

Элементы математической статистики
Перед тем как приступить к решению второй половины третьей задачи, следует изучить такие понятия, как: выборка, случайные числа; случайные числа распределенные по определенному закону; эмпирические (экспериментальные) ряд и функция распределения; оценки параметров распределения; метод жребия моделирования дискретной величины; критерии Пирсона оценки достоверности гипотезы; доверительные вероятности и интервалы. Следует разобрать примеры 5.10, 5.11.
Коротко
рассмотрим, в чем заключается метод
жребия моделирования дискретной
случайной величины. Пусть событие А
может произойти с вероятностью р,
и пусть очередное значение случайного
числа – ri
(случайное число – значение непрерывной
случайной величины, равномерно
распределенной в интервале [0,1]). Если
ri
р , то оно
принадлежит интервалу
![]() ,
поэтому считаем, что событие А
наступило. Если riр,
то считается, что событие А не
наступило.
,
поэтому считаем, что событие А
наступило. Если riр,
то считается, что событие А не
наступило.
Поскольку значения случайной величины ни что иное как случайные события, процедура моделирования дискретной случайной величины с заданным законом распределения аналогична моделированию случайного события.
Пусть дискретная случайная величина задана теоретическим рядом распределения.
|
х1 |
х2 |
х3 |
… |
хn |
pi |
р(х1) |
р(х2) |
р(х3) |
… |
р(хn) |
Присваиваем
случайной величине
значение х1, если значение
случайного числа rip(х1),
значение х2, если
p(х1)<rip(х1)+p(х2),
т.е. в общем случае, если
![]() ,
то случайной величине
присваивается значение хm
.
,
то случайной величине
присваивается значение хm
.
Пример 5.10. Дискретная случайная величина задана рядом распределения, приведенным в табл. 5.3.
Таблица 5.3
хi |
0 |
5 |
10 |
15 |
pi |
0.6189 |
0.0896 |
0.2547 |
0.0368 |
1. Построить модель этой случайной величины для партии из 25 приборов (методом жребия получить её 25 значений); найти экспериментальные ряд и функцию распределения, построить их графики.
2. Найти оценки математического ожидания, дисперсии и среднего квадратического отклонения.
3. С помощью критерия Пирсона оценить соответствие экспериментального распределения теоретическому при уровнях значимости 1=0.01, 2= 0.05.
Решение.
1. Приступим к построению модели данной
случайной величины. Этот процесс будем
осуществлять методом жребия с помощью
случайных чисел rj,
т.е. значений случайной величины
равномерно распределенной в интервале
![]() .
Эти значения приведены в табл.Д Приложения.
Моделируемые значения случайной величины
обозначим Zj
(j = 1, 2, …, 25).
Заметим, что каждое из них следует
рассматривать как случайную величину.
.
Эти значения приведены в табл.Д Приложения.
Моделируемые значения случайной величины
обозначим Zj
(j = 1, 2, …, 25).
Заметим, что каждое из них следует
рассматривать как случайную величину.
Для рассматриваемой случайной величины правило моделирования заключается в том, чтобы определить какое значение будет принимать случайная величина в зависимости от попадания случайного числа в интервал.
примет значение:
0, если rj 0.6189,
5, если 0.6189 rj 0.7085,
10, если 0.7085 rj 0.9631,
15, если ri 0.9631.
Для удобства использования правило можно свести в табл. 5.4 или изобразить на рис. 5.7.
Таблица 5. 4
|
Интервал |
zj |
1 |
0;0.619 |
0 |
2 |
0.619; 0.708 |
5 |
3 |
0.708; 0.963 |
10 |
4 |
0.963; 1.000 |
15 |

 Z=0
Z=5 Z=10
Z=15
Z=0
Z=5 Z=10
Z=15
Рис. 5.7
Замечание. Поскольку в табл. 5.4 даны только 2 знака мантиссы, значения границ интервалов округлили до трех знаков после запятой.
Приступая к
моделированию ,
возьмем первое число из табл. Д Приложения.
Для того, чтобы начало было случайным,
воспользуемся днем рождения решающего
задачу. Допустим, он родился 9 марта.
Поэтому начнем с 9-й строки 3-го столбца.
Это число 67, следовательно, r1
= 0.67, оно
принадлежит второму интервалу
![]() ,
поэтому х1
= 5. Таким
образом, найдена
стоимость ремонта первого прибора.
