует задать условия отбора случайных выборок.

Рисунок 8. Дополнительное окно условий отбора выборок
Установим в этом окне переключатель Sample Size (размер выборки) в положение Exactly (отбирать точно указанное число наблюдений) и введем в первое поле 10 (объем выборки), а во второе 242 (общее число наблюдений в нашем файле данных). Нажав кнопку Continue в данном окне и кнопку OK в главном, мы установим режим отбора случайной выборки для последующих процедур анализа данных. Чтобы пользователь не забыл, в каком режиме работает пакет, в полосе состояния отображается сообщение Filter On ("фильтр включен"). Для отмены отбора наблюдений диалог необходимо вызвать еще раз и переключатель Select установить в положение All cases ("брать все наблюдения").
Если после установки фильтра вновь вызвать процедуру вычисления описательных статистик, то мы получим данные только по 10 случайно отобранным испытуемым. Кроме среднего и стандартного отклонения необходимо вычислить еще одну статистику — стандартную ошибку среднего (Standard Error of Mean — S.E.Mean). Для вычисления описательных статистик по фактору в главном меню выберем Statisics | Summarize | Descriptives, и в дополнительном диалоговом окне, вызываемом кнопкой Options установим флажки только для Mean (среднее), Std. deviation (стандартное отклонение), S.E. mean (стандартная ошибка среднего). Результаты анализа для одной из таких случайных выборок показаны на следующей распечатке:
Number of valid observations (listwise) = 10.00
Valid
Variable Mean S.E. Mean Std Dev N Label
Q4.A1 95.60 11.15 35.26 10
Как видите, среднее значение для данной выборки (95,60) отличается, хотя и не очень сильно, от вычисленного ранее среднего для генеральной совокупности всех 242 наблюдений (97,56). Другие случайные выборки могут дать и более существенные отклонения.
Выборочное среднее является наилучшей точечной оценкой среднего генеральной совокупности. Для получения интервальной оценки необходимо воспользоваться распределением Стьюдента. Он установил, что величина t, вычисляемая как разность между выборочным и генеральным средним, деленное на ошибку среднего, для малых выборок имеет распределение, связанное с нормальным. Это распределение и называется распределением Стьюдента. Существует не одно, а целое семейство распределений. Отдельные члены этого семейства отличаются один от другого значением единственного параметра, который носит название степень свободы (англ. Degree of Freedom). При возрастании степени свободы распределение Стьюдента стремится к единичному нормальному распределению и уже при DF=30 практически от него не отличается.
Для построения доверительного интервала вокруг точечной оценки среднего надо прибавить и отнять от нее некоторое число стандартных ошибок среднего (т.е. стандартных отклонений выборочного распределения статистики). Это число определяется тем, каков объем извлеченной выборки и желаемый доверительный коэффициент нашего интервала. В следующей таблице2 приведены некоторые сведения о t-распределении.
Таблица2. Параметры распределения Стьюдента
объем выборки |
степень свободы |
коэффициент 70% |
коэффициент 95% |
10 |
9 |
1.100 |
2.262 |
15 |
14 |
1.076 |
2.145 |
20 |
19 |
1.066 |
2.093 |
Так, если степень свободы равна 9, то 95% площади под кривой распределения лежит в пределах среднее плюс-минус 2,262 стандартного отклонения (если помните, в нормальном распределении 95% находится в пределах среднее плюс-минус 2 стандартных отклонения).
Таким образом, чтобы построить 95%-ный доверительный интервал для среднего в генеральной совокупности по данным принадлежащей ей выборки из 10 наблюдений, надо: от выборочного среднего отнять 2,262 ошибок среднего (получим левую границу интервала) и к выборочному среднему прибавить 2,262 ошибок среднего (правая граница интервала). Для данных из примера будем иметь 95%-ный интервал: от 95,60 — 2,262*11,15 до 95,60 + 2,262*11,15, т.е. от 70,38 до 120,8.
Часто отличие между средними по выборкам, извлеченным из одной генеральной совокупности, изображают в виде графика, показанного на следующем рисунке:
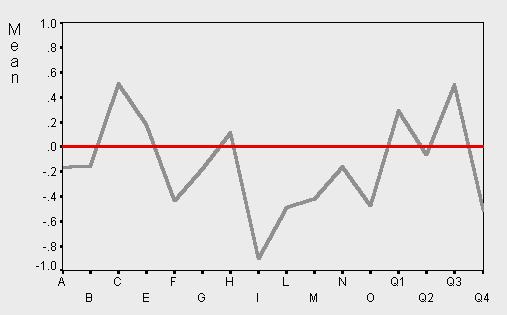
Рисунок 9. График отличия выборочных средних одной совокупности
Основной результат данной работы в получении интервала, содержащего среднее в генеральной совокупности. Обычно мы неточно не можем ответить на подобный вопрос, поскольку генеральное среднее неизвестно. Однако при моделировании его значение предполагается по результатам неоднократных выборочных расчетов. Поэтому данный полученный интервал содержит генеральное среднее.
Будет ли каждый построенный таким образом интервал заключать в себе среднее? Нет, в целом только 95% всех подобных интервалов накроют генеральное среднее. Удалось ли сделать это в каждом конкретном случае — обычно остается неизвестным.