

Тренажеры
Этот класс задач, использующих модели, применяют для выработки навыков обучения у управляющего персонала. К тренажерам близки компьютерные игры. Управление моделью в данном случае осуществляет человек-оператор, который наблюдает за выходом модели (см. рис. 20.18). Воздействуя на вход модели, оператор старается добиться нужного выходного результата, и в процессе этих действий получает необходимые навыки по управлению, которые затем может перенести на реальный объект. На рис. 20.19 показан примерный вид алгоритма реализации тренажера на базе модели.
|
||
Рис. 20.18. Схема использования модели в тренажерах |

|
||
Рис. 20.19. Типичный вид алгоритма реализации тренажера |

Разумеется, тренажер должен обладать качествами наблюдаемости и управляемость. То есть оператор в принципе может и должен судить о качестве своих действий, только наблюдая какие-то важные для себя результаты на выходе. И модель должна быть построена таким образом, чтобы можно было достичь хотя бы в принципе искомых результатов какими-то входными воздействиями на нее (управляемость).
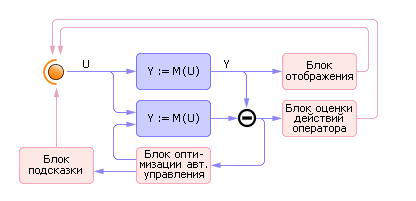
Параллельно с моделью может функционировать система оценки деятельности оператора, а также блок автоматического определения наилучших решений, которые могут в определенных режимах (например, режим обучения или подсказки) помогать оператору (см. рис. 20.20). Для этого к модели следует подключить экспертную систему, дающую рекомендации оператору в затруднительных для него случаях.
|
||
Рис. 20.20. Схема построения тренажера с функциями экспертной системы |
Для выработки устойчивых навыков у персонала в процессе тренажа в информацию вносят дополнительные помехи, имитирующие реальные сложности, возникающие на объекте. Можно вносить помехи на входе (нарушается управляемость), на выходе (нарушается наблюдаемость) или в переменные состояния модели (см. рис. 20.21). Следует различать равнодушно действующие помехи и целенаправленное противодействие. В первом случае речь идет о случайном процессе, мешающем оператору достичь цель. Случайная помеха может, как увеличить свое значение, так и равновероятно уменьшить его, то есть чаще всего среднее значение помехи на большом интервале времени равно нулю. Во втором случае речь идет о целенаправленной дезинформации оператора (среднее ее действия не равно нулю).
Для тренажа играет большую роль среднее значение и дисперсия величины помех, которые постепенно наращивают с ростом опыта оператора.
|
||
Рис. 20.21. Схема тренажера, дополненного генератором помех |

Теперь обсудим вопросы снятия и использования системных характеристик, то есть таких характеристик, которые представляют свойства системы в целом. Напомним, важнейшими понятиями для системы являются управление, помехи, цель. Системная характеристика должна связать эти понятия вместе. Методика снятия характеристик такова.
Выделяем переменные U (вход, управление) и Y (выход, цель) для исследования.
Закрепляем остальные X в виде некоторого фиксированного значения. Для каждого U из диапазона допустимых значений Umin ≤ U ≤ Umax наблюдаем и фиксируем в табл. 20.2 результат Y.
Таблица 20.2. Зависимость результата от управления при отсутствии действия помехи. Точки зависимости сняты как результат работы имитационной модели |
||||||||||||||||||
|
На графике (см. рис. 20.22) строим точку с координатами (U, Y). В результате ряда экспериментов получается кривая Y(U), которая показывает зависимость выхода от входа, цели от управления.
Обычно, если мы имеем дело моделью, отражающей сложную систему достаточно реально, с большой степенью адекватности, зависимость Y(U) должна иметь примерно такую зависимость, как показано на рис. 20.22.
|
||
Рис. 20.22. Примерный вид зависимости показателя цели от управления (ресурса), характерный для сложных систем |

ВНИМАНИЕ! Здесь приведены наиболее общие рассуждения, вид кривой может быть весьма различным!!!! На рис. 20.22 четко видны следующие закономерности.
Кривая исходит из нуля. Если не управлять, не вкладывать ресурс, не стараться, сама по себе система вряд ли выдаст тот результат, который нужен вам, который вам полезен.
Кривая нелинейна. Сначала (при малых значениях U) приложение даже небольших усилий ведет к хорошему приросту показателя цели. Далее (при больших значениях U) каждый очередной успех ΔY дается все большим усилием ΔU. Говоря математическим языком, сначала при малых U, производная ΔY/ΔU имеет большое значение, с ростом U ее значение уменьшается.
Кривая имеет затухающий характер, стремится к насыщению. Действительно, представьте, если вы вложите огромные значения ресурса (например, затратите на рекламу своей автозаправки в Перми миллиард рублей), то вряд ли получите соответствующую прибыль. Прибыль Y на этом участке U будет лимитирована уже другими факторами (наличие желающих заправиться будет не больше, чем число автовладельцев в городе, например). Реальная система рано или поздно, но выходит на определенный «предел», на «упор», насыщение.
Выделите на объекте переменную помеха Q. По смыслу эта переменная должна мешать достигать цель и не зависеть от воли владельца, управлять ею он не может.
Далее следует сменить значение Q (ранее мы считали, что оно равно 0) и провести все описанные выше действия снова (см. табл. 20.3).
Таблица 20.3. Зависимость результата от управления при повышенном уровне действия помехи. Точки зависимости сняты как результат работы имитационной модели |
||||||||||||||||||
|
И снова построить по таблице экспериментов график (см. рис. 20.23). Очевидно, что при действии возмущений Q график 2 пройдет ниже, чем график 1, поскольку наличие помехи означает, что для достижения того же эффекта Y следует приложить больше управляющих усилий U. Заметим, что менять Q во время изменения U не следует, чтобы четко видеть связь Y именно от U.
|
||
Рис. 20.23. Примерный вид зависимости показателя цели от управления (ресурса) и возмущения, характерный для сложных систем |