Аналогично моделируются стоимости
остальных приборов. Далее случайные
числа будем выбирать двигаясь, например,
по строкам влево или вправо. Второе
число 43, т.е. r2 = 0.43,
оно из интервала
,
поэтому х1
= 5. Таким
образом, найдена
стоимость ремонта первого прибора.
Аналогично моделируются стоимости
остальных приборов. Далее случайные
числа будем выбирать двигаясь, например,
по строкам влево или вправо. Второе
число 43, т.е. r2 = 0.43,
оно из интервала
![]() ,
поэтому х2=0.
Сведем процесс нахождения реализаций
в табл. 5.5.
,
поэтому х2=0.
Сведем процесс нахождения реализаций
в табл. 5.5.
Таблица 5.5
j |
rj |
Интервал |
zj |
j |
rj |
Интервал |
zj |
1 |
0.67 |
0.619;0.708 |
5 |
13 |
0.35 |
0;0.619 |
0 |
2 |
0.43 |
0;0.619 |
0 |
14 |
0.98 |
0.965;1.000 |
15 |
3 |
0.97 |
0.963;1.000 |
15 |
15 |
0.95 |
0.708;0.963 |
10 |
4 |
0.04 |
0;0.619 |
0 |
16 |
0.11 |
0;0.619 |
0 |
5 |
0.43 |
0;0.619 |
0 |
17 |
0.68 |
0.6194;0.708 |
5 |
6 |
0.62 |
0.619;0.708 |
5 |
18 |
0.77 |
0.708;0.963 |
10 |
7 |
0.76 |
0.705;0.963 |
10 |
19 |
0.12 |
0;0.619 |
0 |
8 |
0.59 |
0;0.619 |
0 |
20 |
0.17 |
0;0.619 |
0 |
9 |
0.63 |
0.619;0.708 |
5 |
21 |
0.17 |
0;0.619 |
0 |
10 |
0.57 |
0;0.619 |
0 |
22 |
0.68 |
0.619;0.708 |
5 |
11 |
0.33 |
0;0.619 |
0 |
23 |
0.33 |
0;0.619 |
0 |
12 |
0.21 |
0;0.619 |
0 |
24 |
0.73 |
0.708;0.963 |
10 |
|
|
|
|
25 |
0.79 |
0.708;0.963 |
10 |
Найдем экспериментальный
ряд распределения, для чего подсчитаем
частоты mi,
равные числу приборов с данной стоимостью
ремонта, т.е. числу появлений значений
хj,
вычислим их относительные частоты, т.е.
оценки вероятностей р![]() =
=
![]() , и занесем
результаты в табл. 5.6.
, и занесем
результаты в табл. 5.6.
Таблица 5.6
xi |
0 |
5 |
10 |
15 |
|
mi |
13 |
5 |
5 |
2 |
25 |
р |
0.52 |
0.20 |
0.20 |
0.08 |
1.00 |
Найдем экспериментальную
функцию распределения F*(х)=
![]() :
:
F*(х)=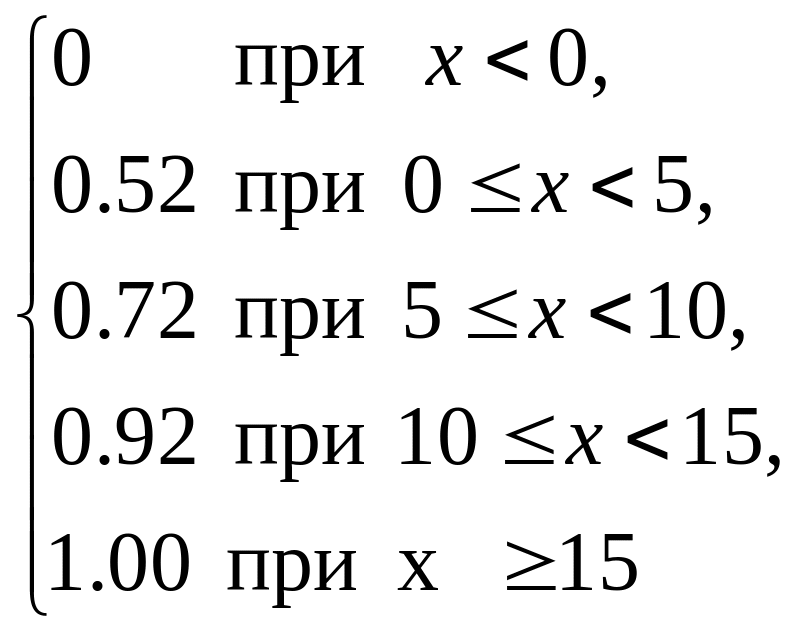 .
.
Построим экспериментальные многоугольник распределения и функцию распределения (рис. 5.8). Для наглядности сравнения теоретической и экспериментальной кривых построим штриховыми линиями теоретические кривые.
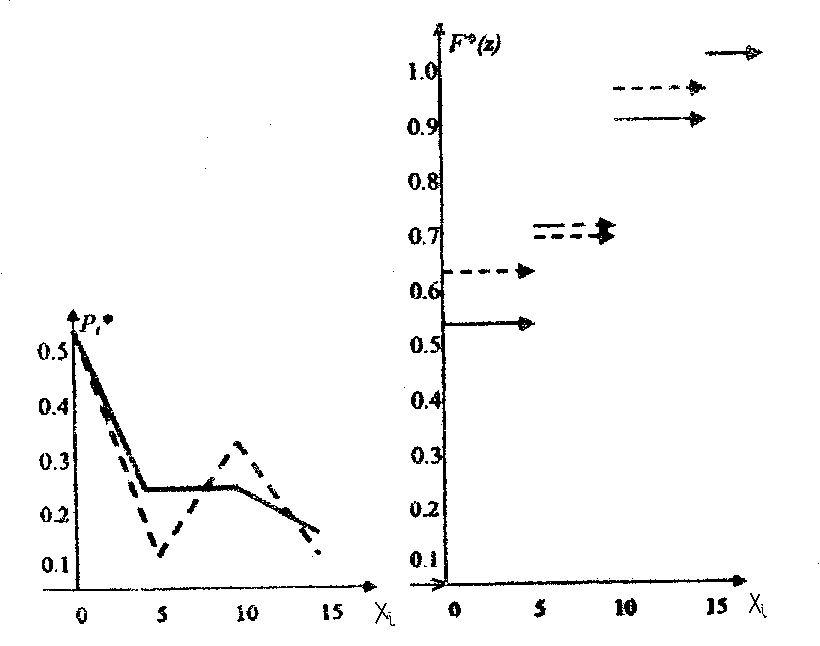
Рис. 5.8
2. Найдем оценки числовых характеристик. Для вычисления оценок математического ожидания, дисперсии и среднего квадратического отклонения воспользуемся формулами:
![]() ,
(5.8)
,
(5.8)
где k – число различных значений случайной величины;
![]() (5.9)
(5.9)
или
![]() .
(5.10)
.
(5.10)
Поскольку формулы (5.9) и (5.10) дают смещенную оценку дисперсии, несмещенную оценку найдем по формуле
![]() .
(5.11)
.
(5.11)
Замечание.
При больших значениях n
коэффициент
![]() очень близок к единице, и можно считать
оценку, вычисленную по формулам (5.9) или
(5.10), оценкой несмещенной дисперсии.
очень близок к единице, и можно считать
оценку, вычисленную по формулам (5.9) или
(5.10), оценкой несмещенной дисперсии.
Вычисления запишем в табл. 5.7.
Таблица 5.7
xi |
0 |
5 |
10 |
15 |
|
|
p |
0.52 |
0.20 |
0.20 |
0.08 |
1.00 |
|
|
0 |
1.00 |
2.00 |
1.20 |
4.20 |
= m* |
|
0 |
5.00 |
20.00 |
18.00 |
43.00 |
|
|
|
|
|
|
17.64 |
|
|
|
|
|
|
25.36 |
|
![]() ,
,
![]() .
.
Сравнив полученные результаты с теоретическими (см. пример 5.5), видим, что экспериментальные характеристики отличаются от полученных из исходного ряда распределения. Для того чтобы получить более близкие результаты, следует существенно увеличить число реализаций случайной величины (например в два раза).
3. Проверим соответствие закона распределения полученной случайной величины F * (х) заданному закону распределения F(x), используя критерий Пирсона.