Важно!!! Если помеха все-таки во время снятия кривой Y(U) меняется самопроизвольно, а это бывает в том случае, когда помеха носит случайный характер, то следует для нанесения одной точки на график сначала провести несколько экспериментов при одном и том же U, а потом усреднить результат Y. Средняя величина более достоверна, чем одна из случайных реализаций. Сколько надо провести экспериментов для усреднения, чтобы обеспечить заданную точность ответа, мы обсудим с вами позднее в лекции 21 и лекции 34.
Снова увеличьте Q и снова проведите эксперименты, и снова получите новую таблицу (см. табл. 20.4) и новый график (см. рис. 20.23) — Y(U). В результате вы получите семейство кривых 1-2-3, отражающих зависимость цели, как от управления, так и от помехи.
Таблица 20.4. Зависимость результата от управления при высоком уровне действия помехи. Точки зависимости сняты как результат работы имитационной модели |
||||||||||||||||||
|
Снятие экспериментальных данных закончено. Теперь в любой момент при заданных Q и Y, используя графики 1, 2, 3, вы можете предсказать результат — необходимый для достижения цели Y уровень управления U. Такая задача, напомним, называется обратной.
Теперь, используя снятые зависимости, полезно найти наилучшие решения среди множества возможных. Для этого на каждом графике 1, 2, 3 дополнительно построим линию затрат S (spending), так как управление всегда чего-то стоит, и чем больше вы используете этот ресурс, тем больше приходится за это платить. Наклон этой линии указывает на цену ресурса (см. рис. 20.24).
|
||
Рис. 20.24. Совмещенные графики выручки от реализации цели (выручка) и затрат на ее достижение |

Примем для примера, что цена на ресурс неизменна и не зависит от того, сколько вы его используете (хотя, заметим, что бывают оптовые скидки).
Допустим, мы должны максимизировать цель Y. Тогда кривая R (receipts), выраженная в стоимостных единицах, символизирует выручку, а линия S (spending), выраженная в тех же стоимостных единицах символизирует затраты. Если вычесть из выручки затраты, то есть вычесть по точкам один график из другого (R – S), то получим в итоге прибыль P (profit): P = R – S. А именно, то, как прибыль зависит от управления (см. рис. 20.25).
|
||
Рис. 20.25. Суммарный график прибыли, полученной (выручка минус затраты) в зависимости от величины управления (ресурса) U. Наилучшее решение — максимум прибыли — точка Е1, наилучшее управление — U1 |

Очевидно, что зона B (bankrupt) — зона банкротства, точка N (null) — точка «ничего не делай и нечего не имей» и точка E1 (extremum) — зона наибольшей прибыли. Получить прибыли больше, чем Y1 при этом уровне, помех Q не удастся. Эта точка символизирует тот простой факт, что результат, достигнутый любой ценой, не окупает чрезмерных усилий по его достижению, «все хорошо в меру». Любые управляющие воздействия, даже большие, чем U1, дают худший результат.
Аналогично найдем точку E на остальных графиках 2, 3 — E2, E3.
|
||
Рис. 20.26. Графики прибыли, в зависимости от величины управления (ресурса) U и возмущения Q. Точки наилучших решений Еi — максимум прибыли. Соответствующие им наилучшие управления — Ui |

Сведем все точки E со всех трех графиков на один новый график (см. рис. 20.27).
|
||
Рис. 20.27. Итоговый график наилучших решений E по критерию прибыли Y в зависимости от величины управления (ресурса) U и возмущений Q |
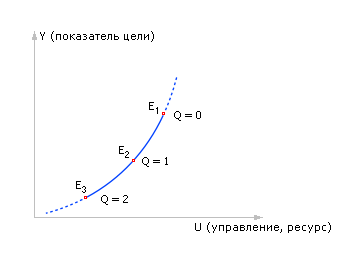
Мы получили замечательную зависимость «кривая оптимальных значений цели Y в зависимости от наилучших решений U при заданном уровне помех Q», по которой можно узнать оптимальные прилагаемые управляющие усилия, необходимые для того, чтобы достичь наилучшего в этих условиях результата. Назовем эту кривую «взаимозависимость цели, управления и помех».
На графике видно, что наибольшая достижимая возможная прибыль уменьшается от точки к точке с увеличением величины помехи — точка E смещается. Например, возможен случай, если помехи очень сильны, а ресурс имеет фиксированную цену, то, возможно, что лучше ничего не делать.
Учтя вышесказанное и возвращаясь к лекции 01 (рис. 1.9—1.10), еще раз обратим внимание, что построение и использование моделей в составе программных продуктов — перспективное новое направление в проектировании программного обеспечения. Изучение оптимальных вариантов действий по управлению предприятием должно быть обеспечено инструментами моделирования
Лекция 21. Статистическое моделирование
Статистическое моделирование — базовый метод моделирования, заключающийся в том, что модель испытывается множеством случайных сигналов с заданной плотностью вероятности. Целью является статистическое определение выходных результатов. В основе статистического моделирования лежит метод Монте-Карло. Напомним, что имитацию используют тогда, когда другие методы применить невозможно.