Для этого определяется случайная величина
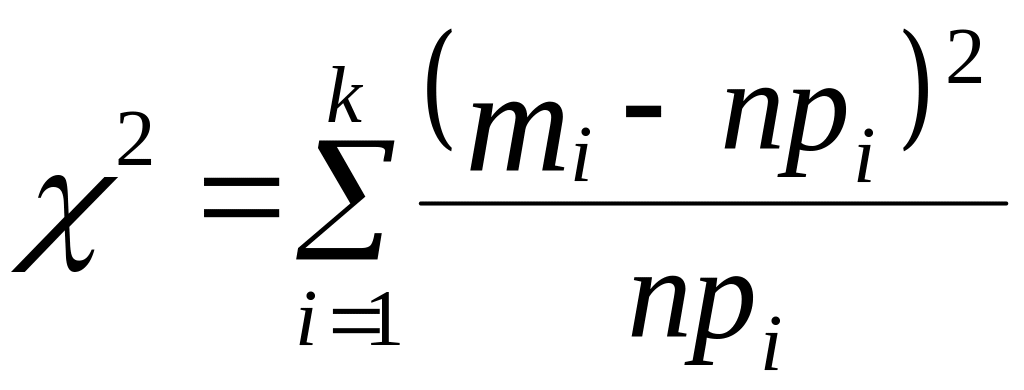 ,
,
где k – число значений случайной величины;
mi – число появлений значений случайной величины ;
pi – теоретическая вероятность значения;
n – объем моделируемой выборки (npi – ожидаемое число появлений значения хi при n реализациях случайной величины). Величина 2, называемая “хи-квадрат”, служит показателем того, насколько хорошо согласуются моделируемое и ожидаемое распределения.
В статистических
расчетах число степеней свободы для
дискретной случайной величины определяется
как r = k
–
![]() - 1, где k – число
значений слу-чайной величины,
– число параметров, которые были
вычислены по результатам наблюдений.
- 1, где k – число
значений слу-чайной величины,
– число параметров, которые были
вычислены по результатам наблюдений.
Введем понятие
«критическое значение» C
=![]() следующим образом:
следующим образом:
если при проверяемой гипотезе вероятность события {χ2.>C} мала, Р(χ2.С) = , то С называется «критическим значением», а – «уровнем значимости» критерия χ2. Уровень значимости является вероятностью отвергнуть правильную гипотезу. Выбор его определяется решаемой задачей. Как правило, полагают = 0.01 или = 0.05, т.е. в одном или пяти случаях из ста может быть отвергнута правильная гипотеза. Критические значения в зависимости от объема выборки и уровня значимости приведены в табл. С Приложения А.
В рассматриваемой задаче число k = 4, поэтому число степеней свободы
r = 4 - 1 = 3. По указанной таблице найдем критические числа С1 (для 1 = 0.01) и С2 (для 2 = 0.05): ими будут С1 = 11,3 и С2 = 7,8.
Найдем значение χ2. Все вычисления выполним в таблице 5.8 (n = 25, значение npi вычислим с точностью до одного знака после запятой).
Таблица 5.8
i |
хi |
mi |
npi |
mi- npi |
|
1 |
0 |
13 |
15.5 |
-2.5 |
0.403 |
2 |
5 |
5 |
2.2 |
2.8 |
3.536 |
3 |
10 |
5 |
6.4 |
-1.4 |
0.306 |
4 |
15 |
2 |
0.9 |
1.1 |
1.344 |
|
- |
25 |
25.0 |
0.0 |
5.617=2 |
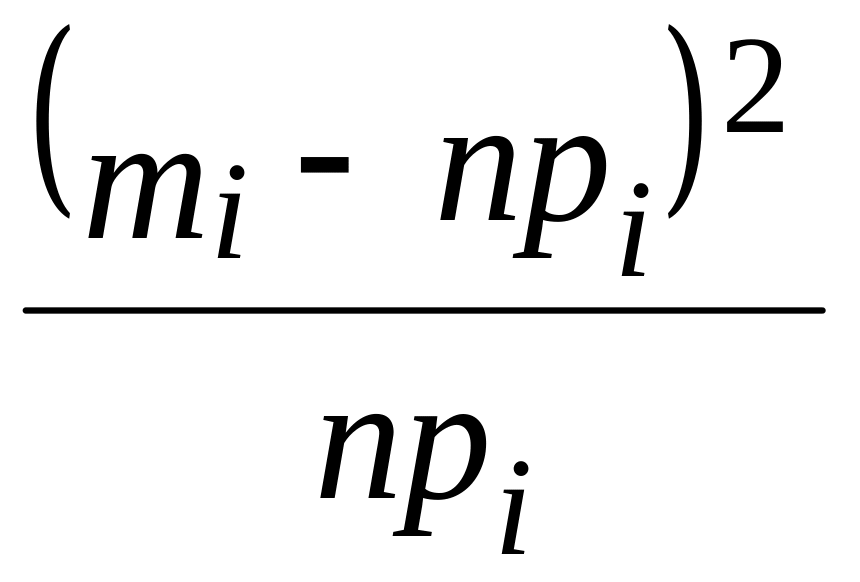
При уровне значимости 2 = 0.05 событие {χ2 > C2} не произошло (5.617 < 7.8); полученное распределение не противоречит предполагаемому.
При менее жестких требованиях, т.е. при = 0.01, событие { χ2>C1} тем более не произошло, и в этом случае можно считать, что гипотеза о распределении случайной величины с заданным законом распределения не противоречит смоделированным значениям случайной величины.
Пример 5.11. Из
выборки в 15 элементов нормальной
генеральной совокупности найдены оценки
математического ожидания
![]() = -1.5 и несмещенной дисперсии s2=
1.21. Найти точность оценки математического
ожидания и доверительный интервал,
соответствующие доверительной
вероятности =
0.98.
= -1.5 и несмещенной дисперсии s2=
1.21. Найти точность оценки математического
ожидания и доверительный интервал,
соответствующие доверительной
вероятности =
0.98.
Определить эти же величины для выборки в 40 элементов, если оценки оказались такими же.
Решение.
Истинные математическое ожидание m
и дисперсия
2
данного нормального распределения не
известны, поэтому воспользуемся формулами
= t![]() и
I
= (m*- ;
m* + )
=
и
I
= (m*- ;
m* + )
=
![]() ,
,
где – предельная ошибка,
I – доверительный интервал, соответствующий доверительной вероятности ,
t – значения квантиля распределения Стьюдента для числа степеней свободы k = n-1.
В данной задаче
число степеней свободы k
= 14, а доверительная вероятность
= 0,98.
По таблице А Приложения значение
квантилей распределения Стьюдента
находится t=2,62449.
Тогда предельная ошибка =2.62449![]() и
доверительный интервал I0.98
=(-1.5-0.75;-1.5+0.75) =
и
доверительный интервал I0.98
=(-1.5-0.75;-1.5+0.75) =
=(-2.25; -0.75). Полученный результат позволяет утверждать, что с вероятностью 0.98 математическое ожидание рассматриваемой случайной величины принадлежит интервалу (-2.25;-0.75).
При
выборке 40 элементов в связи с тем, что
с увеличением числа степеней свободы
распределение Стьюдента быстро
приближается к нормальному, воспользуемся
формулами ![]() z
для вычисления предельной ошибки
оценки математического ожидания и I
= (m* - ;
m* + )
=
z
для вычисления предельной ошибки
оценки математического ожидания и I
= (m* - ;
m* + )
=
= (m*-![]() z; m*+
z)
для вычисления доверительного интервала.
z; m*+
z)
для вычисления доверительного интервала.
В этих формулах
z
находится как корень уравнения
Ф(z) = ![]() по таблице значений нормированной
функции распределения нормального
закона (табл. В Приложения). z
называется
квантилью порядка
нормированного нормального распределения.
по таблице значений нормированной
функции распределения нормального
закона (табл. В Приложения). z
называется
квантилью порядка
нормированного нормального распределения.
Вычислив
=![]() = 0.99, входим с этим значением функции в
табл.В Приложения и находим её аргумент,
равный 2,327.
= 0.99, входим с этим значением функции в
табл.В Приложения и находим её аргумент,
равный 2,327.
Таким образом,
точность оценки =![]() ,
а доверительный интервал I0.98
= (-1.5–0.405; -1.5+0.405) = (-1.905; -1.045).
,
а доверительный интервал I0.98
= (-1.5–0.405; -1.5+0.405) = (-1.905; -1.045).
Заметим, что увеличение объема выборки существенно сузило доверительный интервал.